标签:条件 字符串类 位置参数变量 header continue sql href 输入 src
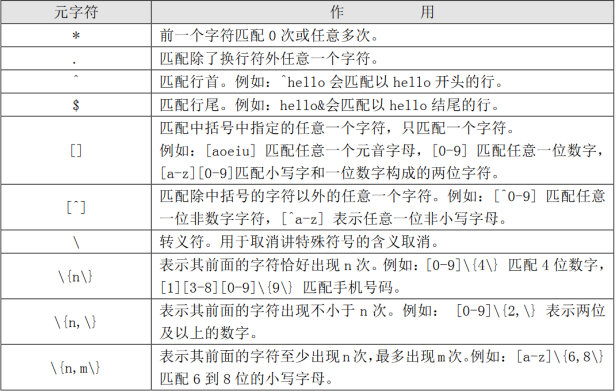
. # 匹配换行符以外的任意一个字符
正则表达式“.”只能匹配一个字符,但可以是任意字符
[ ]# 匹配中括号中任意一个字符,注意只能匹配一个字符
* # 前一个字符匹配任意多次
如果正则表达式写成“aa*” 代表匹配至少包含有一个a的行
\? # 匹配前一个字符出现0次或者1次
\{n\}表示前面的字符恰好出现n次
\{n,\} 表示其前面的字符出现不小于n次
\{n,m\} 匹配其前面的字符出现不小于n次,最多出现m次
^ # 匹配行首
$ # 匹配行尾
用“^$”匹配空白行
\(字符串)将括号内的内容当做一个整体
(dog)* 用来匹配出现任意次数的dog字符串
(dog)\? 用来匹配dog字符串出现一次或者不出现

格式:cut[选项]文件名
-f 列号:提取第几列,默认识别制表符分割出来的列
-d 分隔符:按照指定的分割符进行分割,然后结合-f提取指定列
-c 字符范围:不依赖分割符来分割,而是通过字符范围进行提取
n-m表示从第n提取到第m个字符
n-表示从第n个字符开始提取到结尾
-m表示从第一个字符提取到第m个
awk是一种编程语言,用于在linux/unix中对文本和数据进行处理,awk既可以实现对文件的行提取,也可以实现对文件的列提取,是一个很全面的工具,此处我们只讲在Linux中如何利用awk进行字符串过滤,不讲过多关于awk编程的内容。
格式:awk ‘条件1{动作1}’ 文件名
条件的作用:通过指定条件过滤出符合条件的行
动作的作用:通过动作将符合条件的行打印出来,不过在打印时我们可以选择打印该行中的哪些列
条件:通过关系表达式进行判断,过滤出符合条件的行
变量>10 :判断变量的值是否大于10;可使用>、<、>=、<=等
变量==变量 :判断两个变量的值是否相等;可使用==、!=等
变量~/字符串/ :判断变量中是否包含指定字符串,~// !~//
动作:将符合条件的内容进行格式化后输出到命令行
[root@localhost ~]# cat cut.txt
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
1 xbo 83 75 93
2 xlong 74 96 63
[root@localhost ~]# cut -f 2,3 cut.txt
NAME LINUX
xcang 95
xbo 83
xlong 74
[root@localhost ~]# awk ‘{printf $2"\t"$3"\n"}‘ cut.txt
NAME LINUX
xcang 95
xbo 83
xlong 74
\#不指定任何条件,直接执行动作,并选择输出哪些列
printf是标准的格式化输出,取消所有默认格式,然后手动指定输出内容的类型和输出时的格式
# printf输出格式:
printf ‘类型/格式’字符串
可以使用cat、head、tail等命令将文本内的字符串取出,然后交由printf处理
# 输出类型:
%s:将内容按照字符串类型输出
%i:将内容按照整数类型输出
%f:将内容按照浮点数类型输出(%.2f:代表输出小数点数值时保留两位小数点)
# 输出格式:
\t:字符之间用制表符分割,即tab键
\n:字符之间用换行符分割,即enter键
# 案例演示:
使用printf输出下我们的表格文件
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
1 xbo 83 75 93
2 xlong 74 96 63
[root@localhost ~]# printf ‘%s‘ `cat cut.txt`
IDNAMELINUXMYSQLDOCKER0xcang9559781xbo8375932xlong749663[root@localhost ~]#
在使用printf输出时,如果仅指定输出类型,而不指定输出格式,则会把所有要输出内容连在一起输出,变为一整行。而printf提供了可自定义的灵活的输出格式,若要将内容按照原格式输出,我们需要自己为printf写格式。
[root@localhost ~]# printf ‘%s\t%s\t%s\t%s\t%s\n‘ `cat cut.txt`
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
1 xbo 83 75 93
2 xlong 74 96 63
假若我们在输出时,想让第1列使用整数类型输出,3,4,5列使用浮点类型输出如何操作?
[root@localhost ~]# printf ‘%i\t%s\t%.2f\t%.2f\t%.2f\n‘ `cat cut.txt`
-bash: printf: ID: invalid number
-bash: printf: LINUX: invalid number
-bash: printf: MYSQL: invalid number
-bash: printf: DOCKER: invalid number
0 NAME 0.00 0.00 0.00
0 xcang 95.00 59.00 78.00
1 xbo 83.00 75.00 93.00
2 xlong 74.00 96.00 63.00
[root@localhost ~]# printf ‘%i\t%s\t%.2f\t%.2f\t%.2f\n‘ `cat cut.txt|grep -v ID`
0 xcang 95.00 59.00 78.00
1 xbo 83.00 75.00 93.00
2 xlong 74.00 96.00 63.00
# awk预定义条件(保留字)
这两个条件为系统预设好的特殊条件,必须用大写,切记~!
BEGIN:在awk未读取数据前声明的动作,该条件后的动作仅在程序开始时执行一次,不会重复执行
[root@localhost ~]# awk ‘BEGIN{printf "MYSQL成绩单:\n"}{printf $2"\t"$4"\n"}‘ cut.txt
MYSQL成绩单:
NAME MYSQL
xcang 59
xbo 75
xlong 96
[root@localhost ~]# awk ‘BEGIN{FS=":"}{printf $1"\t"$7"\n"}‘ /etc/passwd
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
END类似于BEGIN,在awk处理完所有数据后声明的条件,在该条件后的程序仅在程序结束前执行一次
[root@localhost ~]# awk ‘{printf $2"\t"$5"\n"}END{printf "以上显示的是所有人的DOCKER成绩\n"}‘ cut.txt
NAME DOCKER
xcang 78
xbo 93
xlong 63
以上显示的是所有人的DOCKER成绩
# awk关系运算条件
\>、<、>=、<=、==、!=
用来判断左右两侧的关系,一般左侧为变量,右侧为参考值。
例1:列出Linux成绩大于等于80分的成绩单
[root@localhost ~]# awk ‘BEGIN{printf "列出Linux成绩大于等于80分的成绩单:\n"} $3>=80{printf $2"\t"$3"\n"}‘ cut.txt
列出Linux成绩大于80分的成绩单:
NAME LINUX
xcang 95
xbo 83
例2:列出学号为2号的各科成绩单
[root@localhost ~]# awk ‘$1==2{printf $0"\n"}‘ cut.txt
2 xlong 74 96 63
# awk包含匹配条件
~、!~、~//、!~//
用来进行匹配包含关系的,判断左侧变量中是否包含右侧的字符串,当右侧字符串中包含一些特殊符号时,需要使用//然后在里面使用\转义符将符号转义为普通字符。
[root@localhost ~]# cat cuta.txt
ID NAME LINUX MYSQL DOCKER MAIL
0 xcang 95 59 78 xcang@163.com
1 xbo 83 75 93 boduo@126.com.cn
2 xlong 74 96 63 zeze@gmail.com
[root@localhost ~]# awk ‘$6~/x/{printf $0"\n"}‘ cuta.txt
0 xcang 95 59 78 xcang@163.com
[root@localhost ~]# awk ‘/x/{printf $0"\n"}‘ cuta.txt
0 xcang 95 59 78 xcang@163.com
1 xbo 83 75 93 boduo@126.com.cn
2 xlong 74 96 63 zeze@gmail.com
[root@localhost ~]# awk ‘$0~/\.com$/{printf $0"\n"}‘ cuta.txt
0 xcang 95 59 78 xcang@163.com
2 xlong 74 96 63 zeze@gmail.com
[root@localhost ~]# df -h | awk ‘/(sd|sr)[a-z]?[0-9]/{printf $1"\t"$5"\n"}‘
/dev/sr0 100%
/dev/sda1 15%
# 总结:awk的工作原理
先查看是否有BEGIN条件,有则先执行BEGIN后面定义动作
如果没有BEGIN条件,则先读入第一行,把第一行的数据使用分隔符分隔好之后依次依次赋值给变量$0 $1 $2 $3 ...等变量,$0 代表整行数据,$1 则为第一个字段,依次类推(有点类似于位置参数变量)。
第一行将所有内容赋值完成后,进行条件判断,按照符合条件的动作执行
处理完第一行之后,将第二行赋值,重复第一行的所有步骤即可,依次直到处理完整个文本
| awk内置变量 | 作用 |
|---|---|
| $0 | 代表awk读入当前行的整行数据 |
| $n | 代表awk读入当前行的第n列数据 |
| NR | 代表当前awk正在处理的行的行号 |
| NF | 代表当前awk读取数据总字段数(总列数) |
| FS | 用来声明awk的分隔符,如BEGIN {FS=“:”} |
[root@localhost ~]# awk ‘NR>1{printf $0"\n"}‘ cuta.txt
0 xcang 95 59 78 xcang@163.com
1 xbo 83 75 93 boduo@126.com.cn
2 xlong 74 96 63 zeze@gmail.com
[root@localhost ~]# awk ‘END{printf "文件的总列数为:"NF"\n"}‘ cuta.txt
文件的总列数为:6
\#统计指定文件的最后一行的列数
[root@localhost network-scripts]# echo $PWD|awk -F / ‘{printf $NF"\n"}‘
network-scripts
\#打印以/为分割符号内容的最后一列
awk中默认支持数值运算,并且整数、浮点数运算都支持
[root@localhost ~]# awk ‘NR>1{printf $2"的平均分是\t"($3+$4+$5)/3"\n"}‘ cuta.txt
xcang的平均分是 77.3333
xbo的平均分是 83.6667
xlong的平均分是 77.6667
[root@localhost ~]# printf ‘%s\t%.2f\n‘ `awk ‘NR>1{printf $2"的平均分是\t"($3+$4+$5)/3"\n"}‘ cuta.txt`
xcang的平均分是 77.33
xbo的平均分是 83.67
xlong的平均分是 77.67
[root@localhost ~]# c=$(awk ‘BEGIN{print 7.01*5-4.01 }‘)
[root@localhost ~]# echo $c
31.04
注意事项:在awk编程中,因为命令语句非常长,输入格式时需要注意以下内容
多个【条件{动作}】可以用空格分割
在一个动作中,如果需要执行多个命令,需要用“;”分割
在awk中,变量的赋值与调用都不需要使用“$”符
判断两个值是否相同,使用“==”,以便和变量赋值进行区分
sed的主要功能是实现数据选取、替换、删除、新增等操作的命令,我们一般来使用sed命令实现非交互式文件内容修改,即不进入文本内对文件内容修改。
# 选项:
-n:将经过sed命令处理过的数据输出到命令行(不加-n则输出全文+指定行)
-i:用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出
# 动作:
p:打印,输出指定的行,例如:2p,就是输出第二行
a:追加,在当前行后追加一行或多行。追加多行时,除最后一行外,行尾要使用\强制换行符。
i:插入,在当期行前插入一行或多行。插入多行时,除最后一行外,行尾要使用\强制换行符。
c:整行替换,用c后面的字符串替换原数据行,替换多行时,除最后一行外,行尾要使用\强制换行符。
d:删除,删除指定的行,删除多行时可使用:2,5d的格式。
s:字串替换,用一个字符串替换另外一个字符串。格式为“行范围s/旧字串/新字串/g”( 和vim中的替换格式类似)
注意:sed所有的修改默认都不会直接修改文件的内容,而是在内存中进行处理然后打印到屏幕上,使用 -i 选项才会保存到文本中。
# 显示某行的信息:sed ‘2p’文件**
[root@localhost ~]# sed ‘2p‘ cut.txt
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
0 xcang 95 59 78
1 xbo 83 75 93
2 xlong 74 96 63
[root@localhost ~]#
[root@localhost ~]# sed -n ‘2p‘ cut.txt
0 xcang 95 59 78
# 删除数据:sed ‘2,4d’文件
[root@localhost ~]# sed ‘2,3d‘ cut.txt
ID NAME LINUX MYSQL DOCKER
2 xlong 74 96 63
[root@localhost ~]# cat cut.txt
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
1 xbo 83 75 93
2 xlong 74 96 63
用sed 删除掉的文件内容并没有真的修改文件
# 追加、插入数据:sed ‘2[a|i]’ 文件名
[root@localhost ~]# sed ‘2a hello‘ cut.txt
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
hello
1 xbo 83 75 93
2 xlong 74 96 63
[root@localhost ~]# sed ‘2i hello‘ cut.txt
ID NAME LINUX MYSQL DOCKER
hello
0 xcang 95 59 78
1 xbo 83 75 93
2 xlong 74 96 63
a 在指定行后面追加,i 在指定行前面插入
[root@localhost ~]# sed ‘2i hello\> world‘ cut.txt
ID NAME LINUX MYSQL DOCKER
hello
world
0 xcang 95 59 78
1 xbo 83 75 93
2 xlong 74 96 63
假如要追加多行,则需要用 \ 作为一行的结束,最后一行不需要。
# 整行替换数据:sed ‘2c No such person’
[root@localhost ~]# sed ‘2c hello‘ cut.txt
ID NAME LINUX MYSQL DOCKER
No such person
1 xbo 83 75 93
2 xlong 74 96 63
# 字符串替换:sed** **‘ns/old/new/g’ 文件名
[root@localhost ~]# sed ‘4s/xlong/zeze/‘ cut.txt
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
1 xbo 83 75 93
2 zeze 74 96 63
# 将指定内容替换成空
[root@localhost ~]# sed ‘4s/[0-9]//g‘ cut.txt
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
1 xbo 83 75 93
xlong
sed 要进行多行操作时,用;或回车分隔。
[root@localhost ~]# sed ‘3s/^/#/;4s/[0-9]//g‘ cut.txt
ID NAME LINUX MYSQL DOCKER
0 xcang 95 59 78
\#1 xbo 83 75 93
xlong
# sort 选项 文件名
-f 忽略大小写
-b 忽略每行前的空白部分
-n 以数值型进行排序,默认使用字符串类型排序
-r 反向排序
-u 删除重复行(=下面的uniq)
-t 指定分隔符,默认分割符是制表符
-k n:指定使用第几列的内容进行排序,一般和-t结合使用
注意:sort 命令默认使用每行开头第一个字符进行排序
# 案例展示
[root@localhost ~]# sort pass.txt
Adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]#
[root@localhost ~]# sort -f pass.txt #忽略大小写
daemon:x:2:2:daemon:/sbin:/sbin/nologin
Adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
:x:0:0:root:/root:/bin/bash
[root@localhost ~]#
[root@localhost ~]# sort -bf pass.txt #忽略大小写和行前空白
Adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]#
[root@localhost ~]# sort -t: -k 3 -n pass.txt #冒号分隔符,第三列,从小到大
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
Adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost ~]#
[root@localhost ~]# sort -t: -k 3 -rn pass.txt #以数值方式反向排序,从大到小
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
Adm:x:3:4:adm:/var/adm:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
uniq用来取消重复行,与sort -u 功能是一样的
# 格式:uniq 选项 文件名
-i 忽略大小写
-c 在关键词旁显示该关键词出现的次数(一般针对行)
需要注意的是,当重复行不连续时,uniq是不生效的,需要先排序,再执行
[root@localhost ~]# cat xxoo.txt
Linux 30
unix 20
windows 50
windows 50
Linux 30
windows 50
[root@localhost ~]# uniq xxoo.txt
Linux 30
unix 20
50
Linux 30
windows 50
[root@localhost ~]# sort xxoo.txt | uniq
Linux 30
unix 20
50
[root@localhost ~]# sort xxoo.txt | uniq -c
2 Linux 30
1 unix 20
3 windows 50
[root@localhost ~]# sort xxoo.txt | uniq -c | sort -rn
3 windows 50
2 Linux 30
1 unix 20
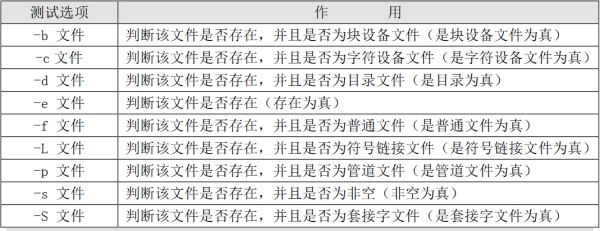
使用 [ ] 括号来进行判断,利用 $? 来检测判断结果
[root@localhost ~]# [ -e /tmp ] && echo yes || echo no
yes
[root@localhost ~]# [ -e /tmpe ] && echo yes || echo no
no
\#注意 [ ] 中内容和括号之间有空格,我们结合之前所学的 && 和 || 实现

测试:
[root@localhost ~]# ll xo.txt
-rw-r--r-- 1 root root 59 5月 11 14:46 xo.txt
[root@localhost ~]#
[root@localhost ~]# [ -r xo.txt ] && echo yes || echo no
yes
[root@localhost ~]#
[root@localhost ~]# ll /usr/bin/passwd
-rwsr-xr-x. 1 root root 27832 6月 10 2014 /usr/bin/passwd
[root@localhost ~]#
[root@localhost ~]# [ -u /usr/bin/passwd ] && echo yes || echo no
yes

判断下我们的硬链接
[root@localhost ~]# ln xo.txt /tmp/
[root@localhost ~]#
[root@localhost ~]# [ /root/xo.txt -ef /tmp/xo.txt ] && echo yes || echo no
yes
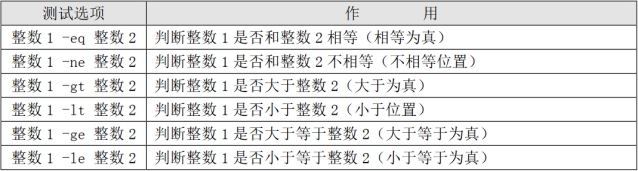
测试
[root@localhost ~]# [ 11 -ge 22 ] && echo yes || echo no
no
[root@localhost ~]#
[root@localhost ~]# [ 22 -ge 11 ] && echo yes || echo no
yes

测试
[root@localhost ~]# name=shanchuan
[root@localhost ~]# age=""
[root@localhost ~]# unset sex
[root@localhost ~]#
[root@localhost ~]# [ -z "$name" ] && echo yes || echo no
no
[root@localhost ~]#
[root@localhost ~]# [ -z "$age" ] && echo yes || echo no
yes
[root@localhost ~]#
[root@localhost ~]# [ -z "$sex" ] && echo yes || echo no
yes
\#字符为空和没有赋值都为空
[root@localhost ~]# a=123
[root@localhost ~]# b=456
[root@localhost ~]#
[root@localhost ~]# [ "$a" == "$b" ] && echo yes || echo no
no

测试:逻辑与
[root@localhost ~]# a=100
[root@localhost ~]# [ -n "$a" -a "$a" -gt 150 ] && echo yes || echo no
no
[root@localhost ~]#
[root@localhost ~]# a=200
[root@localhost ~]# [ -n "$a" -a "$a" -gt 150 ] && echo yes || echo no
yes
逻辑非
[root@localhost ~]# a=100
[root@localhost ~]# [ -n "$a" ] && echo yes || echo no
yes
[root@localhost ~]#
[root@localhost ~]# [ ! -n "$a" ] && echo yes || echo no
no
-n 变量不为空,则为真,加入!后,判断取反,所以变量为空才是真
注意:! 和 判断条件之间有个空格
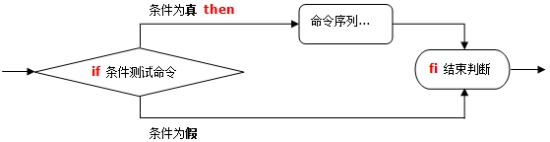
单分支条件语句比较简单,只需要一个判断条件,符合则执行,不符合则直接退出。
# 格式:
if [ 条件判断式 ];then
程序
fi
注意事项:
if 语句使用fi结尾,和一般语言使用大括号结尾不一样
[ 条件判断式 ] 就是使用test 命令进行判断,所以中括号和条件判断式之间必须有空格
then 后面跟符合条件后执行的程序,可以放在 [ ] 之后,加;隔开。也可以使用换行写入(用换行就不必写;了)
# 格式二:
if [ 条件判断式 ]
then
程序
fi
统计根分区使用率?
\#!/bin/bash
rootused=$(df -h | awk ‘/\/$/{printf $5"\n"}‘|cut -d% -f1)
if [ $rootused -gt 55 ]
then
echo -e "rootused -gt 55%;used:$rootused%"
fi
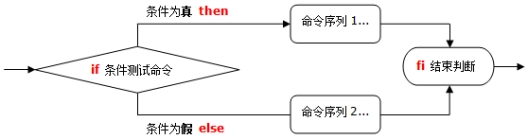
格式:
if [条件判断式]
then
条件成立,执行的程序
else
条件不成立,执行的程序
fi
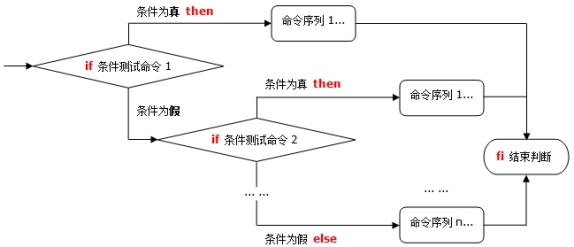
格式:
if [条件判断式1]
then
条件判断式1成立,执行程序1
elif [条件判断式2]
then
条件判断式2成立,执行程序2
更多………
else
都不成立,则执行此程序
fi
case语句和if...elif...else语句一样都是多分支条件语句,不过和if多分支条件语句不同的是,case语句只能判断一种条件关系,而if语句可以判断多种条件关系。
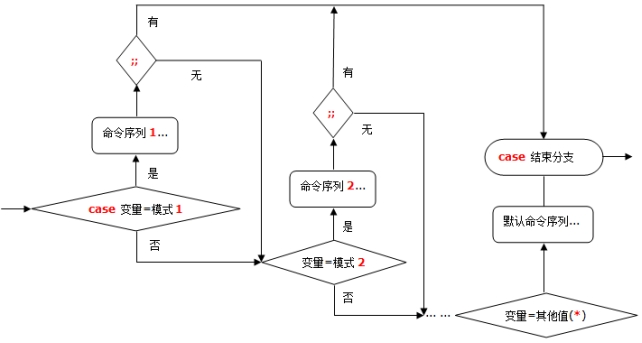
case语句语法如下:
case $变量名 in
值1)
变量的值等于值1,则执行程序1
;;
值2)
变量的值等于2,则执行程序2
;;
省略多个分支…………
*)
变量的值都不匹配上面的值,则执行此程序
;;
esac
注意事项
case语句,会取出变量中的值,然后与语句体中的值逐一比较。如果值符合,则执行对应的程序,如果值不符,则依次比较下一个值。如果所有的值都不符合,则执行“*)”(“*”代表所有其他值)中的程序。
case 语句以case开头,以esac结尾(切记……)
每一个分支需要用;; 束,注意是everyone!!!
for循环是固定循环,循环次数是有限的次数,也叫计数循环。
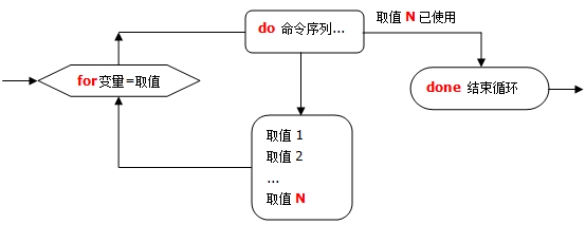
语法一:
for 变量 in 值1 值2 值3 ……
do
程序
done
注:这种语法中for循环的次数,取决于in后面值的个数(空格分隔),有几个值就循环几次,并且每次循环都把值赋予变量。也就是说,假设in后面有三个值,for会循环三次,第一次循环会把值1赋予变量,第二次循环会把值2赋予变量,依次类推。
语法二:
for ((初始值;循环控制条件;变量变化))
do
程序
done
注:
初始值:在循环开始时,需要给某个变量赋予初始值,如i=1;
循环控制条件:用于指定变量循环的次数,如i<=100,则只要i的值小于等于100,循环就会继续;
变量变化:每次循环之后,变量该如何变化,如i=i+1。代表每次循环之后,变量i的值都加1。
只要条件判断式成立,循环就会一直继续,直到条件判断式不成立,循环才会停止。
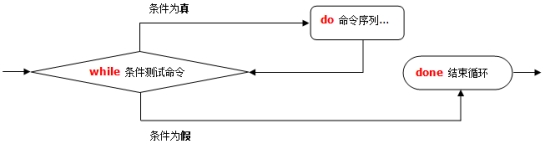
语法:
while [ 条件判断式 ]
do
程序
done
until循环和while循环相反,只要条件判断式不成立,则一直循环,什么时候成立,什么时候结束循环
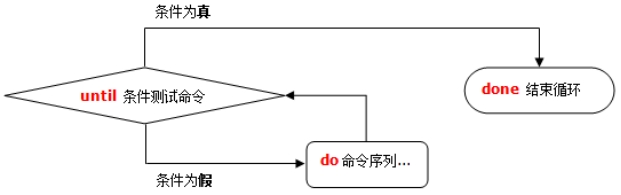
语法:
until [ 条件判断式 ]
do
程序
done
语法:
function 函数名 () {
程序
}
系统中的exit是退出当前登录,但是在shell中则只是退出脚本,回到Linux命令行。
exit [ 值 ]
exit 退出时如果定义好了返回值,那么我们可以通过“$?”来查看
当程序执行到break 语句时,会结束当前的循环程序,执行循环程序后面的程序。
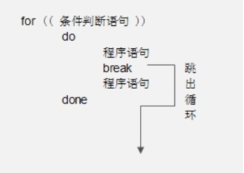
当break处在多层循环中时,可以通过break n的方式选择跳出的层数。
continue则仅是结束当前循环程序中的本次循环(单次循环),然后继续进行下次循环。
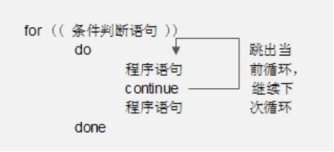
同样,continue可以使用continue n的方式选择在多层循环中退出的层数,n的大小影响continue的退出层数。
标签:条件 字符串类 位置参数变量 header continue sql href 输入 src
原文地址:https://www.cnblogs.com/wang-yy/p/14539550.html