标签:ddn 面向 调用接口 面对对象 efi 混淆 ssm 单例模式 obb
1.类的结构
class Human:
"""
此类主要是构建人类
"""
mind = ‘有思想‘ # 第一部分:静态属性 属性 静态变量 静态字段
dic = {}
l1 = []
def work(self): # 第二部分:方法 函数 动态属性
print(‘人类会工作‘)
class 是关键字与def用法相同,定义一个类。
Human是此类的类名,类名使用驼峰(CamelCase)命名风格,首字母大写,私有类可用一个下划线开头。
类的结构从大方向来说就分为两部分:
静态变量。
动态方法。
class Human:
"""
此类主要是构建人类
"""
mind = ‘有思想‘ # 第一部分:静态属性 属性 静态变量 静态字段
dic = {}
l1 = []
def work(self): # 第二部分:方法 函数 动态属性
# print(self)
print(‘人类会工作‘)
print(Human.__dict__)
print(Human.__dict__[‘mind‘])
Human.__dict__[‘mind‘] = ‘无脑‘
# 错误 通过这种方式只能查询,不能增删改.
class Human:
"""
此类主要是构建人类
"""
mind = ‘有思想‘ # 第一部分:静态属性 属性 静态变量 静态字段
dic = {}
l1 = []
def work(self): # 第二部分:方法 函数 动态属性
# print(self)
print(‘人类会工作‘)
print(Human.mind) # 查
Human.mind = ‘无脑‘ # 改
print(Human.mind)
del Human.mind # 删
Human.walk = ‘直立行走‘
print(Human.walk)
# 通过万能的点 可以增删改查类中的单个属性
如果想查询类中的所有内容,通过第一种__dict__方法,如果只是操作单个属性则用万能的点的方式
? 除了两个特殊方法:静态方法,类方法之外,一般不会通过类名操作一个类中的方法。
class Human:
"""
此类主要是构建人类
"""
mind = ‘有思想‘ # 第一部分:静态属性 属性 静态变量 静态字段
dic = {}
l1 = []
def work(self): # 第二部分:方法 函数 动态属性
# print(self)
print(‘人类会工作‘)
def tools(self):
print(‘人类会使用工具‘)
Human.work(111)
Human.tools(111)
下面可以做,但不用。
Human.__dict__[‘work‘](111)
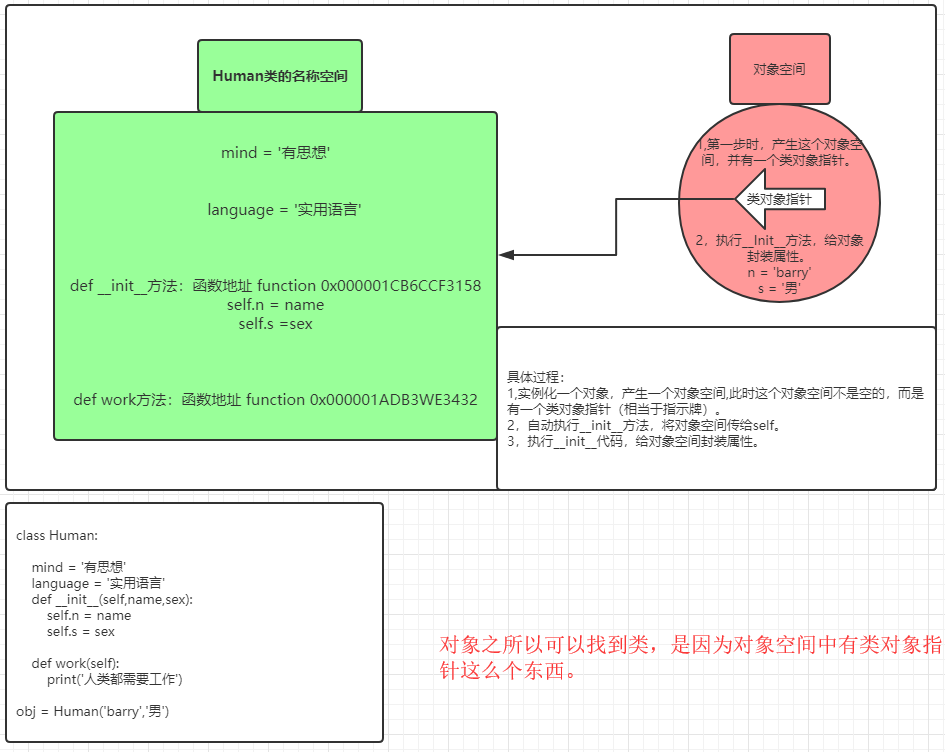
? 对象是从类中出来的,只要是类名加上(), 这就是一个实例化过程,这个就会实例化一个对象。
class Human:
mind = ‘有思想‘
def __init__(self):
print(666)
print(self) # <__main__.Human object at 0x0000012F96E06A88>
def work(self):
print(‘人类会工作‘)
def tools(self):
print(‘人类会使用工具‘)
obj = Human() # 只要实例化对象,它会自动执行__init__方法
print(obj) # <__main__.Human object at 0x0000012F96E06A88>
# 并且obj的地址与self的地址相同
实例一个对象总共发生了三件事:
1. 在内存中开辟了一个对象。
2. 自动执行类中\__init__方法,并将这个对象空间(内存地址)传给了\_\_init\_\_
方法的第一个位置参数self。
class Human:
mind = ‘有思想‘
language = ‘实用语言‘
def __init__(self,name,sex,age,hobby):
# self 和 obj 指向的是同一个内存地址同一个空间,下面就是通过self给这个对象空间封装四个属性。
self.n = name
self.s = sex
self.a = age
self.h = hobby
obj = Human(‘barry‘,‘男‘,18,‘运动‘)
print(obj.__dict__) # {‘n‘: ‘barry‘, ‘h‘: ‘运动‘, ‘s‘: ‘男‘, ‘a‘: 18}
class Human:
mind = ‘有思想‘
language = ‘实用语言‘
def __init__(self,name,sex,age,hobby):
# self 和 obj 指向的是同一个内存地址同一个空间,下面就是通过self给这个对象空间封装四个属性。
self.n = name
self.s = sex
self.a = age
self.h = hobby
obj = Human(‘barry‘,‘男‘,18,‘运动‘)
obj.job = ‘IT‘ # 增
del obj.n # 删
obj.s = ‘女‘ # 改
print(obj.s) # 女
print(obj.__dict__) # {‘s‘: ‘女‘, ‘a‘: 18, ‘h‘: ‘运动‘, ‘job‘: ‘IT‘}
class Human:
mind = ‘有思想‘
language = ‘实用语言‘
def __init__(self,name,sex,age,hobby):
self.n = name
self.s = sex
self.a = age
self.h = hobby
obj = Human(‘barry‘,‘男‘,18,‘运动‘)
print(obj.mind) # 有思想
print(obj.language) # 使用语言
obj.a = 666
print(obj.a) # 666
class Human:
mind = ‘有思想‘
language = ‘实用语言‘
def __init__(self,name,sex,age,hobby):
self.n = name
self.s = sex
self.a = age
self.h = hobby
def work(self):
print(self) # <__main__.Human object at 0x0000017A6C38F9C8>
print(‘人类会工作‘) # 人类会工作
def tools(self):
print(‘人类会使用工具‘) # 人类会使用工具
obj = Human(‘barry‘,‘男‘,18,‘运动‘)
obj.work()
obj.tools()
? 类中的方法一般都是通过对象执行的(除去类方法,静态方法外),并且对象执行这些方法都会自动将对象空间传给方法中的第一个参数self。
? self其实就是类中方法(函数)的第一个位置参数,只不过解释器会自动将调用这个函数的对象传给self。所以咱们把类中的方法的第一个参数约定俗成设置成self, 代表这个就是对象。
一个类可以实例化多个对象
obj1= Human(‘小胖‘,‘男‘,20,‘美女‘)
obj2= Human(‘相爷‘,‘男‘,18,‘肥女‘)
print(obj1,obj2)
print(obj1.__dict__)
print(obj2.__dict__)
class A:
def __init__(self,name):
self.name =name
def func(self,sex):
self.sex = sex
# 类外面可以:
obj = A(‘barry‘)
obj.age = 18
print(obj.__dict__) # {‘name‘:‘barry‘, ‘age‘: 18}
# 类内部也可以:
obj = A(‘barry‘) # __init__方法可以。
obj.func(‘男‘) # func 方法也可以
总结:对象的属性不仅可以在__init__里面添加,还可以在类的其他方法或者类的外面添加。
class A:
def __init__(self, name):
self.name = name
def func(self, sex):
self.sex = sex
def func1(self):
A.bbb = ‘ccc‘
# 类的外部可以添加
A.aaa = ‘taibai‘
print(A.__dict__)
# 类的内部也可以添加。
A.func1(111)
print(A.__dict__)
总结:类的属性不仅可以在类内部添加,还可以在类的外部添加
? 继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可以称为基类,新建的类称为派生类或子类。
python中类的继承分为:单继承和多继承
class ParentClass1: #定义父类
pass
class ParentClass2: #定义父类
pass
class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass
pass
class SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类
pass
查看继承
>>> SubClass1.__bases__ #__base__只查看从左到右继承的第一个子类,__bases__则是查看所有继承的父类
(<class ‘__main__.ParentClass1‘>,)
>>> SubClass2.__bases__
(<class ‘__main__.ParentClass1‘>, <class ‘__main__.ParentClass2‘>)
提示:如果没有指定基类,python的类会默认继承object类,object是所有python类的基类,它提供了一些常见方法(如__str__)的实现。
>>> ParentClass1.__bases__
(<class ‘object‘>,)
>>> ParentClass2.__bases__
(<class ‘object‘>,)
? 当然子类也可以添加自己新的属性或者在自己这里重新定义这些属性(不会影响到父类),需要注意的是,一旦重新定义了自己的属性且与父类重名,那么调用新增的属性时,就以自己为准了。
继承顺序
class A(object):
def test(self):
print(‘from A‘)
class B(A):
def test(self):
print(‘from B‘)
class C(A):
def test(self):
print(‘from C‘)
class D(B):
def test(self):
print(‘from D‘)
class E(C):
def test(self):
print(‘from E‘)
class F(D,E):
# def test(self):
# print(‘from F‘)
pass
f1=F()
f1.test() # from D
print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性
# (<class ‘__main__.F‘>, <class ‘__main__.D‘>, <class ‘__main__.B‘>, <class ‘__main__.E‘>, <class ‘__main__.C‘>, <class ‘__main__.A‘>, <class ‘object‘>)
#新式类继承顺序:F->D->B->E->C->A
#经典类继承顺序:F->D->B->A->E->C
#python3中统一都是新式类
#pyhon2中才分新式类与经典类
继承原理
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如
>>> F.mro() #等同于F.__mro__
[<class ‘__main__.F‘>, <class ‘__main__.D‘>, <class ‘__main__.B‘>, <class ‘__main__.E‘>, <class ‘__main__.C‘>, <class ‘__main__.A‘>, <class ‘object‘>]
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
继承的作用
多态是指一类事物有多种形态
动物的多种形态:人,狗,猪
import abc
class Animal(metaclass=abc.ABCMeta): #同一类事物:动物
@abc.abstractmethod
def talk(self):
pass
class People(Animal): #动物的形态之一:人
def talk(self):
print(‘say hello‘)
class Dog(Animal): #动物的形态之二:狗
def talk(self):
print(‘say wangwang‘)
class Pig(Animal): #动物的形态之三:猪
def talk(self):
print(‘say aoao‘)
文件的多种形态:文本文件,可执行文件
import abc
class File(metaclass=abc.ABCMeta): #同一类事物:文件
@abc.abstractmethod
def click(self):
pass
class Text(File): #文件的形态之一:文本文件
def click(self):
print(‘open file‘)
class ExeFile(File): #文件的形态之二:可执行文件
def click(self):
print(‘execute file‘)
鸭子类型
Python崇尚鸭子类型,即‘如果看起来像、叫声像而且走起路来像鸭子,那么它就是鸭子,python程序员通常根据这种行为来编写程序。例如,如果想编写现有对象的自定义版本,可以继承该对象,也可以创建一个外观和行为像,但与它无任何关系的全新对象,后者通常用于保存程序组件的松耦合度。
例1:利用标准库中定义的各种‘与文件类似’的对象,尽管这些对象的工作方式像文件,但他们没有继承内置文件对象的方法
例2:序列类型有多种形态:字符串,列表,元组,但他们直接没有直接的继承关系
#二者都像鸭子,二者看起来都像文件,因而就可以当文件一样去用
class TxtFile:
def read(self):
pass
def write(self):
pass
class DiskFile:
def read(self):
pass
def write(self):
pass
封装:隐藏对象的属性和实现细节,仅对外提供公共访问方式。
好处:
封装原则:
#其实这仅仅这是一种变形操作
#类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式:
class A:
__N=0 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N
def __init__(self):
self.__X=10 #变形为self._A__X
def __foo(self): #变形为_A__foo
print(‘from A‘)
def bar(self):
self.__foo() #只有在类内部才可以通过__foo的形式访问到.
#A._A__N是可以访问到的,即这种操作并不是严格意义上的限制外部访问,仅仅只是一种语法意义上的变形
这种自动变形的特点:
类中定义的__x只能在内部使用,如self.__x,引用的就是变形的结果。
这种变形其实正是针对外部的变形,在外部是无法通过__x这个名字访问到的。
在子类定义的__x不会覆盖在父类定义的__x,因为子类中变形成了:_子类名__x,而父类中变形成了:_父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的。
这种变形需要注意的问题是:
1.这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如a._A__N
2.变形的过程只在类的内部生效,在定义后的赋值操作,不会变形
私有方法
#正常情况
>>> class A:
... def fa(self):
... print(‘from A‘)
... def test(self):
... self.fa()
...
>>> class B(A):
... def fa(self):
... print(‘from B‘)
...
>>> b=B()
>>> b.test()
from B
#把fa定义成私有的,即__fa
>>> class A:
... def __fa(self): #在定义时就变形为_A__fa
... print(‘from A‘)
... def test(self):
... self.__fa() #只会与自己所在的类为准,即调用_A__fa
...
>>> class B(A):
... def __fa(self):
... print(‘from B‘)
...
>>> b=B()
>>> b.test()
from A
封装在于明确区分内外,使得类实现者可以修改封装内的东西而不影响外部调用者的代码;而外部使用用者只知道一个接口(函数),只要接口(函数)名、参数不变,使用者的代码永远无需改变。这就提供一个良好的合作基础——或者说,只要接口这个基础约定不变,则代码改变不足为虑。
#类的设计者
class Room:
def __init__(self,name,owner,width,length,high):
self.name=name
self.owner=owner
self.__width=width
self.__length=length
self.__high=high
def tell_area(self): #对外提供的接口,隐藏了内部的实现细节,此时我们想求的是面积
return self.__width * self.__length
#使用者
>>> r1=Room(‘卧室‘,‘egon‘,20,20,20)
>>> r1.tell_area() #使用者调用接口tell_area
#类的设计者,轻松的扩展了功能,而类的使用者完全不需要改变自己的代码
class Room:
def __init__(self,name,owner,width,length,high):
self.name=name
self.owner=owner
self.__width=width
self.__length=length
self.__high=high
def tell_area(self): #对外提供的接口,隐藏内部实现,此时我们想求的是体积,内部逻辑变了,只需求修该下列一行就可以很简答的实现,而且外部调用感知不到,仍然使用该方法,但是功能已经变了
return self.__width * self.__length * self.__high
#对于仍然在使用tell_area接口的人来说,根本无需改动自己的代码,就可以用上新功能
>>> r1.tell_area()
class A:
company_name = ‘老男孩教育‘ # 静态变量(静态字段)
__iphone = ‘1353333xxxx‘ # 私有静态变量(私有静态字段)
def __init__(self,name,age): #特殊方法
self.name = name #对象属性(普通字段)
self.__age = age # 私有对象属性(私有普通字段)
def func1(self): # 普通方法
pass
def __func(self): #私有方法
print(666)
@classmethod # 类方法
def class_func(cls):
""" 定义类方法,至少有一个cls参数 """
print(‘类方法‘)
@staticmethod #静态方法
def static_func():
""" 定义静态方法 ,无默认参数"""
print(‘静态方法‘)
@property # 属性
def prop(self):
pass
对于每一个类的成员而言都有两种形式:
私有成员和公有成员的访问限制不同:
静态字段(静态属性)
class C:
name = "公有静态字段"
def func(self):
print(C.name)
class D(C):
def show(self):
print(C.name)
C.name # 类访问
obj = C()
obj.func() # 类内部可以访问
obj_son = D()
obj_son.show() # 派生类中可以访问
class C:
__name = "私有静态字段"
def func(self):
print(C.__name)
class D(C):
def show(self):
print(C.__name)
C.__name # 不可在外部访问
obj = C()
obj.__name # 不可在外部访问
obj.func() # 类内部可以访问
obj_son = D()
obj_son.show() #不可在派生类中可以访问
普通字段(对象属性)
class C:
def __init__(self):
self.foo = "公有字段"
def func(self):
print(self.foo ) # 类内部访问
class D(C):
def show(self):
print(self.foo) # 派生类中访问
obj = C()
obj.foo # 通过对象访问
obj.func() # 类内部访问
obj_son = D();
obj_son.show() # 派生类中访问
class C:
def __init__(self):
self.__foo = "私有字段"
def func(self):
print(self.foo) # 类内部访问
class D(C):
def show(self):
print(self.foo) # 派生类中访问
obj = C()
obj.__foo # 通过对象访问 ==> 错误
obj.func() # 类内部访问 ==> 正确
obj_son = D();
obj_son.show() # 派生类中访问 ==> 错误
方法:
class C:
def __init__(self):
pass
def add(self):
print(‘in C‘)
class D(C):
def show(self):
print(‘in D‘)
def func(self):
self.show()
obj = D()
obj.show() # 通过对象访问
obj.func() # 类内部访问
obj.add() # 派生类中访问
class C:
def __init__(self):
pass
def __add(self):
print(‘in C‘)
class D(C):
def __show(self):
print(‘in D‘)
def func(self):
self.__show()
obj = D()
obj.__show() # 通过不能对象访问
obj.func() # 类内部可以访问
obj.__add() # 派生类中不能访问
总结:
对于这些私有成员来说,他们只能在类的内部使用,不能再类的外部以及派生类中使用.
ps:非要访问私有成员的话,可以通过 对象._类__属性名,但是绝对不允许!!!
为什么可以通过._类__私有成员名访问呢?因为类在创建时,如果遇到了私有成员(包括私有静态字段,私有普通字段,私有方法)它会将其保存在内存时自动在前面加上_类名.
这里的其他成员主要就是类方法:
方法包括:普通方法、静态方法和类方法,三种方法在内存中都归属于类,区别在于调用方式不同。
实例方法
定义:第一个参数必须是实例对象,该参数名一般约定为“self”,通过它来传递实例的属性和方法(也可以传类的属性和方法);
调用:只能由实例对象调用。
类方法
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为“cls”,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:实例对象和类对象都可以调用。
静态方法
定义:使用装饰器@staticmethod。参数随意,没有“self”和“cls”参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:实例对象和类对象都可以调用。
双下方法
定义:双下方法是特殊方法,他是解释器提供的 由爽下划线加方法名加爽下划线 __方法名__的具有特殊意义的方法,双下方法主要是python源码程序员使用的,在开发中尽量不要使用双下方法,但是深入研究双下方法,更有益于我们阅读源码。
调用:不同的双下方法有不同的触发方式,就好比盗墓时触发的机关一样,不知不觉就触发了双下方法,例如:__init__
使用装饰器@classmethod。
原则上,类方法是将类本身作为对象进行操作的方法。假设有个方法,且这个方法在逻辑上采用类本身作为对象来调用更合理,那么这个方法就可以定义为类方法。另外,如果需要继承,也可以定义为类方法。
如下场景:
假设我有一个学生类和一个班级类,想要实现的功能为:
执行班级人数增加的操作、获得班级的总人数;
学生类继承自班级类,每实例化一个学生,班级人数都能增加;
最后,我想定义一些学生,获得班级中的总人数。
思考:这个问题用类方法做比较合适,为什么?因为我实例化的是学生,但是如果我从学生这一个实例中获得班级总人数,在逻辑上显然是不合理的。同时,如果想要获得班级总人数,如果生成一个班级的实例也是没有必要的。
class Student:
__num = 0
def __init__(self,name,age):
self.name = name
self.age= age
Student.addNum() # 写在__new__方法中比较合适,但是现在还没有学,暂且放到这里
@classmethod
def addNum(cls):
cls.__num += 1
@classmethod
def getNum(cls):
return cls.__num
a = Student(‘世界‘, 18)
b = Student(‘徐斌‘, 36)
c = Student(‘肖sir‘, 73)
print(Student.getNum())
使用装饰器@staticmethod。
静态方法是类中的函数,不需要实例。静态方法主要是用来存放逻辑性的代码,逻辑上属于类,但是和类本身没有关系,也就是说在静态方法中,不会涉及到类中的属性和方法的操作。可以理解为,静态方法是个独立的、单纯的函数,它仅仅托管于某个类的名称空间中,便于使用和维护。
譬如,我想定义一个关于时间操作的类,其中有一个获取当前时间的函数。
import time
class TimeTest(object):
def __init__(self, hour, minute, second):
self.hour = hour
self.minute = minute
self.second = second
@staticmethod
def showTime():
return time.strftime("%H:%M:%S", time.localtime())
print(TimeTest.showTime())
t = TimeTest(2, 10, 10)
nowTime = t.showTime()
print(nowTime)
property是一种特殊的属性,访问他会执行一段功能(函数)然后返回值
class People:
def __init__(self,name,weight,height):
self.name=name
self.weight=weight
self.height=height
@property
def bmi(self):
return self.weight / (self.height**2)
p1=People(‘egon‘,75,1.85)
print(p1.bmi)
将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则
由于新式类中具有三种访问方式,我们可以根据他们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
class Foo:
@property
def AAA(self):
print(‘get的时候运行我啊‘)
@AAA.setter
def AAA(self,value):
print(‘set的时候运行我啊‘)
@AAA.deleter
def AAA(self):
print(‘delete的时候运行我啊‘)
#只有在属性AAA定义property后才能定义AAA.setter,AAA.deleter
f1=Foo()
f1.AAA
f1.AAA=‘aaa‘
del f1.AAA
或者:
class Foo:
def get_AAA(self):
print(‘get的时候运行我啊‘)
def set_AAA(self,value):
print(‘set的时候运行我啊‘)
def delete_AAA(self):
print(‘delete的时候运行我啊‘)
AAA=property(get_AAA,set_AAA,delete_AAA) #内置property三个参数与get,set,delete一一对应
f1=Foo()
f1.AAA
f1.AAA=‘aaa‘
del f1.AAA
class Goods(object):
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
@property
def price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
@price.setter
def price(self,value):
self.original_price = value
print(self.original_price)
@price.deleter
def price(self):
del self.original_price
print(‘hahah‘)
obj = Goods()
obj.price # 获取商品价格
obj.price = 200 # 修改商品原价
del obj.price # 删除商品原价
反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力(自省)。这一概念的提出很快引发了计算机科学领域关于应用反射性的研究。它首先被程序语言的设计领域所采用,并在Lisp和面向对象方面取得了成绩。
python面向对象中的反射:通过字符串的形式操作对象相关的属性。python中的一切事物都是对象(都可以使用反射)
四个可以实现自省的函数
下列方法适用于类和对象(一切皆对象,类本身也是一个对象)
class Foo:
f = ‘类的静态变量‘
def __init__(self,name,age):
self.name=name
self.age=age
def say_hi(self):
print(‘hi,%s‘%self.name)
obj=Foo(‘egon‘,73)
#检测是否含有某属性
print(hasattr(obj,‘name‘)) # True
print(hasattr(obj,‘say_hi‘)) # True
#获取属性
n=getattr(obj,‘name‘)
print(n) # egon
func=getattr(obj,‘say_hi‘)
func() # hi,egon
print(getattr(obj,‘aaaaaaaa‘,‘不存在啊‘)) # 报错
#
# #设置属性
setattr(obj,‘sb‘,True)
setattr(obj,‘show_name‘,lambda self:self.name+‘sb‘)
print(obj.__dict__)
print(obj.show_name(obj))
#
# #删除属性
delattr(obj,‘age‘)
delattr(obj,‘show_name‘)
delattr(obj,‘show_name111‘)#不存在,则报错
print(obj.__dict__)
反射的应用:
了解了反射的四个函数。那么反射到底有什么用呢?它的应用场景是什么呢?
现在让我们打开浏览器,访问一个网站,你单击登录就跳转到登录界面,你单击注册就跳转到注册界面,等等,其实你单击的其实是一个个的链接,每一个链接都会有一个函数或者方法来处理。
class User:
def login(self):
print(‘欢迎来到登录页面‘)
def register(self):
print(‘欢迎来到注册页面‘)
def save(self):
print(‘欢迎来到存储页面‘)
while 1:
choose = input(‘>>>‘).strip()
if choose == ‘login‘:
obj = User()
obj.login()
elif choose == ‘register‘:
obj = User()
obj.register()
elif choose == ‘save‘:
obj = User()
obj.save()
用反射
class User:
def login(self):
print(‘欢迎来到登录页面‘)
def register(self):
print(‘欢迎来到注册页面‘)
def save(self):
print(‘欢迎来到存储页面‘)
user = User()
while 1:
choose = input(‘>>>‘).strip()
if hasattr(user,choose):
func = getattr(user,choose)
func()
else:
print(‘输入错误。。。。‘)
单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
【采用单例模式动机、原因】
对于系统中的某些类来说,只有一个实例很重要,例如,一个系统中可以存在多个打印任务,但是只能有一个正在工作的任务;一个系统只能有一个窗口管理器或文件系统;一个系统只能有一个计时工具或ID(序号)生成器。如在Windows中就只能打开一个任务管理器。如果不使用机制对窗口对象进行唯一化,将弹出多个窗口,如果这些窗口显示的内容完全一致,则是重复对象,浪费内存资源;如果这些窗口显示的内容不一致,则意味着在某一瞬间系统有多个状态,与实际不符,也会给用户带来误解,不知道哪一个才是真实的状态。因此有时确保系统中某个对象的唯一性即一个类只能有一个实例非常重要。
如何保证一个类只有一个实例并且这个实例易于被访问呢?定义一个全局变量可以确保对象随时都可以被访问,但不能防止我们实例化多个对象。一个更好的解决办法是让类自身负责保存它的唯一实例。这个类可以保证没有其他实例被创建,并且它可以提供一个访问该实例的方法。这就是单例模式的模式动机。
【单例模式优缺点】
【优点】
一、实例控制
单例模式会阻止其他对象实例化其自己的单例对象的副本,从而确保所有对象都访问唯一实例。
二、灵活性
因为类控制了实例化过程,所以类可以灵活更改实例化过程。
【缺点】
一、开销
虽然数量很少,但如果每次对象请求引用时都要检查是否存在类的实例,将仍然需要一些开销。可以通过使用静态初始化解决此问题。
二、可能的开发混淆
使用单例对象(尤其在类库中定义的对象)时,开发人员必须记住自己不能使用new关键字实例化对象。因为可能无法访问库源代码,因此应用程序开发人员可能会意外发现自己无法直接实例化此类。
三、对象生存期
不能解决删除单个对象的问题。在提供内存管理的语言中(例如基于.NET Framework的语言),只有单例类能够导致实例被取消分配,因为它包含对该实例的私有引用。在某些语言中(如 C++),其他类可以删除对象实例,但这样会导致单例类中出现悬浮引用
class A:
def __init__(self):
self.x = 1
print(‘in init function‘)
def __new__(cls, *args, **kwargs):
print(‘in new function‘)
return object.__new__(A, *args, **kwargs)
a = A()
print(a.x)
class A:
__instance = None
def __new__(cls, *args, **kwargs):
if cls.__instance is None:
obj = object.__new__(cls)
cls.__instance = obj
return cls.__instance
class Singleton:
def __new__(cls, *args, **kw):
if not hasattr(cls, ‘_instance‘):
cls._instance = object.__new__(cls)
return cls._instance
one = Singleton()
two = Singleton()
two.a = 3
print(one.a)
# 3
# one和two完全相同,可以用id(), ==, is检测
print(id(one))
# 29097904
print(id(two))
# 29097904
print(one == two)
# True
print(one is two)
标签:ddn 面向 调用接口 面对对象 efi 混淆 ssm 单例模式 obb
原文地址:https://www.cnblogs.com/shijiekuaile/p/14495774.html