标签:fun 练习 round mic isp 初始 报错 替换 使用
<!doctype html>
把一些常用的函数放在一个py文件中,这个文件就称之为模块,模块,就是一些列常用功能的集合体
1)通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用
2)拿来主义,提升开发效率
内置模块:也叫做标准库。此类模块就是python解释器给你提供的,比如我们之前见过的time模块,os模块。标准库的模块非常多(200多个,每个模块又有很多功能)
第三方模块:一些python大神写的非常好用的模块,必须通过pip install 指令安装的模块,比如BeautfulSoup, Django等。大概有6000多个
自定义模块:自己在项目中定义的一些模块
x
# 文件名: abcd.py?print(‘from the abcd.py‘)?def read1(): print(‘abcd模块:‘, name)?def read2(): print(‘abcd模块‘) read1()?def change(): global name name = ‘barry‘当我引用abcd模块的时候,实际上将abcd.py执行一遍,加载到内存.
import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句
xxxxxxxxxximport abcdimport abcdimport abcdimport abcdimport abcd‘‘‘from the abcd.py‘‘‘1)创建一个以模块名命名的名称空间。
2)执行这个名称空间(即导入的模块)里面的代码。
3)通过此模块名. 的方式引用该模块里面的内容(变量,函数名,类名等)
ps:重复导入会直接引用内存中已经加载好的结果
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
1)可以将很长的模块名改成很短,方便使用
xxxxxxxxxximport abcd as tbprint(tb.name)2)有利于代码的扩展和优化
xxxxxxxxxx# mysql_.pydef sqlprase(): print(‘连接mysql数据库‘)xxxxxxxxxx# oracle_.pydef sqlprase(): print(‘连接oracle数据库‘)xxxxxxxxxxcontent = input(‘>>>‘).strip()if content == ‘mysql‘: import mysql_ mysql_.sqlprase()elif content == ‘oracle‘: import oracle_ oracle_.sqlprase()?# -------------------------------# 统一化接口content = input(‘>>>‘).strip()?if content == ‘mysql‘: import mysql_ as dbelif content == ‘oracle‘: import oracle_ as db?db.sqlprase()?xxxxxxxxxx# 引入多个模块import time,os,sys # 不推荐.?# 推荐:多行导入:易于阅读 易于编辑 易于搜索 易于维护import timeimport osimport sysxxxxxxxxxxfrom abcd import namefrom abcd import read1?# 相当于从abcd模块的全局空间中将name,read1变量与值的对应关系复制到当前执行文件的全局名称空间中.print(globals())?print(name) # 运维人在路上read1() # abcd模块: 运维人在路上?# 优点:使用起来方便了.# 缺点:容易与当前执行文件产生覆盖效果.使用from...import...则是将模块中的名字直接导入到当前的名称空间中,所以在当前名称空间中,直接使用名字就可以了、无需加前缀
好处:使用方便
缺点:执行文件有与模块同名的变量或者函数名,会有覆盖效果
xxxxxxxxxxfrom bacd import read1,read2,namefrom 模块 import * :把模块中所有的不是以下划线(_)开头的名字都导入到当前位置,不推荐使用这种导入方式
xxxxxxxxxx# from ... import * 尽量别单独用from abcd import *print(name)read1()read2()# 1、全部将abcd的所有名字复制过来,无用功.# 2、容易覆盖.# 3、from ... import * 与__all__配合使用(写在模块文件中)序列化:将一个常见的数据结构转化成一个特殊的序列,并且这个特殊的序列还可以反解回去。
主要用途:文件读写数据,网络传输数据
json序列化只支持部分Python数据结构:dict,list, tuple,str,int, float,True,False,None
json模块是将满足条件的数据结构转化成特殊的字符串,并且也可以反序列化还原回去。
json主要有两对4个方法:
dumps、loadsdump、load1)dumps、loads
xxxxxxxxxx# 序列化:将一个字典转换成一个字符串str_dic = json.dumps(dic)# 注意,json转换完的字符串类型的字典中的字符串是由""表示的print(type(str_dic), str_dic) # <class ‘str‘> {"k1": "v1", "k2": "v2", "k3": "v3"}??# 反序列化:将一个字符串格式的字典转换成一个字典dic2 = json.loads(str_dic)# 注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示print(type(dic2), dic2) # <class ‘dict‘> {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}?# 也可以处理嵌套的数据类型list_dic = [1, [‘a‘, ‘b‘, ‘c‘], 3, {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘}]str_dic = json.dumps(list_dic)print(type(str_dic), str_dic) # <class ‘str‘> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]list_dic2 = json.loads(str_dic)print(type(list_dic2), list_dic2) # <class ‘list‘> [1, [‘a‘, ‘b‘, ‘c‘], 3, {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘}]特殊参数:
xxxxxxxxxxdic = {‘username‘: ‘运维人在路上‘, ‘password‘: 123, ‘status‘: False}print(dic) ret = json.dumps(dic)print(ret, type(ret)) # {"username": "\u8fd0\u7ef4\u4eba\u5728\u8def\u4e0a", "password": 123, "status": false} <class ‘str‘>ret = json.dumps(dic, ensure_ascii=False, sort_keys=True)print(ret, type(ret)) # {"password": 123, "status": false, "username": "运维人在路上"} <class ‘str‘>?# -----------------------------------------------------ensure_ascii:当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。 sort_keys:将数据根据keys的值进行排序需求:将字典写入文件并读出
xxxxxxxxxximport json?dic = {‘username‘: ‘运维人在路上‘, ‘password‘: 123, ‘status‘: False}s_dict = json.dumps(dic)with open(‘jsonlx.json‘, encoding=‘utf-8‘, mode=‘w‘) as f1: f1.write(s_dict)?with open(‘jsonlx.json‘, encoding=‘utf-8‘) as f2: content = f2.read() print(json.loads(content))2)dump、load
单个数据的存取文件
xxxxxxxxxximport json?dic = {‘username‘: ‘运维人在路上‘, ‘password‘: 123, ‘status‘: False}with open(‘jsonlx1.json‘, encoding=‘utf-8‘, mode=‘w‘) as f1: json.dump(dic, f1)?with open(‘jsonlx1.json‘, encoding=‘utf-8‘) as f1: dic1 = json.load(f1)?print(dic1, type(dic1))pickle模块是将Python所有的数据结构以及对象等转化成bytes类型,然后还可以反序列化还原回去
使用上与json几乎差不多,也是两对四个方法:
dumps、loadsdump、load1)dumps、loads
xxxxxxxxxximport pickle?dic = {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}str_dic = pickle.dumps(dic)print(str_dic) # bytes类型 ?dic2 = pickle.loads(str_dic)print(dic2) # 字典 {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}?# ------------------------------------------------------------# 还可以序列化对象def func(): print(666)??ret = pickle.dumps(func)print(ret, type(ret)) # b‘\x80\x03c__main__\nfunc\nq\x00.‘ <class ‘bytes‘>f1 = pickle.loads(ret) # f1得到 func函数的内存地址f1() # 执行func函数2)dump、load
xxxxxxxxxx# dump load 数据结构存取文件.import pickle?l1 = [‘wusir‘, ‘太白‘, ‘小黑‘, 666]with open(‘pickle练习.pickle‘, mode=‘wb‘) as f1: pickle.dump(l1, f1)?with open(‘pickle练习.pickle‘, mode=‘rb‘) as f1: ret = pickle.load(f1) print(ret, type(ret))xxxxxxxxxx# 多个数据写入文件l1 = [‘wusir‘, ‘太白‘, ‘小黑1‘, 666]l2 = [‘wusir‘, ‘太白‘, ‘小黑2‘, 666]l3 = [‘wusir‘, ‘太白‘, ‘小黑3‘, 666]with open(‘pickle1.pickle‘, mode=‘wb‘) as f1: pickle.dump(l1, f1) pickle.dump(l2, f1) pickle.dump(l3, f1)?with open(‘pickle1.pickle‘, mode=‘rb‘) as f1: ret1 = pickle.load(f1) ret2 = pickle.load(f1) ret3 = pickle.load(f1) print(ret1, ret2, ret3)xxxxxxxxxximport os?# 与路径相关print(os.getcwd()) # 绝对路径os.chdir(r‘D:\python学习‘)print(os.getcwd()) # D:\python学习print(os.curdir) # .print(os.pardir) # ..print("=============================")?# 和文件夹相关os.makedirs(‘dirname1/dirname2/dirname3/dirname4‘) # 多级目录os.removedirs(‘dirname1/dirname2/dirname3/dirname4‘) # 删除截止到有文件的那层os.mkdir(r‘d:\abc‘) # 单级目录os.rmdir(r‘d:\abc‘)print(os.listdir(r‘D:\python学习‘))?# 文件相关os.remove() # 删除一个文件os.rename("oldname", "newname") # 重命名文件/目录print(os.stat(r‘D:\python学习\os模块.py‘))?# path 和路径相关print(os.path.abspath(‘04 os模块.py‘)) # D:\s23\day17\04 os模块.pyprint(os.path.split(os.path.abspath(‘01 昨日内容回顾.py‘))) # (‘D:\\s23\\day17‘, ‘01 昨日内容回顾.py‘)print(os.path.dirname(r‘D:\s23\day9\01 初始函数.py‘)) # 获取父级目录print(os.path.dirname(os.path.abspath(‘01 昨日内容回顾.py‘)))print(__file__) # 动态获取当前文件的绝对路径?# 获取当前文件的爷爷级的目录print(os.path.dirname(os.path.dirname(__file__)))print(os.path.basename(r‘D:\s23\day9\01 初始函数.py‘)) # 获取文件名print(os.path.exists(r‘D:\s23\day9\02 初始函数.py‘))?# 判断是否是绝对路径print(os.path.isabs(r‘D:\s23\day9\01 初始函数.py‘))print(os.path.isabs(r‘day17/01 昨日内容回顾.py‘))?# 判断该路径是否是一个文件路径print(os.path.isfile(r‘D:\s23\day9\01 初始函数.py‘))print(os.path.isfile(r‘D:\s23\day9‘))print(os.path.isdir(r‘D:\s23\day17\dirname1\dirname2‘))print(os.path.exists(r‘D:\s23\day17\dirname1\dirname2‘))?# 判断是否是一个目录(文件夹)print(os.path.isdir(r‘D:\s23\day17\02 序列化模块.py‘))# D:\s23\day16\评论文章path = os.path.join(‘D:‘,‘s23‘,‘day20‘,‘随便‘)print(path)?# ======================================================当前执行这个python文件的工作目录相关的工作路径os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 ** os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd **os.curdir 返回当前目录: (‘.‘) **os.pardir 获取当前目录的父目录字符串名:(‘..‘) **?# 和文件夹相关 os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 ***os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 ***os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname ***os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname ***# os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 **?# 和文件相关os.remove() 删除一个文件 ***os.rename("oldname","newname") 重命名文件/目录 ***os.stat(‘path/filename‘) 获取文件/目录信息 **?# 和操作系统差异相关# os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" *# os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" *# os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: *# os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ *# 和执行系统命令相关# os.system("bash command") 运行shell命令,直接显示 **# os.popen("bash command).read() 运行shell命令,获取执行结果 **os.environ 获取系统环境变量 **?#path系列,和路径相关os.path.abspath(path) 返回path规范化的绝对路径 ***os.path.split(path) 将path分割成目录和文件名二元组返回 ***os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 **os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素。 **os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False ***os.path.isabs(path) 如果path是绝对路径,返回True **os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False ***os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False ***os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 ***os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 **os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 **os.path.getsize(path) 返回path的大小 ***注意:os.stat(‘path/filename‘) 获取文件/目录信息 的结构说明
xxxxxxxxxx# stat 结构:st_mode: inode 保护模式st_ino: inode 节点号。st_dev: inode 驻留的设备。st_nlink: inode 的链接数。st_uid: 所有者的用户ID。st_gid: 所有者的组ID。st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。st_atime: 上次访问的时间。st_mtime: 最后一次修改的时间。st_ctime: 操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间)xxxxxxxxxxsys.argv # 命令行参数List,第一个元素是程序本身路径sys.exit() # 退出程序,正常退出时exit(0),错误退出sys.exit(1)sys.version # 获取Python解释程序的版本信息sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 ***sys.platform # 返回操作系统平台名称,不准此模块称为摘要算法,也叫做加密算法,或者是哈希算法,散列算法
通过一个函数,把任意长度的数据按照一定规则转换为一个固定长度的数据串(通常用16进制的字符串表示),用于加密解密
hashlib的特征:
hashlib主要用途:
xxxxxxxxxx# md5加密ret = hashlib.md5()ret.update(‘123‘.encode(‘utf-8‘))s = ret.hexdigest()print(s, type(s)) # 202cb962ac59075b964b07152d234b70 <class ‘str‘>?ret = hashlib.md5()ret.update(‘123‘.encode(‘utf-8‘))s = ret.hexdigest()print(s, type(s)) # 202cb962ac59075b964b07152d234b70 <class ‘str‘>?ret = hashlib.md5()ret.update(‘223‘.encode(‘utf-8‘))s = ret.hexdigest()print(s, type(s)) # 115f89503138416a242f40fb7d7f338e <class ‘str‘>?ret = hashlib.md5()ret.update(‘22fdslkafjdsklfdsjafldsjf3‘.encode(‘utf-8‘))s = ret.hexdigest()print(s, type(s)) # 3ebcde7d2fc16401c8b42a7994ca34d4 <class ‘str‘>xxxxxxxxxx# 加固定盐ret = hashlib.md5(‘abcf‘.encode(‘utf-8‘)) # 盐:abcfret.update(‘123456‘.encode(‘utf-8‘))s = ret.hexdigest()print(s, type(s)) # d8128a28e5f55017ebab945a6b80db0d <class ‘str‘>xxxxxxxxxx# 加动态的盐username = input(‘输入用户名:‘).strip()password = input(‘输入密码‘).strip()ret = hashlib.md5(username[::2].encode(‘utf-8‘)) # 针对于每个账户,每个账户的盐都不一样ret.update(password.encode(‘utf-8‘))s = ret.hexdigest()print(s)对安全要求比较高的企业,比如金融行业,MD5加密的方式就不够了,得需要加密方式更高的,比如sha系列,sha1,sha224,sha512等等,数字越大,加密的方法越复杂,安全性越高,但是效率就会越慢
xxxxxxxxxxret = hashlib.sha1()ret.update(‘yunweiren‘.encode(‘utf-8‘))print(ret.hexdigest())?# 也可加盐ret = hashlib.sha384(b‘asfdsa‘)ret.update(‘yunweiren‘.encode(‘utf-8‘))print(ret.hexdigest())?# 也可以加动态的盐ret = hashlib.sha384(b‘asfdsa‘[::2])ret.update(‘yunweiren‘.encode(‘utf-8‘))print(ret.hexdigest())md5计算的就是bytes类型的数据的转换值,同一个bytes数据用同样的加密方式转化成的结果一定相同,如果不同的bytes数据(即使一个数据只是删除了一个空格)那么用同样的加密方式转化成的结果一定是不同的。所以,hashlib也是验证文件一致性的重要工具
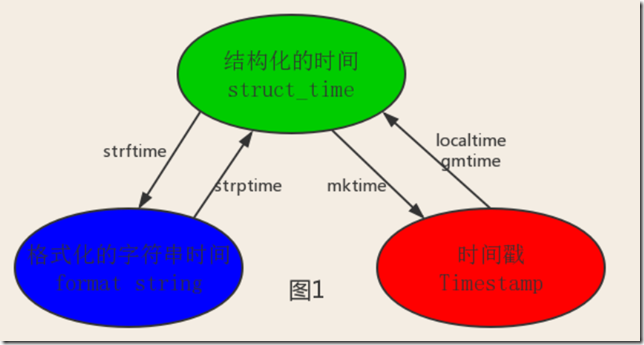
xxxxxxxxxx# 分段读,避免撑爆内存import hashlib?def md5_file(path): ret = hashlib.md5() with open(path, mode=‘rb‘) as f1: while 1: content = f1.read(1024) if content: ret.update(content) else: return ret.hexdigest()?print(md5_file(r‘python-3.7.4rc1-embed-win32.zip‘))表示时间的三种方式:
1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
2)格式化的时间字符串(Format String): ‘1999-12-06‘
xxxxxxxxxx%y 两位数的年份表示(00-99)%Y 四位数的年份表示(000-9999)%m 月份(01-12)%d 月内中的一天(0-31)%H 24小时制小时数(0-23)%I 12小时制小时数(01-12)%M 分钟数(00=59)%S 秒(00-59)%a 本地简化星期名称%A 本地完整星期名称%b 本地简化的月份名称%B 本地完整的月份名称%c 本地相应的日期表示和时间表示%j 年内的一天(001-366)%p 本地A.M.或P.M.的等价符%U 一年中的星期数(00-53)星期天为星期的开始%w 星期(0-6),星期天为星期的开始%W 一年中的星期数(00-53)星期一为星期的开始%x 本地相应的日期表示%X 本地相应的时间表示%Z 当前时区的名称%% %号本身3)元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)

xxxxxxxxxximport time?print(time.time()) # 1615173465.8671505?# 格式化时间:# 字符串类型print(time.strftime("%Y-%m-%d %H:%M:%S")) # 2021-03-08 11:17:45print(time.strftime("%y-%m-%d %H:%M:%S %A")) # 21-03-08 11:17:45 Mondayret = time.strftime("%Y{}%m{}%d{} %H:%M:%S")print(ret.format(‘年‘, ‘月‘, ‘日‘)) # 2021年03月08日 11:17:45?# 获取结构化时间print(time.localtime()) # time.struct_time(tm_year=2021, tm_mon=3, tm_mday=8, tm_hour=11, tm_min=19, tm_sec=9, tm_wday=0, tm_yday=67, tm_isdst=0)?# ------------------------------------------------------------# 时间戳 转化成 格式化时间timestamp = time.time()st = time.localtime(timestamp)ft = time.strftime("%Y-%m-%d %H:%M:%S", st)print(ft) # 2021-03-08 11:20:56?# 格式化时间转化成时间戳ft = time.strftime("%y-%m-%d %H:%M:%S")print(ft) # 21-03-08 11:24:16st = time.strptime(ft, "%y-%m-%d %H:%M:%S")print(st) # time.struct_time(tm_year=2021, tm_mon=3, tm_mday=8, tm_hour=11, tm_min=24, tm_sec=16, tm_wday=0, tm_yday=67, tm_isdst=-1)timestamp = time.mktime(st)print(timestamp)几种格式之间的转换:
xxxxxxxxxx# datatime模块import datetimenow_time = datetime.datetime.now() # 现在的时间# 只能调整的字段:weeks days hours minutes secondsprint(datetime.datetime.now() + datetime.timedelta(weeks=3)) # 三周后print(datetime.datetime.now() + datetime.timedelta(weeks=-3)) # 三周前print(datetime.datetime.now() + datetime.timedelta(days=-3)) # 三天前print(datetime.datetime.now() + datetime.timedelta(days=3)) # 三天后print(datetime.datetime.now() + datetime.timedelta(hours=5)) # 5小时后print(datetime.datetime.now() + datetime.timedelta(hours=-5)) # 5小时前print(datetime.datetime.now() + datetime.timedelta(minutes=-15)) # 15分钟前print(datetime.datetime.now() + datetime.timedelta(minutes=15)) # 15分钟后print(datetime.datetime.now() + datetime.timedelta(seconds=-70)) # 70秒前print(datetime.datetime.now() + datetime.timedelta(seconds=70)) # 70秒后?current_time = datetime.datetime.now()# 可直接调整到指定的 年 月 日 时 分 秒 等?print(current_time.replace(year=1977)) # 直接调整到1977年print(current_time.replace(month=1)) # 直接调整到1月份print(current_time.replace(year=1989,month=4,day=25)) # 1989-04-25 18:49:05.898601?# 将时间戳转化成时间print(datetime.date.fromtimestamp(1232132131)) # 2009-01-17xxxxxxxxxximport random?print(random.random()) # 大于0且小于1之间的小数print(random.uniform(1, 6)) # 大于1且小于6之间的小数?print(random.randint(1, 5)) # 大于等于1且小于5(5可以取到)print(random.randrange(1, 10, 2)) # 大于等于1且小于10之间的奇数?print(random.choice([‘如花‘, ‘凤姐‘, ‘石榴姐‘, 1]))print(random.sample((‘如花‘, ‘凤姐‘, ‘石榴姐‘), 2)) # 可以控制元素个数 ***?# 打乱顺序item = [i for i in range(10)]random.shuffle(item)print(item) # [6, 0, 9, 2, 3, 8, 7, 1, 4, 5]需求:生成随机验证码
xxxxxxxxxximport random?def code(amount): str_code = ‘‘ for i in range(amount): num = random.randint(0, 9) # 6 lower_char = chr(random.randint(97, 122)) # y upper_char = chr(random.randint(65, 90)) # A single_char = random.choice([num, lower_char, upper_char]) str_code += str(single_char) return str_code?print(code(4))print(code(5))默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING
日志级别等级:CRITICAL > ERROR > WARNING > INFO > DEBUG
1)第一版日志配置
xxxxxxxxxximport logginglogging.basicConfig( level=logging.DEBUG, # level=30, format=‘%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s‘, filename=r‘test.log‘,)logging.debug(‘调试模式‘) # 10logging.info(‘正常模式‘) # 20logging.warning(‘警告信息‘) # 30logging.error(‘错误信息‘) # 40logging.critical(‘严重错误信息‘) # 50参数说明:
xxxxxxxxxx# logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。format:指定handler使用的日志显示格式。datefmt:指定日期时间格式。level:设置rootlogger(后边会讲解具体概念)的日志级别stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。?# format参数中可能用到的格式化串:%(name)s Logger的名字%(levelno)s 数字形式的日志级别%(levelname)s 文本形式的日志级别%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有%(filename)s 调用日志输出函数的模块的文件名%(module)s 调用日志输出函数的模块名%(funcName)s 调用日志输出函数的函数名%(lineno)d 调用日志输出函数的语句所在的代码行%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒%(thread)d 线程ID。可能没有%(threadName)s 线程名。可能没有%(process)d 进程ID。可能没有%(message)s用户输出的消息缺点: 文件与屏幕输入只能选择一个
2)第二版日志配置:对象方式
xxxxxxxxxximport logging?# 创建一个logging对象logger = logging.getLogger()?# 创建一个文件对象fh = logging.FileHandler(‘rc.log‘, encoding=‘utf-8‘)?# 创建一个屏幕对象sh = logging.StreamHandler()?# 配置显示格式formatter1 = logging.Formatter(‘%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s‘)formatter2 = logging.Formatter(‘%(asctime)s %(message)s‘)fh.setFormatter(formatter1)sh.setFormatter(formatter2)?logger.addHandler(fh)logger.addHandler(sh)?# 总开关logger.setLevel(10)# 分别设置日志级别fh.setLevel(10)sh.setLevel(40)?logging.debug(‘调试模式‘) # 10logging.info(‘正常模式‘) # 20logging.warning(‘警告信息‘) # 30logging.error(‘错误信息‘) # 40logging.critical(‘严重错误信息‘) # 50logging库提供了多个组件:Logger、Handler、Filter、Formatter。
可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过fh.setLevel(logging.Debug)单对文件流设置某个级别
3)第三版日志配置:通过配置文件方式
xxxxxxxxxximport osimport logging.config?# 定义三种日志输出格式standard_format = ‘[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]‘ \ ‘[%(levelname)s][%(message)s]‘ # 其中name为getlogger指定的名字simple_format = ‘[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s‘id_simple_format = ‘[%(levelname)s][%(asctime)s] %(message)s‘?# 定义日志输出格式logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录logfile_name = ‘all2.log‘ # log文件名# 如果不存在定义的日志目录就创建一个if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir)?# log文件的全路径logfile_path = os.path.join(logfile_dir, logfile_name)?# log配置字典LOGGING_DIC = { ‘version‘: 1, ‘disable_existing_loggers‘: False, ‘formatters‘: { ‘standard‘: { ‘format‘: standard_format }, ‘simple‘: { ‘format‘: simple_format }, }, ‘filters‘: {}, ‘handlers‘: { # 打印到终端的日志 ‘console‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.StreamHandler‘, # 打印到屏幕 ‘formatter‘: ‘simple‘ }, # 打印到文件的日志,收集info及以上的日志 ‘default‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.handlers.RotatingFileHandler‘, # 保存到文件 ‘formatter‘: ‘standard‘, ‘filename‘: logfile_path, # 日志文件 ‘maxBytes‘: 1024 * 1024 * 5, # 日志大小 5M ‘backupCount‘: 5, # 日志备份的个数 ‘encoding‘: ‘utf-8‘, # 日志文件的编码,再也不用担心中文log乱码了 }, }, ‘loggers‘: { # logging.getLogger(__name__)拿到的logger配置 ‘‘: { ‘handlers‘: [‘default‘, ‘console‘], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 ‘level‘: ‘DEBUG‘, ‘propagate‘: True, # 向上(更高level的logger)传递 }, },}??def load_my_logging_cfg(task_id): logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(task_id) # 生成一个log实例 return logger?def login(): logger1 = load_my_logging_cfg(‘登录部分‘) logger1.info(‘xx人登陆成功‘)?def transfer(): logger2 = load_my_logging_cfg(‘转账部分‘) logger2.info(‘张三给李四转账成功!‘)在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等
namedtuple: 生成可以使用名字来访问元素内容的tupledeque: 双端队列,可以快速的从另外一侧追加和推出对象Counter: 计数器,主要用来计数OrderedDict: 有序字典defaultdict: 带有默认值的字典xxxxxxxxxxfrom collections import namedtuple?# 格式# namedtuple(‘名称‘, [属性list])?# 表示一个点Point = namedtuple(‘Point‘, [‘x‘, ‘y‘])p = Point(1, 2)print(type(p)) # <class ‘__main__.Point‘>print(p) # Point(x=1, y=2)print(p[0]) # 1print(p[1]) # 2print(p.x) # 1print(p.y) # 2?# 表示圆Circle = namedtuple(‘Circle‘, [‘x‘, ‘y‘, ‘r‘])c = Circle(1, 2, 1)print(type(c)) # <class ‘__main__.Circle‘>?# -------------------------------------------from collections import namedtuple?struct_time = namedtuple(‘struct_time‘, [‘tm_year‘, ‘tm_mon‘, ‘tm_mday‘])st = struct_time(2019, 7, 2)print(st) # struct_time(tm_year=2019, tm_mon=7, tm_mday=2)使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
xxxxxxxxxx# deque: 类似于列表的一种容器型数据,插入元素删除元素效率高.from collections import deque?q = deque([‘a‘, 1, ‘c‘, ‘d‘])print(q) # deque([‘a‘, 1, ‘c‘, ‘d‘])q.append(‘e‘)print(q) # deque([‘a‘, 1, ‘c‘, ‘d‘, ‘e‘])q.appendleft(‘ly‘)print(q) # deque([‘ly‘, ‘a‘, 1, ‘c‘, ‘d‘, ‘e‘])?# 删除q.pop()q.popleft()print(q) # deque([‘a‘, 1, ‘c‘, ‘d‘])?# 按照索引取值print(q[0]) # a?# 按照索引删除任意值del q[2]print(q) # deque([‘a‘, 1, ‘d‘])q.insert(1, ‘2‘)print(q) # deque([‘a‘, ‘2‘, 1, ‘d‘])注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序
xxxxxxxxxxd = dict([(‘a‘, 1), (‘b‘, 2), (‘c‘, 3)])print(d)?from collections import OrderedDict?od = OrderedDict([(‘a‘, 1), (‘b‘, 2), (‘c‘, 3)])print(od)print(od[‘a‘])print(od[‘b‘])?# ---------------------------------from collections import OrderedDict?od = OrderedDict()od[‘z‘] = "Z"od[‘x‘] = "X"od[‘y‘] = "Y"print(od) # OrderedDict([(‘z‘, ‘Z‘), (‘x‘, ‘X‘), (‘y‘, ‘Y‘)])使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict
xxxxxxxxxxfrom collections import defaultdict?l1 = [11, 22, 33, 44, 55, 77, 88, 99]dic = {}for i in l1: if i < 66: if ‘key1‘ not in dic: dic[‘key1‘] = [] dic[‘key1‘].append(i)? else: if ‘key2‘ not in dic: dic[‘key2‘] = [] dic[‘key2‘].append(i)print(dic) # {‘key1‘: [11, 22, 33, 44, 55], ‘key2‘: [77, 88, 99]}?# ----------------------------------------------l1 = [11, 22, 33, 44, 55, 77, 88, 99]dic = defaultdict(list)for i in l1: if i < 66: dic[‘key1‘].append(i)? else: dic[‘key2‘].append(i)print(dic) # defaultdict(<class ‘list‘>, {‘key1‘: [11, 22, 33, 44, 55], ‘key2‘: [77, 88, 99]})?# ----------------------------------------------# 需要一个可回调的dic = defaultdict(lambda :None)# dic = defaultdict(None) # 报错for i in range(1,4): dic[i]print(dic)xxxxxxxxxxc = Counter(‘flkjdasffdfakjsfdsaklfdsalf‘) # 计数器print(c) # Counter({‘f‘: 7, ‘d‘: 4, ‘a‘: 4, ‘s‘: 4, ‘l‘: 3, ‘k‘: 3, ‘j‘: 2})print(c[‘f‘]) # 7正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法
元字符 | 匹配内容 |
|---|---|
| \w | 匹配字母(包含中文)或数字或下划线 |
| \W | 匹配非字母(包含中文)或数字或下划线 |
| \s | 匹配任意的空白符 |
| \S | 匹配任意非空白符 |
| \d | 匹配数字 |
| \D | p匹配非数字 |
| \A | 从字符串开头匹配 |
| \z | 匹配字符串的结束,如果是换行,只匹配到换行前的结果 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 匹配字符组中的字符 |
| [^...] | 匹配除了字符组中的字符的所有字符 |
| * | 匹配0个或者多个左边的字符。 |
| + | 匹配一个或者多个左边的字符。 |
| ? | 匹配0个或者1个左边的字符,非贪婪方式。 |
| {n} | 精准匹配n个前面的表达式。 |
| {n,m} | 匹配n到m次由前面的正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或者b。 |
| () | 匹配括号内的表达式,也表示一个组 |
xxxxxxxxxx# 1,之前学过的字符串的常用操作:一对一匹配s1 = ‘fdskahf太白金星‘print(s1.find(‘太白‘)) # 7?# 2,正则匹配:# 单个字符匹配import re?# \w 与 \Wprint(re.findall(‘\w‘, ‘太白jx 12*() _‘)) # [‘太‘, ‘白‘, ‘j‘, ‘x‘, ‘1‘, ‘2‘, ‘_‘]print(re.findall(‘\W‘, ‘太白jx 12*() _‘)) # [‘ ‘, ‘*‘, ‘(‘, ‘)‘, ‘ ‘]?# \s 与\Sprint(re.findall(‘\s‘, ‘太白barry*(_ \t \n‘)) # [‘ ‘, ‘\t‘, ‘ ‘, ‘\n‘]print(re.findall(‘\S‘, ‘太白barry*(_ \t \n‘)) # [‘太‘, ‘白‘, ‘b‘, ‘a‘, ‘r‘, ‘r‘, ‘y‘, ‘*‘, ‘(‘, ‘_‘]?# \d 与 \Dprint(re.findall(‘\d‘, ‘1234567890 alex *(_‘)) # [‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘, ‘0‘]print(re.findall(‘\D‘, ‘1234567890 alex *(_‘)) # [‘ ‘, ‘a‘, ‘l‘, ‘e‘, ‘x‘, ‘ ‘, ‘*‘, ‘(‘, ‘_‘]?# \A 与 ^print(re.findall(‘\Ahel‘, ‘hello 太白金星 -_- 666‘)) # [‘hel‘]print(re.findall(‘^hel‘, ‘hello 太白金星 -_- 666‘)) # [‘hel‘]?# \Z、\z 与 $ @@print(re.findall(‘666\Z‘, ‘hello 太白金星 *-_-* \n666‘)) # [‘666‘]# print(re.findall(‘666\z‘,‘hello 太白金星 *-_-* \n666‘)) # [] # python3.7报错print(re.findall(‘666$‘, ‘hello 太白金星 *-_-* \n666‘)) # [‘666‘]?# \n 与 \tprint(re.findall(‘\n‘, ‘hello \n 太白金星 \t*-_-*\t \n666‘)) # [‘\n‘, ‘\n‘]print(re.findall(‘\t‘, ‘hello \n 太白金星 \t*-_-*\t \n666‘)) # [‘\t‘, ‘\t‘]?# 重复匹配# . ? * + {m,n} .* .*?# . 匹配任意字符,除了换行符(re.DOTALL 这个参数可以匹配\n)。print(re.findall(‘a.b‘, ‘ab aab a*b a2b a牛b a\nb‘)) # [‘aab‘, ‘a*b‘, ‘a2b‘, ‘a牛b‘]print(re.findall(‘a.b‘, ‘ab aab a*b a2b a牛b a\nb‘, re.DOTALL)) # [‘aab‘, ‘a*b‘, ‘a2b‘, ‘a牛b‘]?# ?匹配0个或者1个由左边字符定义的片段。print(re.findall(‘a?b‘, ‘ab aab abb aaaab a牛b aba**b‘)) # [‘ab‘, ‘ab‘, ‘ab‘, ‘b‘, ‘ab‘, ‘b‘, ‘ab‘, ‘b‘]?# * 匹配0个或者多个左边字符表达式。 满足贪婪匹配 @@print(re.findall(‘a*b‘, ‘ab aab aaab abbb‘)) # [‘ab‘, ‘aab‘, ‘aaab‘, ‘ab‘, ‘b‘, ‘b‘]print(re.findall(‘ab*‘, ‘ab aab aaab abbbbb‘)) # [‘ab‘, ‘a‘, ‘ab‘, ‘a‘, ‘a‘, ‘ab‘, ‘abbbbb‘]?# + 匹配1个或者多个左边字符表达式。 满足贪婪匹配 @@print(re.findall(‘a+b‘, ‘ab aab aaab abbb‘)) # [‘ab‘, ‘aab‘, ‘aaab‘, ‘ab‘]?# {m,n} 匹配m个至n个左边字符表达式。 满足贪婪匹配 @@print(re.findall(‘a{2,4}b‘, ‘ab aab aaab aaaaabb‘)) # [‘aab‘, ‘aaab‘]?# .* 贪婪匹配 从头到尾.print(re.findall(‘a.*b‘, ‘ab aab a*()b‘)) # [‘ab aab a*()b‘]?# .*? 此时的?不是对左边的字符进行0次或者1次的匹配,# 而只是针对.*这种贪婪匹配的模式进行一种限定:告知他要遵从非贪婪匹配 推荐使用!print(re.findall(‘a.*?b‘, ‘ab a1b a*()b, aaaaaab‘)) # [‘ab‘, ‘a1b‘, ‘a*()b‘]?# []: 括号中可以放任意一个字符,一个中括号代表一个字符# - 在[]中表示范围,如果想要匹配上- 那么这个-符号不能放在中间.# ^ 在[]中表示取反的意思.print(re.findall(‘a.b‘, ‘a1b a3b aeb a*b arb a_b‘)) # [‘a1b‘, ‘a3b‘, ‘a4b‘, ‘a*b‘, ‘arb‘, ‘a_b‘]print(re.findall(‘a[abc]b‘, ‘aab abb acb adb afb a_b‘)) # [‘aab‘, ‘abb‘, ‘acb‘]print(re.findall(‘a[0-9]b‘, ‘a1b a3b aeb a*b arb a_b‘)) # [‘a1b‘, ‘a3b‘]print(re.findall(‘a[a-z]b‘, ‘a1b a3b aeb a*b arb a_b‘)) # [‘aeb‘, ‘arb‘]print(re.findall(‘a[a-zA-Z]b‘, ‘aAb aWb aeb a*b arb a_b‘)) # [‘aAb‘, ‘aWb‘, ‘aeb‘, ‘arb‘]print(re.findall(‘a[0-9][0-9]b‘, ‘a11b a12b a34b a*b arb a_b‘)) # [‘a11b‘, ‘a12b‘, ‘a34b‘]print(re.findall(‘a[*-+]b‘, ‘a-b a*b a+b a/b a6b‘)) # [‘a*b‘, ‘a+b‘]# - 在[]中表示范围,如果想要匹配上- 那么这个-符号不能放在中间.print(re.findall(‘a[-*+]b‘, ‘a-b a*b a+b a/b a6b‘)) # [‘a-b‘, ‘a*b‘, ‘a+b‘]print(re.findall(‘a[^a-z]b‘, ‘acb adb a3b a*b‘)) # [‘a3b‘, ‘a*b‘]?# 练习:# 找到字符串中‘alex_sb ale123_sb wu12sir_sb wusir_sb ritian_sb‘ 的 alex wusir ritianprint(re.findall(‘([a-z]+)_sb‘, ‘alex_sb ale123_sb wusir12_sb wusir_sb ritian_sb‘))?# 分组:# () 制定一个规则,将满足规则的结果匹配出来print(re.findall(‘(.*?)_sb‘, ‘alex_sb wusir_sb 日天_sb‘)) # [‘alex‘, ‘ wusir‘, ‘ 日天‘]?# 应用举例:print(re.findall(‘href="(.*?)"‘, ‘<a href="http://www.baidu.com">点击</a>‘)) # [‘http://www.baidu.com‘]?# | 匹配 左边或者右边print(re.findall(‘alex|太白|wusir‘, ‘alex太白wusiraleeeex太太白odlb‘)) # [‘alex‘, ‘太白‘, ‘wusir‘, ‘太白‘]print(re.findall(‘compan(y|ies)‘, ‘Too many companies have gone bankrupt, and the next one is my company‘)) # [‘ies‘, ‘y‘]print(re.findall(‘compan(?:y|ies)‘, ‘Too many companies have gone bankrupt, and the next one is my company‘)) # [‘companies‘, ‘company‘]# 分组() 中加入?: 表示将整体匹配出来而不只是()里面的内容。xxxxxxxxxximport re?# 1 findall 全部找到返回一个列表。print(re.findall(‘a‘, ‘alexwusirbarryeval‘)) # [‘a‘, ‘a‘, ‘a‘]?# 2 search 只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。print(re.search(‘sb|alex‘, ‘alex sb sb barry 日天‘)) # <_sre.SRE_Match object; span=(0, 4), match=‘alex‘>print(re.search(‘alex‘, ‘alex sb sb barry 日天‘).group()) # alex?# 3 match:同search,不过在字符串开始处进行匹配,完全可以用search+^代替matchprint(re.match(‘barry‘, ‘barry alex wusir 日天‘)) # <_sre.SRE_Match object; span=(0, 5), match=‘barry‘>print(re.match(‘barry‘, ‘barry alex wusir 日天‘).group()) # barry?# 4 split 分割 可按照任意分割符进行分割print(re.split(‘[ ::,;;,]‘, ‘alex wusir,日天,太白;女神;肖锋:吴超‘)) # [‘alex‘, ‘wusir‘, ‘日天‘, ‘太白‘, ‘女神‘, ‘肖锋‘, ‘吴超‘]?# 5 sub 替换print(re.sub(‘barry‘, ‘太白‘, ‘barry是最好的讲师,barry就是一个普通老师,请不要将barry当男神对待。‘))print(re.sub(‘barry‘, ‘太白‘, ‘barry是最好的讲师,barry就是一个普通老师,请不要将barry当男神对待。‘, 2)) # 替换两个print(re.sub(‘([a-zA-Z]+)([^a-zA-Z]+)([a-zA-Z]+)([^a-zA-Z]+)([a-zA-Z]+)‘, r‘\5\2\3\4\1‘, r‘alex is sb‘))?# 6 compileobj = re.compile(‘\d{2}‘)print(obj.search(‘abc123eeee‘).group()) # 12print(obj.findall(‘abc123eeee‘)) # [‘12‘],重用了obj?# import reret = re.finditer(‘\d‘, ‘ds3sy4784a‘) # finditer返回一个存放匹配结果的迭代器print(ret) # <callable_iterator object at 0x10195f940>print(next(ret).group()) # 3 查看第一个结果print(next(ret).group()) # 4 查看第二个结果print([i.group() for i in ret]) # 查看剩余的左右结果[‘7‘, ‘8‘, ‘4‘]xxxxxxxxxximport re?# 命名分组匹配:ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>", "<h1>hello</h1>")# 还可以在分组中利用?<name>的形式给分组起名字,获取的匹配结果可以直接用group(‘名字‘)拿到对应的值print(ret.group(‘tag_name‘)) # 结果 :h1print(ret.group()) # 结果 :<h1>hello</h1>?ret = re.search(r"<(\w+)>\w+</\1>", "<h1>hello</h1>")# 如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致,获取的匹配结果可以直接用group(序号)拿到对应的值print(ret.group(1))print(ret.group()) # 结果 :<h1>hello</h1>xxxxxxxxxximport re?# 1,"1-2*(60+(-40.35/5)-(-4*3))"# 1.1 匹配所有的整数print(re.findall(‘\d+‘, "1-2*(60+(-40.35/5)-(-4*3))")) # [‘1‘, ‘2‘, ‘60‘, ‘40‘, ‘35‘, ‘5‘, ‘4‘, ‘3‘]?# 1.2 匹配所有的数字(包含小数)print(re.findall(r‘\d+\.?\d*|\d*\.?\d+‘, "1-2*(60+(-40.35/5)-(-4*3))")) # [‘1‘, ‘2‘, ‘60‘, ‘40.35‘, ‘5‘, ‘4‘, ‘3‘]?# 1.3 匹配所有的数字(包含小数包含负号)print(re.findall(r‘-?\d+\.?\d*|\d*\.?\d+‘, "1-2*(60+(-40.35/5)-(-4*3))")) # [‘1‘, ‘-2‘, ‘60‘, ‘-40.35‘, ‘5‘, ‘-4‘, ‘3‘]?# 2,匹配一段你文本中的每行的邮箱# http://blog.csdn.net/make164492212/article/details/51656638 匹配所有邮箱?# 3,匹配一段你文本中的每行的时间字符串 这样的形式:‘1995-04-27‘?s1 = ‘‘‘时间就是1995-04-27,2005-04-271999-04-27 创始人老男孩老师 alex 1980-04-27:1980-04-272018-12-08‘‘‘print(re.findall(‘\d{4}-\d{2}-\d{2}‘, s1)) # [‘1995-04-27‘, ‘2005-04-27‘, ‘1999-04-27‘, ‘1980-04-27‘, ‘1980-04-27‘, ‘2018-12-08‘]?# 4 匹配 一个浮点数print(re.findall(‘\d+\.\d*‘,‘1.17‘)) # [‘1.17‘]?# 5 匹配qq号:腾讯从10000开始:# print(re.findall(‘[1-9][0-9]{4,}‘, ‘2413545136‘))?s1 = ‘‘‘<p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/7459977.html" target="_blank">python基础一</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/7562422.html" target="_blank">python基础二</a></p><p><a style="text-decoration: underline;" href="https://www.cnblogs.com/jin-xin/articles/9439483.html" target="_blank">Python最详细,最深入的代码块小数据池剖析</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/7738630.html" target="_blank">python集合,深浅copy</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8183203.html" target="_blank">python文件操作</a></p><h4 style="background-color: #f08080;">python函数部分</h4><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8241942.html" target="_blank">python函数初识</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8259929.html" target="_blank">python函数进阶</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8305011.html" target="_blank">python装饰器</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8423526.html" target="_blank">python迭代器,生成器</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8423937.html" target="_blank">python内置函数,匿名函数</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8743408.html" target="_blank">python递归函数</a></p><p><a style="text-decoration: underline;" href="https://www.cnblogs.com/jin-xin/articles/8743595.html" target="_blank">python二分查找算法</a></p>?‘‘‘# 1,找到所有的p标签ret = re.findall(‘<p>.*?</p>‘, s1)print(ret)??# 2,找到所有a标签对应的urlprint(re.findall(‘<a.*?href="(.*?)".*?</a>‘,s1))一个python文件可以有两种用途:
python为我们内置了全局变量__name__,
__name__ 等于__main____name__等于模块名作用:用来控制.py文件在不同的应用场景下执行不同的逻辑(或者是在模块文件中测试代码)
xxxxxxxxxxprint(‘from the abcd.py‘)?__all__ = [‘name‘, ‘read1‘, ‘read2‘]name = ‘运维人在路上‘??def read1(): print(‘abcd模块:‘, name)??def read2(): print(‘abcd模块‘) read1()??def change(): global name name = ‘barry‘??def func(): print(‘正在调试‘)??if __name__ == ‘__main__‘: # 在模块文件中测试read1()函数 # 此模块被导入时 __name__ == abcd 所以不执行 read1()顺序:内存 ----> 内置模块 ---> sys.path
模块的查找顺序
xxxxxxxxxx#在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。>>>import sys>>>sys.path.append(‘/a/b/c/d‘)>>>sys.path.insert(0,‘/x/y/z‘) #排在前的目录,优先被搜索?#windows下的路径不加r开头,会语法错误sys.path.insert(0,r‘C:\Users\Administrator\PycharmProjects\a‘)包就是一个包含有__init__.py文件的文件夹,所以其实我们创建包的目的就是为了用文件夹将文件/模块组织起来
需要强调的是:
__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错创建一个包,也会发生三件事:
xxxxxxxxxximport aaa1. 将该aaa包内 __init__.py文件加载到内存.2. 创建一个以aaa命名的名称空间.3. 通过aaa. 的方式引用__init__的所有的名字.
1)执行文件如何引用aaa包中__init__.py中的变量和方法
因为执行文件和aaa包在同一级下,直接import aaa就可以将aaa包__init__.py中的变量和方法引入
xxxxxxxxxximport aaaprint(aaa.x)aaa.f1()2)执行文件如何引入aaa包中m1文件中的变量和方法
xxxxxxxxxx# 1. 在执行文件写入 import aaa# 2. aaa的 __init__ 里面 写 from aaa import m1# 3. 然后在执行文件 aaa.m1.aimport aaaprint(aaa.m1.a)aaa.m1.func1()3)执行文件如何引入aaa包中bbb包中__init__.py文件中的变量和方法
xxxxxxxxxx# 1. 在执行文件写入 import aaa# 2. aaa的 __init__ 里面 写 from aaa import bbb# 3. 然后在执行文件 aaa.bbbimport aaaprint(aaa.bbb)print(aaa.bbb.name)aaa.bbb.func3()4)执行文件如何引入aaa包中bbb包中mb.py文件中的变量和方法
xxxxxxxxxx# 1. 在执行文件写入 import aaa# 2. 在aaa包的__Init__ 写上 from aaa import bbb (这样写 bbb包的__init__里面所有的名字都能引用)# 3. 在bbb包的__Init__ 写上 from aaa.bbb import mbimport aaaprint(aaa.bbb.name)aaa.bbb.mb.func3()通过这种方式不用设置__init__.py文件

1)执行文件如何引入aaa包中m1中的变量和方法
xxxxxxxxxx# 直接from aaa import m1即可from aaa import m1m1.func()print(m1.age)2)执行文件如何引入aaa包中bbb包中m2.py中的变量和方法
xxxxxxxxxxfrom aaa.bbb.m2 import func1func1()# 或者from aaa.bbb import m2m2.func1()绝对导入:以顶级包作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)

1)执行文件中使用相对引入导入nb包m1,m2,m3中的函数
xxxxxxxxxx# 执行文件内容import nbnb.f1()nb.f2()?#nb包中的__init__.py文件from nb.m1 import f1, f2from nb.m2 import f3, f4from nb.m3 import f5, f6
标签:fun 练习 round mic isp 初始 报错 替换 使用
原文地址:https://www.cnblogs.com/hujinzhong/p/14504092.html