标签:语言 margin ref info 元素 节点 ash 分支 支持
python爬虫获取网站分为3步:首先爬取整个网页,然后解析网站结构,找到想要的节点ID。最后过滤出所需的数据。
step 01 检查运行环境,安装必要的包
1 #默认电脑中已安装anaconda,终端前有(base)方可运行以下命令 2 #安装四个包 3 conda install bs4 requests pandas numpy 4 #从终端打开python 5 python
安装anaconda和一些包的过程可能会遇到一些问题,请参考https://www.cnblogs.com/liangxuran/p/13473664.html
step 02 爬取整个网页
以国家地震科学数据中心的网站的共享数据为例,爬取2010年1月1日全球地震的震相数据。该网站优秀之处在于域名自带查询功能,本文选择的网址和网站截图如下:
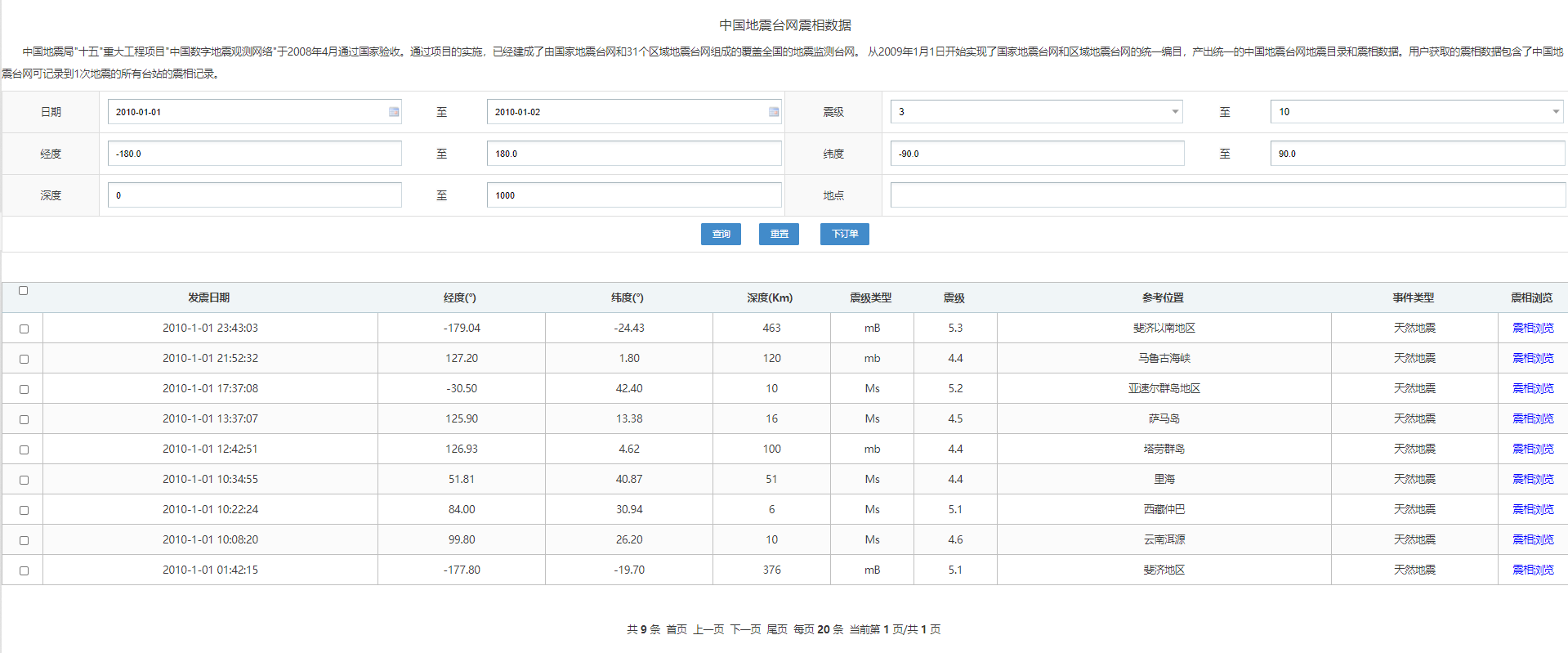
爬取该网页元素的python命令:
1 from bs4 import BeautifulSoup 2 import requests 3 4 #首先用requests请求链接 5 response = requests.get("https://data.earthquake.cn/datashare/report.shtml?PAGEID=earthquake_zgtwzx&begtime=2010-01-01&endtime=2010-01-01,verify=False) #requests请求链接,verify选项用于忽略安全证书 6 encoding = response.apparent_encoding #获取页面编码格式 7 response.encoding = encoding #修改请求编码为页面对应的编码格式,以避免乱码 8 9 #然后用beautifulSoup解析网页 10 #开始解析网页每个节点 11 bd_soup = BeautifulSoup(response.text, "lxml") #使用lxml解析器来对html进行解析 12 print(type(bd_soup)) #打印网页对象的类型 13 #返回结果为<class ‘bs4.BeautifulSoup‘> 14 print(bd_soup.prettify()) #输出缩进后的网页对象
输出的网页对象是一段相当长的html文本,这就是从服务器获取到的互联网资源,其中包含了该网页全部的资源和隐藏的资源。浏览器的作用就是把这些html解析并呈现出图形化的网页。
step 03 解析网站结构
刚刚输出的内容在浏览器中也可以看到,为例找到网页上元素对应的代码位置,我们在浏览器上用鼠标右键单击“检查”(chrome浏览器或Microsoft edge浏览器都支持此功能),出现的html就是我们从网站上下载到本地端的资源,也就是我们刚刚爬虫所所获取的html。
关于html语言
html或xml由树形结构组成,用缩进代表分支,每个元素的结构都是 <name>content</name> 其中每个元素的内容可以是纯文本,也可以由一个或多个子元素组成。另外,对于html的子元素,<name> 里面还可以设置它的属性attribute。
常见的元素有 <head> 标题 <body> 内容 <table> 表格 <p> 段落 <div> 标签 等。常见的属性有:id="id_name" 该网站内某元素的唯一id号 style="display" width="100%" class="class_name" 等。
对于html中的表格 <tr> 元素代表一行 <td> 元素代表其中的一列,因此网站的一行三列的表格结构是 <tr> <td> column1 </td> <td> column2 </td> <td> column3 </td> </tr>
因此,我们的目的就是从这些html或xml中找到Element中对应数据的元素。
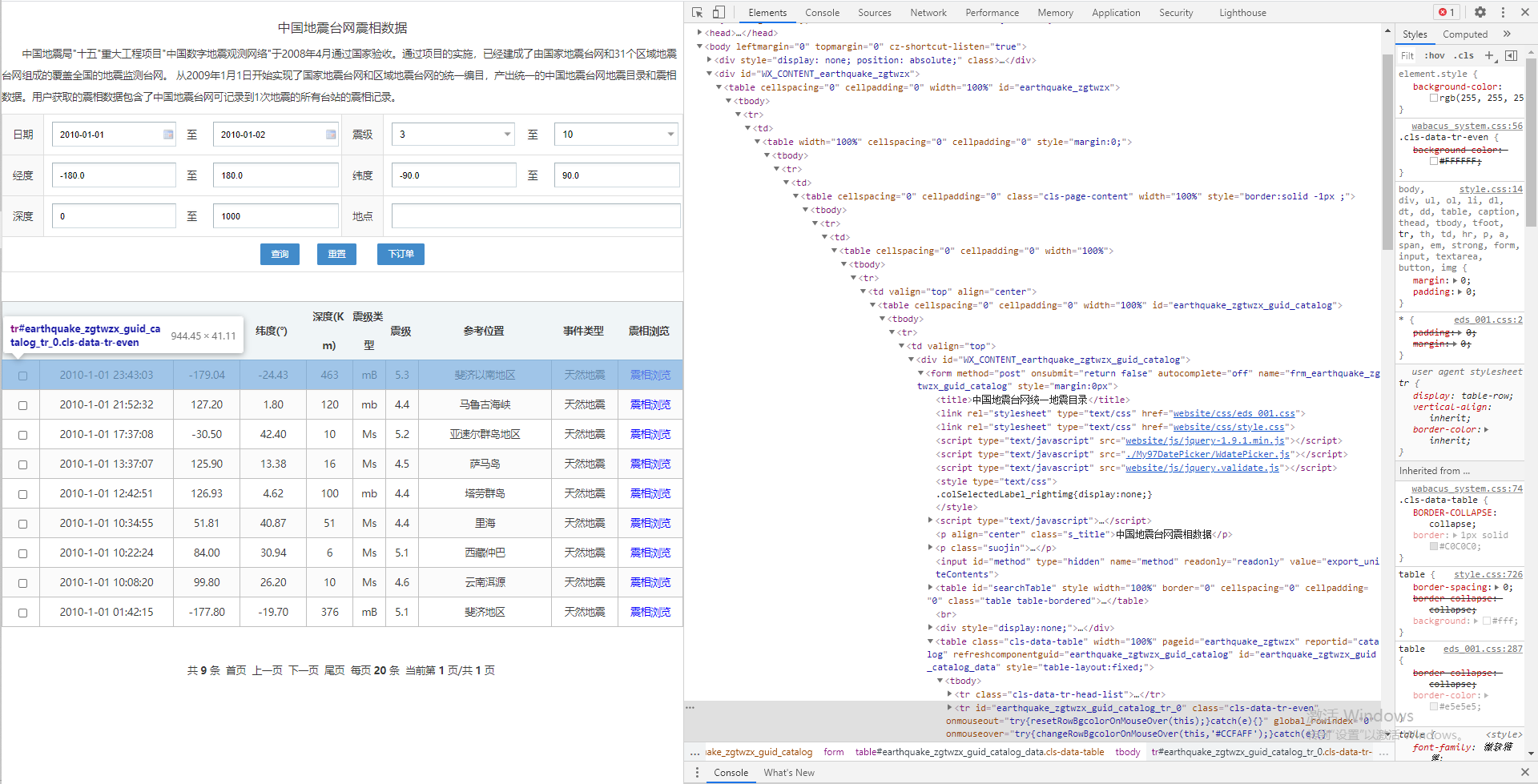
经过探索,我们发现每一行和列的文本id号都有规律,例如第一行斐济地震的发震时刻元素所在的行id是 <tr id="earthquake_zgtwzx_guid_catalog_tr_0"> 所在列id是 <td id="earthquake_zgtwzx_guid_catalog_wxcol_O_time__td0" > 而发震时刻数据储存在元素td的value属性中 <td value="2010-1-01 23:43:03">
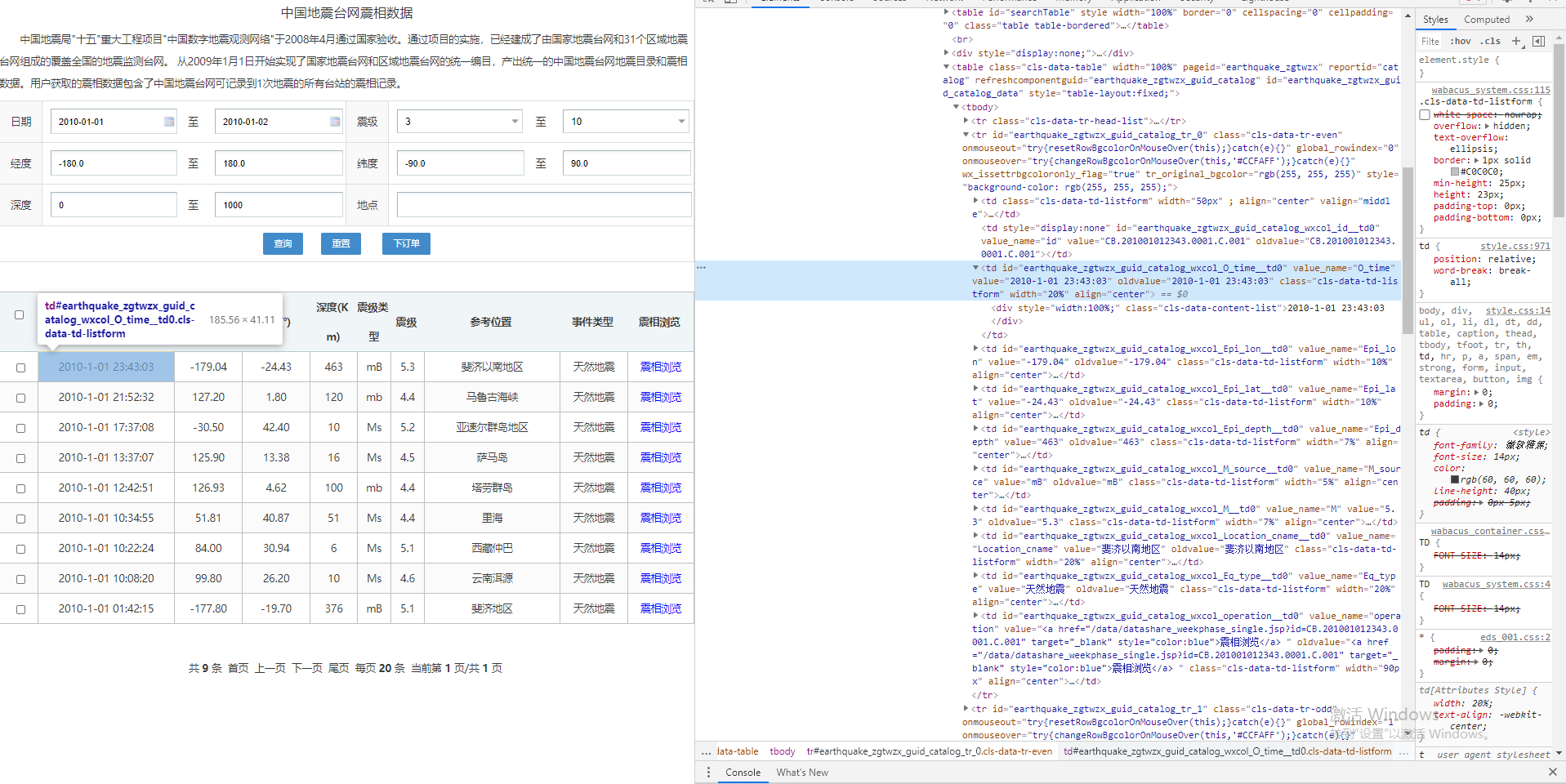
因此,只需要一个搜索过滤命令即可从全部的网页内容中获取自己想要的某个数据了
step 04 搜索过滤数据
搜索和过滤的命令是find,改日再写。
标签:语言 margin ref info 元素 节点 ash 分支 支持
原文地址:https://www.cnblogs.com/liangxuran/p/14528048.html