标签:简化 push 入栈 数据 lse 接下来 策略 思考 出栈
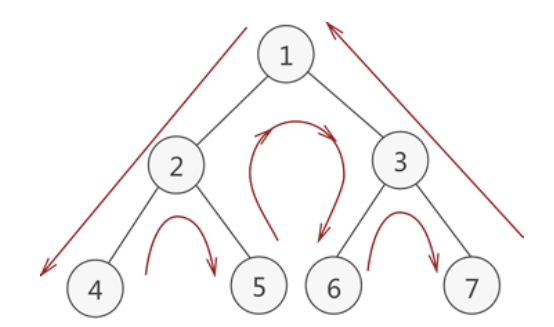
每个节点会被经过3次,前序、中序、后序的区别在于:在哪一次经过该节点时对其进行访问。
traverseRecursive(BiTrNode<T>* node): basecase: if(node == nullptr) return; general: 1 print(node->data); 2 traverseRecursive(node->lchild); 3 traverseRecursive(node->rchild); 前序:123 中序:213 后序:132
首先需要明确的是,所谓的递归实现其实是在模拟递归栈,所以使用的基本数据结构是stack。
这里如何设计节点的入栈策略是关键,因为执行的时候无非就是依次从stack中取出栈顶元素进行处理,所以stack中节点的入栈顺序就是访问顺序。
那既然我们已经知道了,每个节点都会被经过3次,所谓前序、中序、后序的区别无非就是第几次经过时对其进行操作(这里我们把对节点的操作简化成print node->data)。
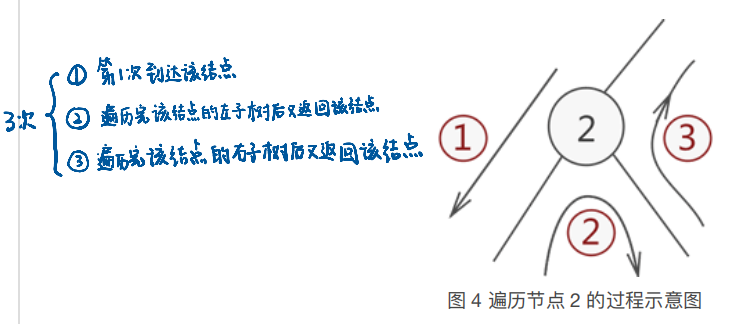
给每一个节点增加一个字段(lookTimes)表示这是第几次经过该节点。
模拟一下3次经过的入栈顺序:①第一次经过该节点 -> ②遍历该节点的左孩子 -> ③回到该节点(第二次经过)-> ④遍历该节点的右孩子 -> ⑤回到该节点(第三次经过)。
init:所有节点的lookTimes都设为0,将根节点入栈。
从stack中取出栈顶元素表示经过一次该节点(lookTimes++),然后看lookTimes进行相应的操作:
模拟好3次经过之后,要实现前序/中序/后序遍历只需在每一次push前print(node->data)就可以了。比如,如果是前序遍历就在p->lookTimes == 1的if语句块的第一行加上print(node->data)就可以了。
伪码如下:
//version1.0 while(stack is not empty){ p = stack.pop(); (p->lookTimes)++; if(p->lookTimes == 1){ //print(p->data); 前序遍历 stack.push(p); if(p->lchild) stack.push(p->lchild); }else if(p->lookTimes == 2){ //print(p->data); 中序遍历 stack.push(p); if(p->lchild) stack.push(p->rchild); }else if(p->lookTimes == 3){ //print(p->data); 后序遍历 } }
上面是一种比较通用的想法,但是在考虑到具体的某一种遍历方式时,比如前序遍历:既然在lookTimes == 1时就已经对该节点进行访问了,那么后面的两次回到该节点显然是没有必要的。
因此根据每一种遍历方式的特点进行优化:
1. 前序
入栈顺序:①第一次经过该节点 -> ②遍历该节点的左孩子 -> ③遍历该节点的右孩子。而且这样的话每个节点只会经过一次,lookTimes字段也就没有必要了。
//前序遍历_version2.0:without lookTimes while(stack is not empty){ p = stack.pop(); print(p->data); if(p->lchild) stack.push(p->lchild); if(p->rchild) stack.push(p->rchild); }
2. 中序
入栈顺序:①第一次经过该节点 -> ②遍历该节点的左孩子 -> ③回到该节点(第二次经过)-> ④遍历该节点的右孩子。
//中序遍历_version2.0 while(stack is not empty){ p = stack.pop(); (p->lookTimes)++; if(p->lookTimes == 1){ stack.push(p); if(p->lchild) stack.push(p->lchild); }else if(p->lookTimes == 2){ print(p->data); if(p->lchild) stack.push(p->rchild); } }
3. 后序
后序因为在第三次经过时才会访问,所以不能再优化了。
标签:简化 push 入栈 数据 lse 接下来 策略 思考 出栈
原文地址:https://www.cnblogs.com/zyx-shadow/p/14528330.html