标签:substr 优先 cas end 开发 实现 RKE The position
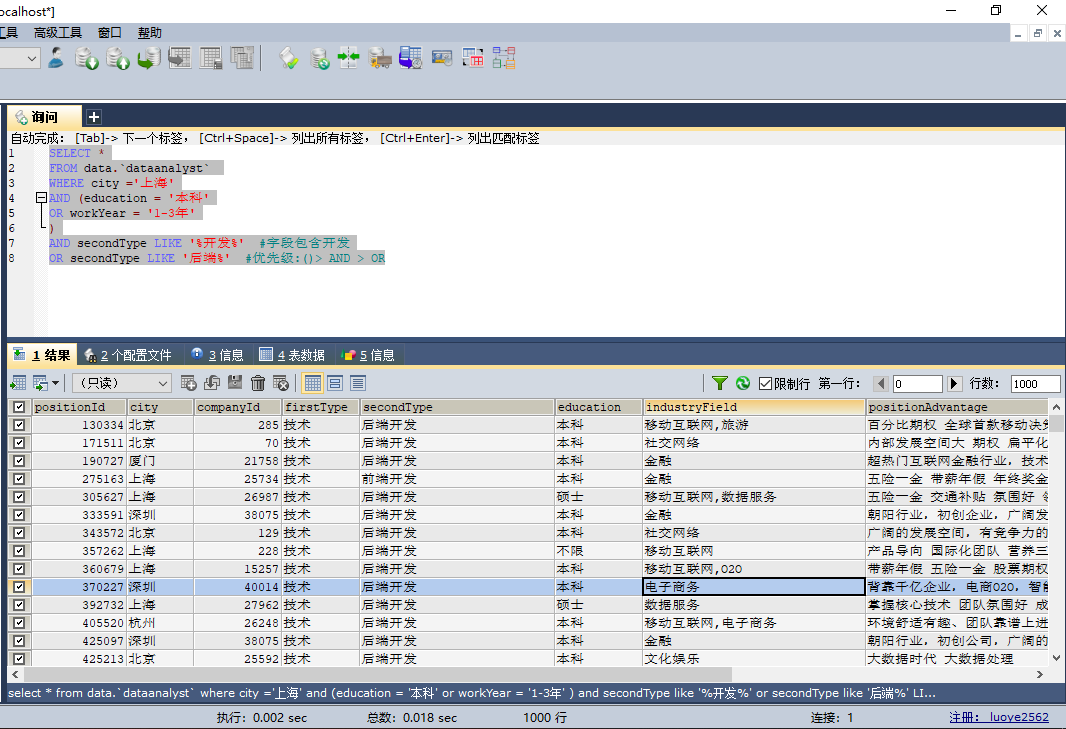
1. 基本的经典查询
#基本的查询语句
SELECT *
FROM data.`dataanalyst`
WHERE city =‘上海‘
AND (education = ‘本科‘
OR workYear = ‘1-3年‘
)
AND secondType LIKE ‘%开发%‘ #字段包含开发
OR secondType LIKE ‘后端%‘ #优先级:()> AND > OR
结果:
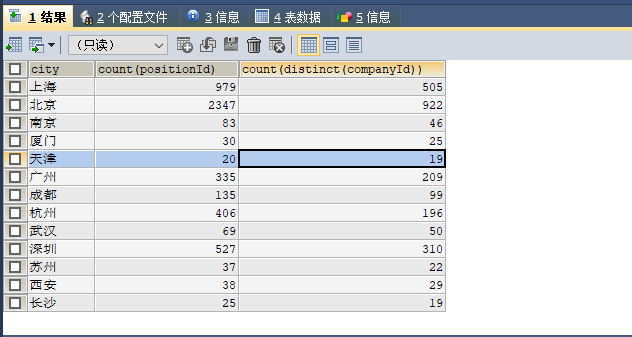
2. 不同城市招聘公司的数量,需要用distinct去重
#不同城市招聘公司的数量,需要用distinct去重
SELECT
city,
COUNT(positionId),
COUNT(DISTINCT(companyId))
FROM data.`dataanalyst`
GROUP BY city
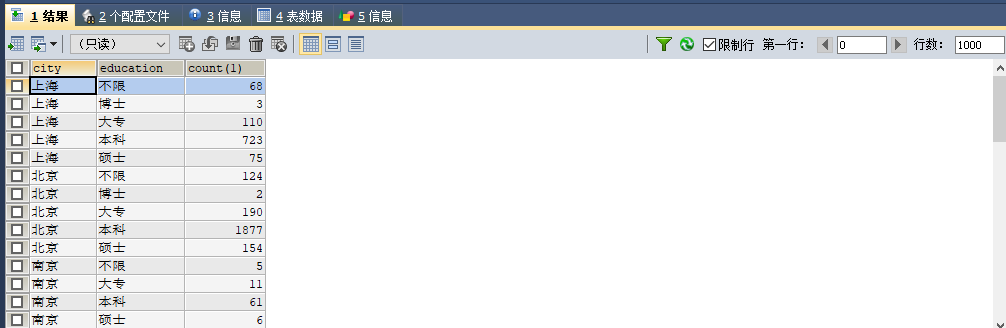
3. 不同城市,学历的招聘岗位数目
#不同城市,学历的数目
SELECT city,education,COUNT(1) FROM data.`dataanalyst`
GROUP BY city,education
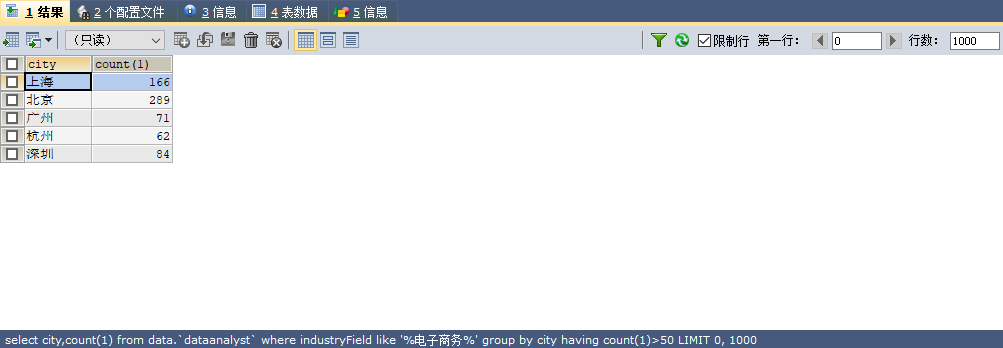
4. 不同城市电子商务岗位的数量
#不同城市电子商务岗位的数量
SELECT city,COUNT(1) FROM data.`dataanalyst`
WHERE industryField LIKE ‘%电子商务%‘
GROUP BY city
HAVING COUNT(1)>50 #二次过滤,挑选拥有电子商务岗位数量为50以上的城市
5. 这是第4题的改写
上面也可以写成这样
把where合并入having中
#不同城市电子商务岗位的数量
SELECT city,COUNT(1) FROM data.`dataanalyst`
GROUP BY city
HAVING COUNT(IF(industryField LIKE ‘%电子商务%‘,1,NULL))>50
得出的结果完全相同
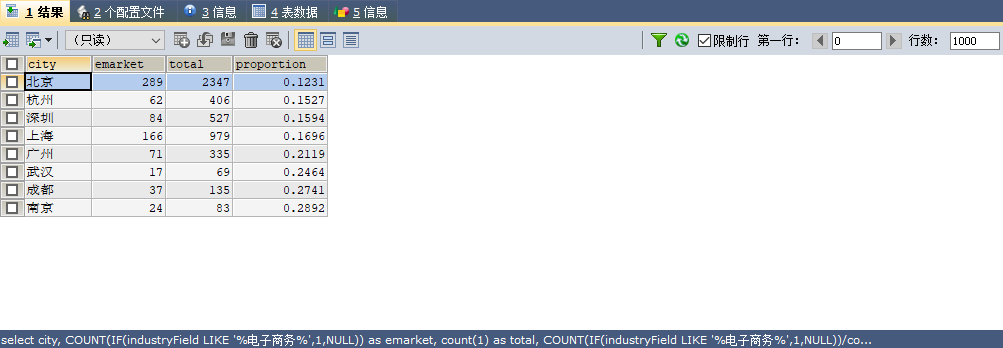
6. 不同城市下,电子商务岗位在所有岗位中的占比
注意:AS的别名在where中起名之后,只能在having,order by中使用
select
city,
COUNT(IF(industryField LIKE ‘%电子商务%‘,1,NULL)) as emarket,
count(1) as total,
COUNT(IF(industryField LIKE ‘%电子商务%‘,1,NULL))/count(1) as proportion
from data.`dataanalyst`
group by city
having emarket>10
order by proportion
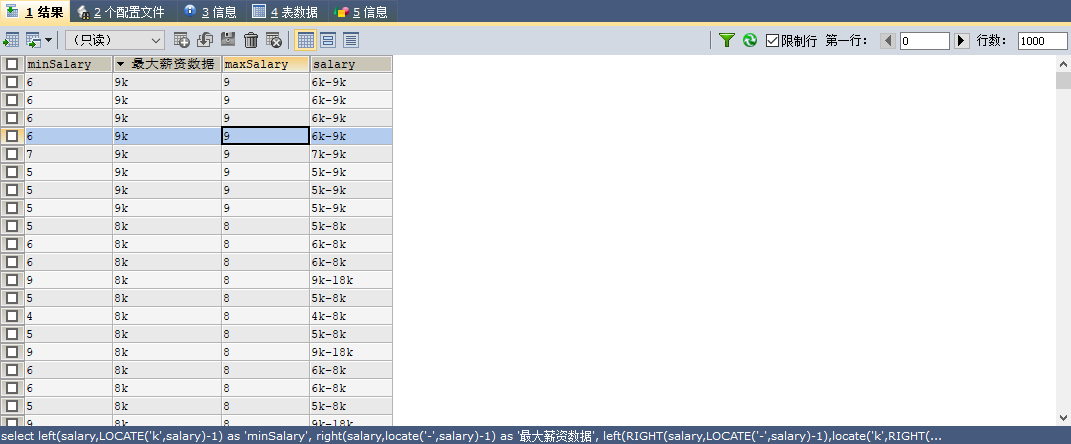
7. 截取薪资上限和下限
SELECT
LEFT(salary,LOCATE(‘k‘,salary)-1) AS ‘minSalary‘,
RIGHT(salary,LOCATE(‘-‘,salary)-1) AS ‘最大薪资数据‘,
#去掉最后的k
LEFT(RIGHT(salary,LOCATE(‘-‘,salary)-1),LOCATE(‘k‘,RIGHT(salary,LOCATE(‘-‘,salary)-1))-1) AS ‘maxSalary‘,
salary
FROM data.`dataanalyst`
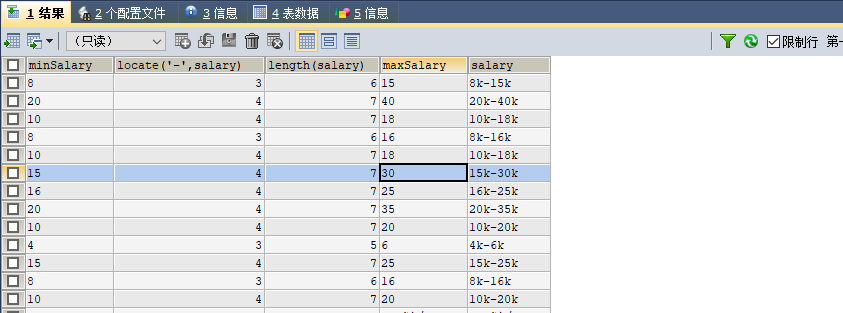
8. 是第7题薪资上下限的改写,使用substr函数
SELECT
LEFT(salary,LOCATE(‘k‘,salary)-1) AS ‘minSalary‘,
LOCATE(‘-‘,salary),
LENGTH(salary),
#substr(字符串,从哪里开始,截取长度)
SUBSTR(salary,LOCATE(‘-‘,salary)+1,LENGTH(salary)-LOCATE(‘-‘,salary)-1) AS ‘maxSalary‘,
salary
FROM data.`dataanalyst`
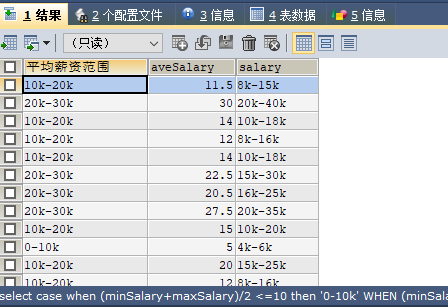
9. 子查询实现对平均薪资分区
SELECT
CASE
WHEN (minSalary+maxSalary)/2 <=10 THEN ‘0-10k‘
WHEN (minSalary+maxSalary)/2 <=20 THEN ‘10k-20k‘
WHEN (minSalary+maxSalary)/2 <=30 THEN ‘20k-30k‘
ELSE ‘30k以上‘
END AS ‘平均薪资范围‘,
(minSalary+maxSalary)/2 AS ‘aveSalary‘,
salary
FROM(
SELECT
LEFT(salary,LOCATE(‘k‘,salary)-1) AS ‘minSalary‘,
LOCATE(‘-‘,salary),
LENGTH(salary),
#substr(字符串,从哪里开始,截取长度)
SUBSTR(salary,LOCATE(‘-‘,salary)+1,LENGTH(salary)-LOCATE(‘-‘,salary)-1) AS ‘maxSalary‘,
salary
FROM data.`dataanalyst`) AS t
注意对表子查询的话,最后要加上 as t
标签:substr 优先 cas end 开发 实现 RKE The position
原文地址:https://www.cnblogs.com/snailser/p/14509944.html