标签:ali 存储引擎 ted 实现 一个 star 过程 数据 height
一条查询语句的执行过程一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎:
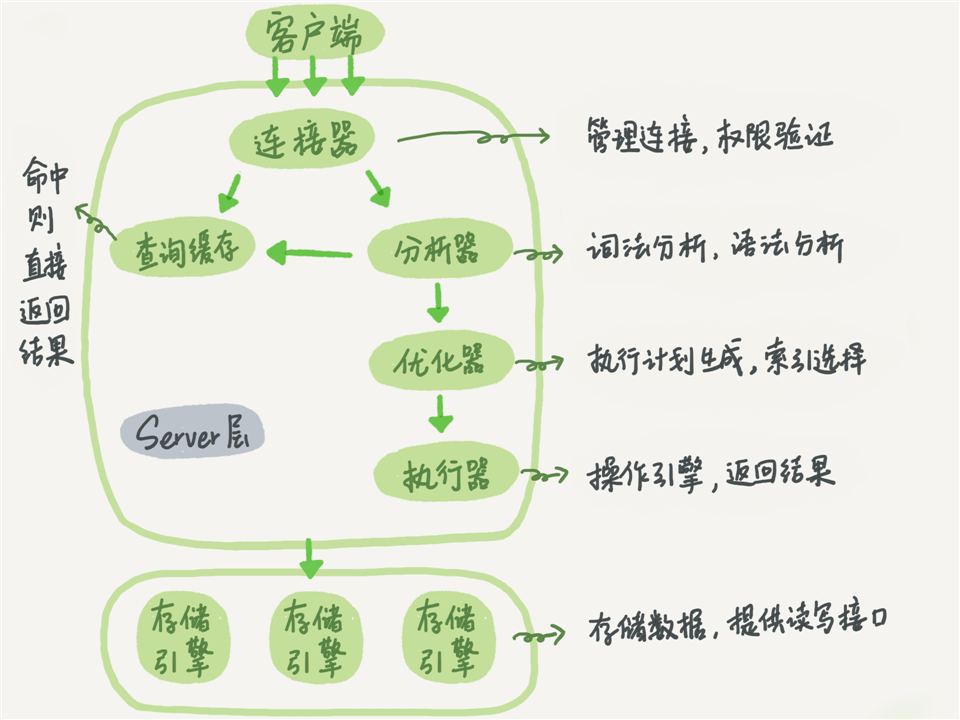
连接器连接上之后show processlist里可见,无动作在wait_timeout之后断开
查询缓存失效频繁,只要表上有更新操作则失效,除非是配置表之类的,否则不推荐打开
更新操作涉及:redo log(重做日志,InnoDB 引擎特有的日志)和 binlog(归档日志,Server 层自己的日志)
两个日志的区别:
redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
WAL: Write-Ahead Logging,它的关键点就是先写日志,再写磁盘
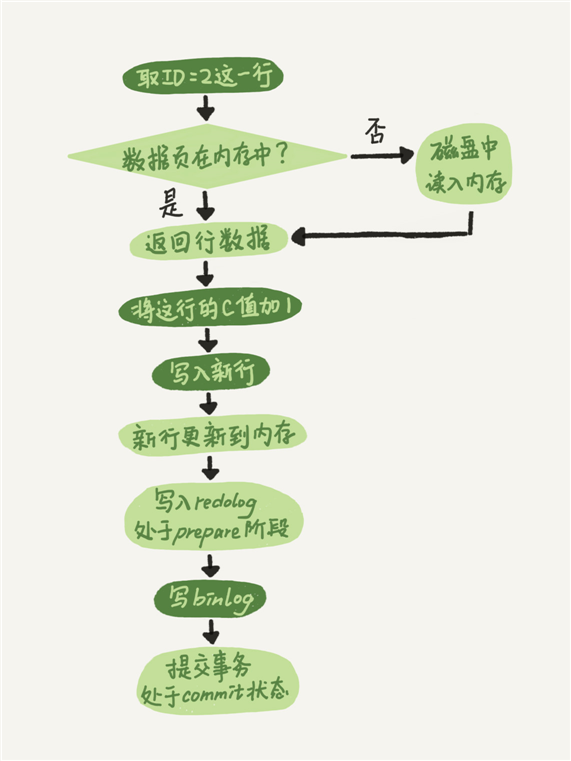
为了保证redo log 和 binlog 两个独立的逻辑的一致性,所以这里引入两阶段提交
innodb_flush_log_at_trx_commit 这个参数设置成 1 的时候,表示每次事务的 redo log 都直接持久化到磁盘,数据不丢失
sync_binlog 这个参数设置成 1 的时候,表示每次事务的 binlog 都持久化到磁盘。这个参数我也建议你设置成 1,这样可以保证 MySQL 异常重启之后 binlog 不丢失
在 MySQL 中,事务支持是在引擎层实现的
数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准
可重复读(repeatable read)~ 这个视图是在事务启动时创建的,整个事务存在期间都用这个视图
读提交(read committed) ~ 这个视图是在每个 SQL 语句开始执行的时候创建的
读未提交(read uncommitted) ~ 直接返回记录上的最新值,没有视图概念
串行化(serializable ) ~ 直接用加锁的方式来避免并行访问
实现原理:实际上每条记录在更新的时候都会同时记录一条回滚操作在回滚段中。记录上的最新值,通过回滚操作,都可以得到前一个状态的值,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)
当系统里没有比这个回滚日志更早的 read-view 的时候,回滚段回收
回滚日志是跟数据字典一起放在 ibdata 文件里的,即使长事务最终提交,回滚段被清理,文件也不会变小,最终只好为了清理回滚段,重建整个库。
寻找长事务
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
标签:ali 存储引擎 ted 实现 一个 star 过程 数据 height
原文地址:https://www.cnblogs.com/it-worker365/p/14468493.html