标签:数据存储 eve 更改 initial 相关 command 允许 集中 water
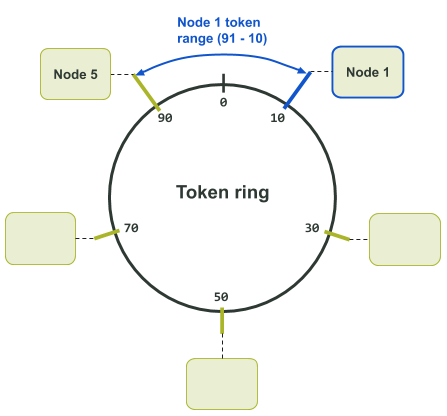
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.17 KiB 1 33.3% 8d483ae7-e7fa-4c06-9c68-22e71b78e91f rack1 UN 127.0.0.2 65.99 KiB 1 33.3% cc15803b-2b93-40f7-825f-4e7bdda327f8 rack1 UN 127.0.0.3 85.3 KiB 1 33.3% d2dd4acb-b765-4b9e-a5ac-a49ec155f666 rack1 UN 127.0.0.4 104.58 KiB 1 33.3% ad11be76-b65a-486a-8b78-ccf911db4aeb rack1 UN 127.0.0.5 71.19 KiB 1 33.3% 76234ece-bf24-426a-8def-355239e8f17b rack1 UN 127.0.0.6 30.45 KiB 1 33.3% cca81c64-d3b9-47b8-ba03-46356133401b rack1
$ ccm node1 cqlsh
Connected to SINGLETOKEN at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.9 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE test_keyspace WITH REPLICATION = { ‘class‘ : ‘NetworkTopologyStrategy‘, ‘datacenter1‘ : 3 };
cqlsh> CREATE TABLE test_keyspace.test_table (
... id int,
... value text,
... PRIMARY KEY (id));
cqlsh> CONSISTENCY LOCAL_QUORUM;
Consistency level set to LOCAL_QUORUM.
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (1, ‘foo‘);
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (2, ‘bar‘);
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (3, ‘net‘);
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (4, ‘moo‘);
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (5, ‘car‘);
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (6, ‘set‘);
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token
6148914691236517202
127.0.0.1 rack1 Up Normal 125.64 KiB 50.00% -9223372036854775808
127.0.0.2 rack1 Up Normal 125.31 KiB 50.00% -6148914691236517206
127.0.0.3 rack1 Up Normal 124.1 KiB 50.00% -3074457345618258604
127.0.0.4 rack1 Up Normal 104.01 KiB 50.00% -2
127.0.0.5 rack1 Up Normal 126.05 KiB 50.00% 3074457345618258600
127.0.0.6 rack1 Up Normal 120.76 KiB 50.00% 6148914691236517202
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
6148914691236517202 F
127.0.0.1 rack1 Up Normal 125.64 KiB 50.00% -9223372036854775808 A
127.0.0.2 rack1 Up Normal 125.31 KiB 50.00% -6148914691236517206 B
127.0.0.3 rack1 Up Normal 124.1 KiB 50.00% -3074457345618258604 C
127.0.0.4 rack1 Up Normal 104.01 KiB 50.00% -2 D
127.0.0.5 rack1 Up Normal 126.05 KiB 50.00% 3074457345618258600 E
127.0.0.6 rack1 Up Normal 120.76 KiB 50.00% 6148914691236517202 F
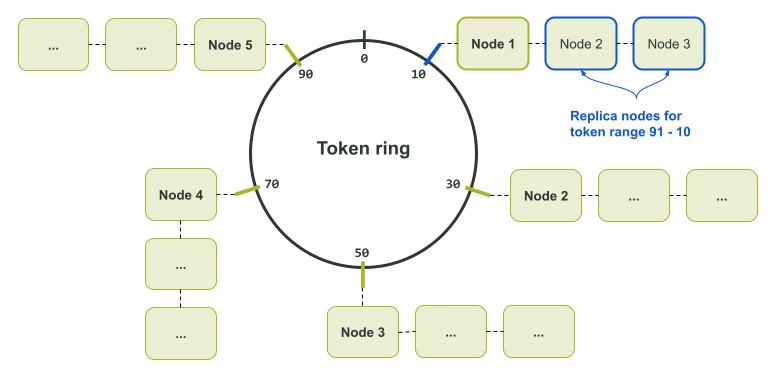
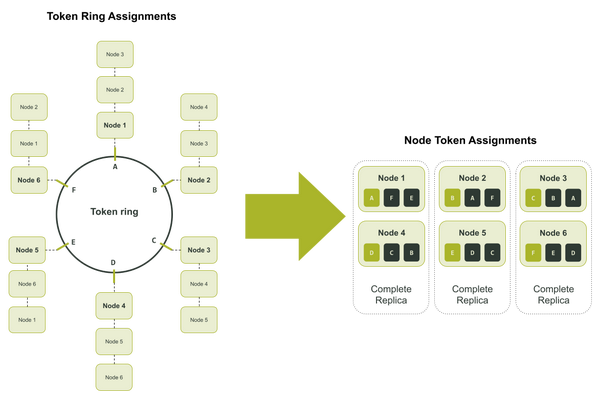
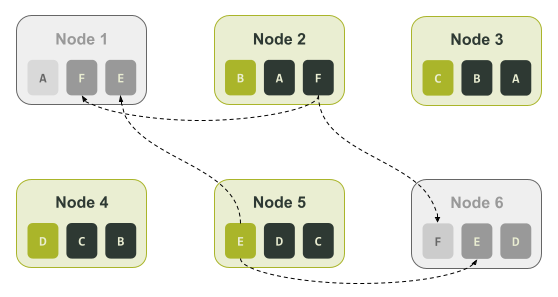
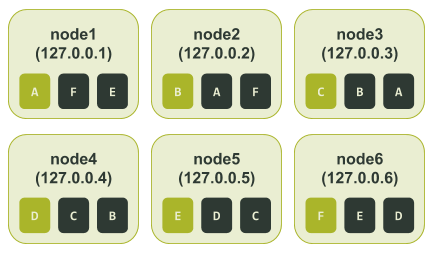
$ ccm node1 nodetool describering test_keyspace Schema Version:6256fe3f-a41e-34ac-ad76-82dba04d92c3 TokenRange: TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.4], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.3, 127.0.0.4, 127.0.0.5], rpc_endpoints:[127.0.0.3, 127.0.0.4, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.1], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:F, end_token:A, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.21 KiB 3 46.2% 7d30cbd4-8356-4189-8c94-0abe8e4d4d73 rack1 UN 127.0.0.2 66.04 KiB 3 37.5% 16bb0b37-2260-440c-ae2a-08cbf9192f85 rack1 UN 127.0.0.3 90.48 KiB 3 28.9% dc8c9dfd-cf5b-470c-836d-8391941a5a7e rack1 UN 127.0.0.4 104.64 KiB 3 20.7% 3eecfe2f-65c4-4f41-bbe4-4236bcdf5bd2 rack1 UN 127.0.0.5 66.09 KiB 3 36.1% 4d5adf9f-fe0d-49a0-8ab3-e1f5f9f8e0a2 rack1 UN 127.0.0.6 71.23 KiB 3 30.6% b41496e6-f391-471c-b3c4-6f56ed4442d6 rack1
在上面的输出结果中我们可以直观迅速地看到该集群可能已经处于失衡状态。
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
8828652533728408318 R
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% -7586808982694641609 A
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% -6737339388913371534 B
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% -5657740186656828604 C
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% -3714593062517416200 D
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% -2697218374613409116 E
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% -1044956249817882006 F
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% -877178609551551982 G
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% -852432543207202252 H
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% 117262867395611452 I
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% 762725591397791743 J
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% 1416289897444876127 K
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% 3730403440915368492 L
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% 4190414744358754863 M
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% 6904945895761639194 N
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% 7117770953638238964 O
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% 7764578023697676989 P
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% 8123167640761197831 Q
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% 8828652533728408318 R
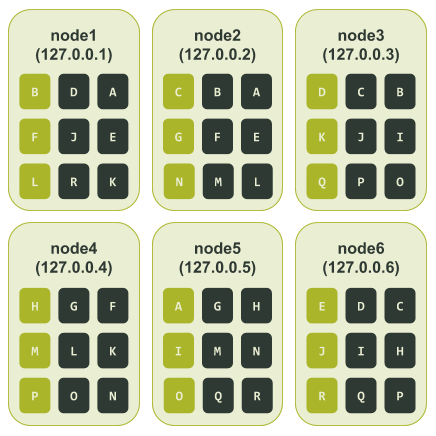
$ ccm node1 nodetool describering test_keyspace
Schema Version:4b2dc440-2e7c-33a4-aac6-ffea86cb0e21
TokenRange:
TokenRange(start_token:J, end_token:K, endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.4], rpc_endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:K, end_token:L, endpoints:[127.0.0.1, 127.0.0.4, 127.0.0.2], rpc_endpoints:[127.0.0.1, 127.0.0.4, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.4], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:I, end_token:J, endpoints:[127.0.0.6, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.6, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:R, end_token:A, endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:M, end_token:N, endpoints:[127.0.0.2, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.2, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:H, end_token:I, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:L, end_token:M, endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.5], rpc_endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:N, end_token:O, endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:P, end_token:Q, endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.5], rpc_endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:Q, end_token:R, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.1], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:F, end_token:G, endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.5], rpc_endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.1], rpc_endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:G, end_token:H, endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.6], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:O, end_token:P, endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.08 KiB 3 31.8% 49df615d-bfe5-46ce-a8dd-4748c086f639 rack1 UN 127.0.0.2 71.04 KiB 3 34.4% 3fef187e-00f5-476d-b31f-7aa03e9d813c rack2 UN 127.0.0.3 66.04 KiB 3 37.3% c6a0a5f4-91f8-4bd1-b814-1efc3dae208f rack3 UN 127.0.0.4 109.79 KiB 3 52.9% 74ac0727-c03b-476b-8f52-38c154cfc759 rack1 UN 127.0.0.5 66.09 KiB 3 18.7% 5153bad4-07d7-4a24-8066-0189084bbc80 rack2 UN 127.0.0.6 66.09 KiB 3 25.0% 6693214b-a599-4f58-b1b4-a6cf0dd684ba rack3
ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
8993942771016137629 R
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% -8459555739932651620 A
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% -8458588239787937390 B
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% -8347996802899210689 C
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% -5712162437894176338 D
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% -2744262056092270718 E
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% -2132400046698162304 F
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% -1232974565497331829 G
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% 1026323925278501795 H
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% 3093888090255198737 I
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% 3596129656253861692 J
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% 3674189467337391158 K
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% 3846303495312788195 L
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% 4699181476441710984 M
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% 6795515568417945696 N
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% 7964270297230943708 O
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% 8105847793464083809 P
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% 8813162133522758143 Q
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% 8993942771016137629 R
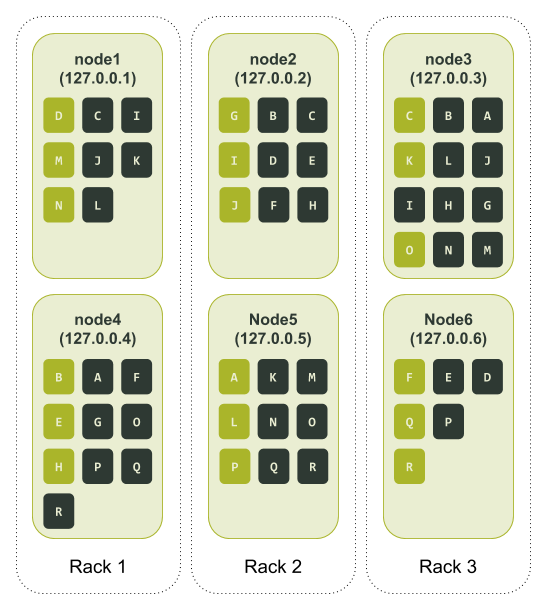
$ ccm node1 nodetool describering test_keyspace
Schema Version:aff03498-f4c1-3be1-b133-25503becf208
TokenRange:
TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:L, end_token:M, endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], rpc_endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:N, end_token:O, endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:P, end_token:Q, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:K, end_token:L, endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:R, end_token:A, endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:I, end_token:J, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:Q, end_token:R, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.6, 127.0.0.2, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.2, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:H, end_token:I, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.4, 127.0.0.6, 127.0.0.2], rpc_endpoints:[127.0.0.4, 127.0.0.6, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.2], rpc_endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.1, 127.0.0.6, 127.0.0.2], rpc_endpoints:[127.0.0.1, 127.0.0.6, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:F, end_token:G, endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:O, end_token:P, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.4], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:J, end_token:K, endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.1], rpc_endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:G, end_token:H, endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:M, end_token:N, endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], rpc_endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2)])
$ tlp-cluster init --azs a,b,c --cassandra 12 --instance i3.2xlarge --stress 1 TLP BLOG "Blogpost repair testing" $ tlp-cluster up $ tlp-cluster use --config "cluster_name:SingleToken" --config "num_tokens:1" 3.11.9 $ tlp-cluster install
Python 2.7.16 (default, Nov 23 2020, 08:01:20)
[GCC Apple LLVM 12.0.0 (clang-1200.0.30.4) [+internal-os, ptrauth-isa=sign+stri on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> num_tokens = 1
>>> num_nodes = 12
>>> print("\n".join([‘[Node {}] initial_token: {}‘.format(n + 1, ‘,‘.join([str(((2**64 / (num_tokens * num_nodes)) * (t * num_nodes + n)) - 2**63) for t in range(num_tokens)])) for n in range(num_nodes)]))
[Node 1] initial_token: -9223372036854775808
[Node 2] initial_token: -7686143364045646507
[Node 3] initial_token: -6148914691236517206
[Node 4] initial_token: -4611686018427387905
[Node 5] initial_token: -3074457345618258604
[Node 6] initial_token: -1537228672809129303
[Node 7] initial_token: -2
[Node 8] initial_token: 1537228672809129299
[Node 9] initial_token: 3074457345618258600
[Node 10] initial_token: 4611686018427387901
[Node 11] initial_token: 6148914691236517202
[Node 12] initial_token: 7686143364045646503
ubuntu@ip-172-31-19-180:~$ tlp-stress run KeyValue --replication "{‘class‘: ‘NetworkTopologyStrategy‘, ‘us-west-2‘:3 }" --cql "ALTER TABLE tlp_stress.keyvalue WITH gc_grace_seconds = 0" --reads 1 --partitions 100M --populate 100M --iterations 1
ubuntu@ip-172-31-30-95:~$ nodetool status Datacenter: us-west-2 ===================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.31.30.95 2.78 GiB 1 25.0% 6640c7b9-c026-4496-9001-9d79bea7e8e5 2a UN 172.31.31.106 2.79 GiB 1 25.0% ceaf9d56-3a62-40be-bfeb-79a7f7ade402 2a UN 172.31.2.74 2.78 GiB 1 25.0% 4a90b071-830e-4dfe-9d9d-ab4674be3507 2c UN 172.31.39.56 2.79 GiB 1 25.0% 37fd3fe0-598b-428f-a84b-c27fc65ee7d5 2b UN 172.31.31.184 2.78 GiB 1 25.0% 40b4e538-476a-4f20-a012-022b10f257e9 2a UN 172.31.10.87 2.79 GiB 1 25.0% fdccabef-53a9-475b-9131-b73c9f08a180 2c UN 172.31.18.118 2.79 GiB 1 25.0% b41ab8fe-45e7-4628-94f0-a4ec3d21f8d0 2a UN 172.31.35.4 2.79 GiB 1 25.0% 246bf6d8-8deb-42fe-bd11-05cca8f880d7 2b UN 172.31.40.147 2.79 GiB 1 25.0% bdd3dd61-bb6a-4849-a7a6-b60a2b8499f6 2b UN 172.31.13.226 2.79 GiB 1 25.0% d0389979-c38f-41e5-9836-5a7539b3d757 2c UN 172.31.5.192 2.79 GiB 1 25.0% b0031ef9-de9f-4044-a530-ffc67288ebb6 2c UN 172.31.33.0 2.79 GiB 1 25.0% da612776-4018-4cb7-afd5-79758a7b9cf8 2b
$ source env.sh $ c_all "nodetool repair -full tlp_stress"
[2021-01-22 20:20:13,952] Repair command #1 finished in 3 minutes 55 seconds [2021-01-22 20:23:57,053] Repair command #1 finished in 3 minutes 36 seconds [2021-01-22 20:27:42,123] Repair command #1 finished in 3 minutes 32 seconds [2021-01-22 20:30:57,654] Repair command #1 finished in 3 minutes 21 seconds [2021-01-22 20:34:27,740] Repair command #1 finished in 3 minutes 17 seconds [2021-01-22 20:37:40,449] Repair command #1 finished in 3 minutes 23 seconds [2021-01-22 20:41:32,391] Repair command #1 finished in 3 minutes 36 seconds [2021-01-22 20:44:52,917] Repair command #1 finished in 3 minutes 25 seconds [2021-01-22 20:47:57,729] Repair command #1 finished in 2 minutes 58 seconds [2021-01-22 20:49:58,868] Repair command #1 finished in 1 minute 58 seconds [2021-01-22 20:51:58,724] Repair command #1 finished in 1 minute 53 seconds [2021-01-22 20:54:01,100] Repair command #1 finished in 1 minute 50 seconds
ubuntu@ip-172-31-30-95:~$ nodetool status Datacenter: us-west-2 ===================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.31.30.95 2.79 GiB 256 24.3% 10b0a8b5-aaa6-4528-9d14-65887a9b0b9c 2a UN 172.31.2.74 2.81 GiB 256 24.4% a748964d-0460-4f86-907d-a78edae2a2cb 2c UN 172.31.31.106 3.1 GiB 256 26.4% 1fc68fbd-335d-4689-83b9-d62cca25c88a 2a UN 172.31.31.184 2.78 GiB 256 23.9% 8a1b25e7-d2d8-4471-aa76-941c2556cc30 2a UN 172.31.39.56 2.73 GiB 256 23.5% 3642a964-5d21-44f9-b330-74c03e017943 2b UN 172.31.10.87 2.95 GiB 256 25.4% 540a38f5-ad05-4636-8768-241d85d88107 2c UN 172.31.18.118 2.99 GiB 256 25.4% 41b9f16e-6e71-4631-9794-9321a6e875bd 2a UN 172.31.35.4 2.96 GiB 256 25.6% 7f62d7fd-b9c2-46cf-89a1-83155feebb70 2b UN 172.31.40.147 3.26 GiB 256 27.4% e17fd867-2221-4fb5-99ec-5b33981a05ef 2b UN 172.31.13.226 2.91 GiB 256 25.0% 4ef69969-d9fe-4336-9618-359877c4b570 2c UN 172.31.33.0 2.74 GiB 256 23.6% 298ab053-0c29-44ab-8a0a-8dde03b4f125 2b UN 172.31.5.192 2.93 GiB 256 25.2% 7c690640-24df-4345-aef3-dacd6643d6c0 2c
[2021-01-22 22:45:56,689] Repair command #1 finished in 4 minutes 40 seconds [2021-01-22 22:50:09,170] Repair command #1 finished in 4 minutes 6 seconds [2021-01-22 22:54:04,820] Repair command #1 finished in 3 minutes 43 seconds [2021-01-22 22:57:26,193] Repair command #1 finished in 3 minutes 27 seconds [2021-01-22 23:01:23,554] Repair command #1 finished in 3 minutes 44 seconds [2021-01-22 23:04:40,523] Repair command #1 finished in 3 minutes 27 seconds [2021-01-22 23:08:20,231] Repair command #1 finished in 3 minutes 23 seconds [2021-01-22 23:11:01,230] Repair command #1 finished in 2 minutes 45 seconds [2021-01-22 23:13:48,682] Repair command #1 finished in 2 minutes 40 seconds [2021-01-22 23:16:23,630] Repair command #1 finished in 2 minutes 32 seconds [2021-01-22 23:18:56,786] Repair command #1 finished in 2 minutes 26 seconds [2021-01-22 23:21:38,961] Repair command #1 finished in 2 minutes 30 seconds
技术基础 | 在Apache Cassandra中改变VNodes数量的影响
标签:数据存储 eve 更改 initial 相关 command 允许 集中 water
原文地址:https://www.cnblogs.com/datastax/p/14491497.html