标签:统计 设定 real conf 通用 linux 均衡负载 orm 代码
1. 集群和分布式:
集群(cluster):即同一个业务系统,部署在堕胎服务器上,集群中,每台服务器实现的功能没有差别,数据和代码都是一样的
集群主要分为三种类型:
LB(load balancing):负载均衡,多台主机组成,每个主机只承担一部分请求
HA(high availablity):高可用,避免SPOF(single point of failure),单点失败
HPC(high-preformance computing),高性能。
分布式:一个业务被拆分为多个子业务,或者本身就是不同的业务,部署在多台服务器上,分布式中,每台服务器实现的功能是有差别的,数据和代码也是不一样的。分布式中,每台服务器上的功能加起来,才是完整的业务。
分布式系统:
分布式存储:ceph,clusterFS,mogileFS
分布式计算:hadoop,spark
分布式常见应用:
分布式应用---->服务按照功能拆分,使用微服务
分布式静态资源------------>静态资源放在不要的存储集群上
分布式数据和存储----------------->使用k/v缓存系统
分布式计算---------------------->对特殊业务使用分布式计算,比如hadoop集群
区别:分布式是以缩短单个任务的执行时间来提示效率,而集群则是通过提高单位内执行任务数来提升效率。
对于大型网站,访问用户很多,实现一个集群,在前面部署一个负载均衡服务器,后面几台服务器完成同以业务。如果有用户进行相应业务访问时,负载均衡器根据后端那台服务器的负载情况,决定由那一台服务器取完成响应,并且一台服务器掉了,其他服务器可以顶上来。 分布式的每一个节点,都完成不同的业务,如果一个节点掉了,那么整个业务可能就会失败。
1.2 系统性能扩展方式:
垂直扩展:(scale up):或又叫向上扩展,提示计算机的硬件(一般用性能更强的计算机来运行同样的服务,但是单台计算机的性能提示是有上限的,不可能无限的向上扩展,而且其价格也会成倍增长)
水平扩展(scale out),或又叫向外扩展,通过增加计算机的数量(服务器数量)。并行的运行多个服务调度分配问题(cluster)。
1.3 集群设计原则:
可扩展性----------------->主要是集群的横向扩展能力
可用性-------------------->无故障时间(SLA:service level argement)
SLA:服务等级协议,指在一定开开销下为保障服务的性能和可用性,服务提供商与用户定义的一种双方认可的协定。通常这个开销是驱动提供服务质量的主要因素。在常规的领域中,总是设定所谓的三个9,四个9来进行表示,当没有达到这中水平的时候,就会有一定的惩罚措施,而运维,最主要的目标就是达成这种服务水平。
计算方式:sla=MTBF/(MTBF+MTTR)
MTBF:(MEAN TIME BETWEEN FAILURE) 平均无故障时间,即正常时间
MTTR:(MEAN TIME TO RESTORATION) 平均故障恢复时间,即故障时间(停机时间:计划内停机时间,计划为停机时间。此处所指大部分为计划外停机时间)
性能------------------------>访问响应时间
容量------------------------>单位时间内的最大并发吞吐量(C10K并发问题)
1.4 集群设计实现:
基础设施层面:
提示硬件资源性能--------------从入口防火墙到后端web server均使用更高性能的硬件资源
多域名---------------------------->DNS轮询A记录
多入口------------------------------> 将a记录解析到多个公网ip入口
多机房--------------------------->同城+异地容灾
CDN(content delivery network)----------------->基于GSLB(global server balance) 实现全局负载均衡。
CDN:内容分发网络,通过中心平台的负载均衡,内容分发,调度等功能模块,使用户就近获取所需要的内容,降低网络拥塞,提供用户访问响应速度和命中率。主要是采用缓存技术和分发技术。
业务层面:
安全层,负载层,静态层,动态层(缓存层,存储层)持久化与非持久化(将内存中的数据保存至硬盘上)
分割:基于功能分割大业务为小服务
分布式:对于特殊场景下的业务,使用分布式计算
2. LB cluster 负载均衡集群
按照实现方式划分:
硬件:
F5 Big-IP
Citrix Netscaler
A10
软件:
lvs(linux virtual server),阿里四层SLB(server load balance) 使用
nginx:支持七层调度。阿里七层SLB使用Tengine
haproxy 支持七层调度
基于工作的协议层次划分
传输层(通用层):DNAT和DPORT
lvs
nginx
haproxy
应用层(专用):针对特定协议,常为proxy server
http:nginx,httpd,haproxy(mode http)
fastcgi:nginx,httpd
mysql: mysql_proxy,mycat
负载均衡的会话保持:
session sticky:同用户调度固定的服务器
source ip:LVS sh算法(对某特定的服务而言)
cookie
session replication:每台服务器拥有全部session
session multicast cluster
session server:专门的session服务器
memcached ,redis
3. linux virtual server 简介
lvs:linux virtual server 负载调度器,由内核集成,四层负载开源软件
官网:http://www.linuxvirtualserver.org/
阿里SLB和LVS
https://yq.aliyun.com/articles/1803
https://github.com/alibaba/LVS
负载均衡优点:
承载高并发,提示更高性能
可靠性,实现后端服务冗灾
负载均衡轮询协议(轮询,加权轮询,加权最小连接数)
会话保持(tcp会话保持基于ip;http协议会话保持基于cookie)
监控检查(lvs+keeplive),检查方式TCP协议,httpd协议
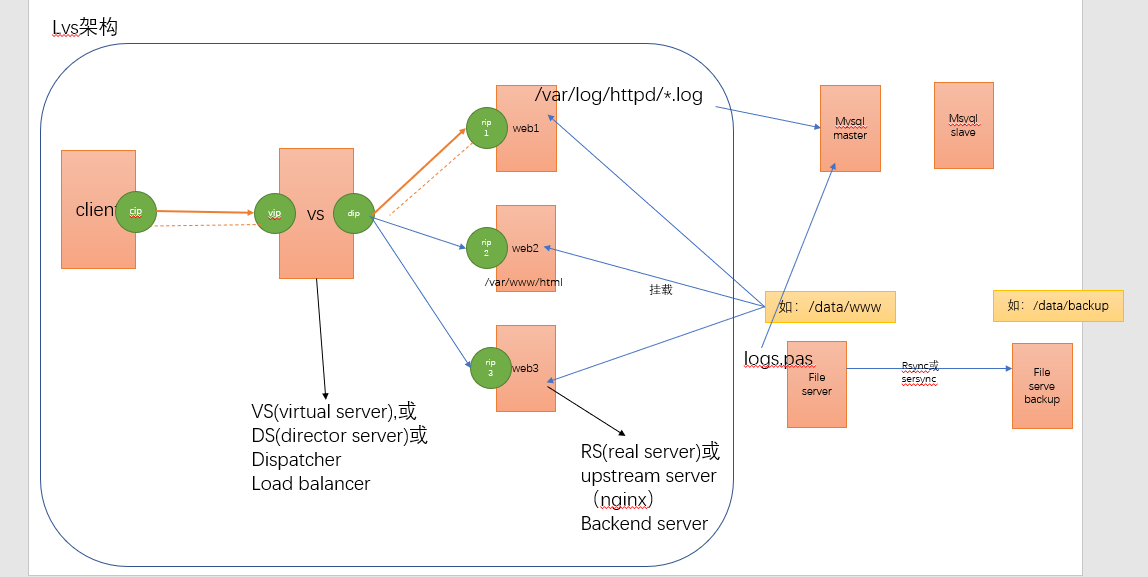
LVS架构
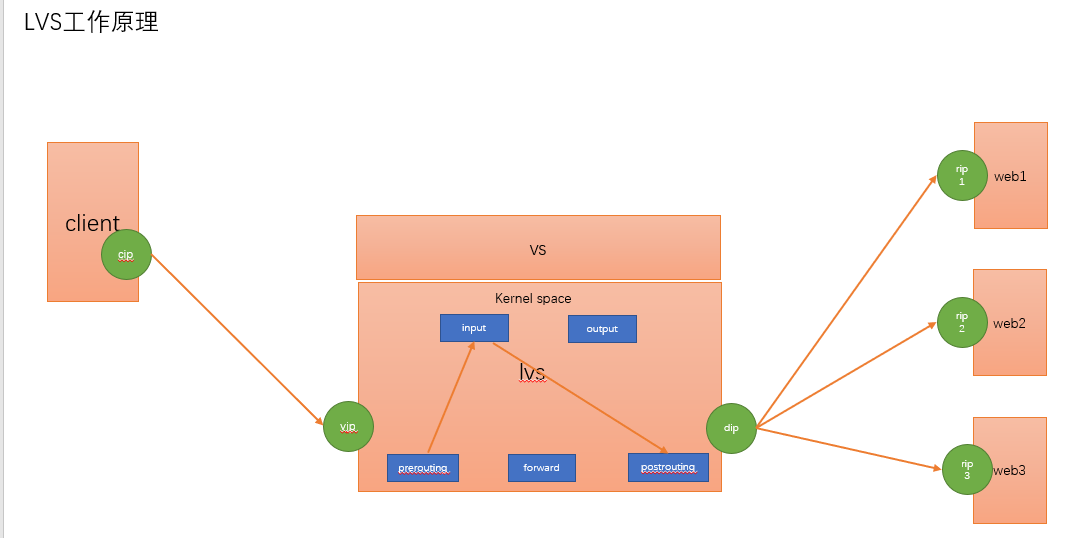
LVS工作原理:
vs根据请求报文的目标ip和目标协议及端口将其调度转发至某RS(根据调度算法来挑选RS)。LVS是内核及功能,工作在INPUT链的位置,将其发往INPUT的流量进行处理。
查看内核是否支持LVS:
#[root@localhost ~]# grep -i -C 10 ipvs /boot/config-4.18.0-80.el8.x86_64
LVS集群类型中的术语
vs
rs
cip
vip vs外网的ip
dip vs内网的ip
rip
4.LVS 工作模式和相关命令:
4.1 lvs集群的工作模式
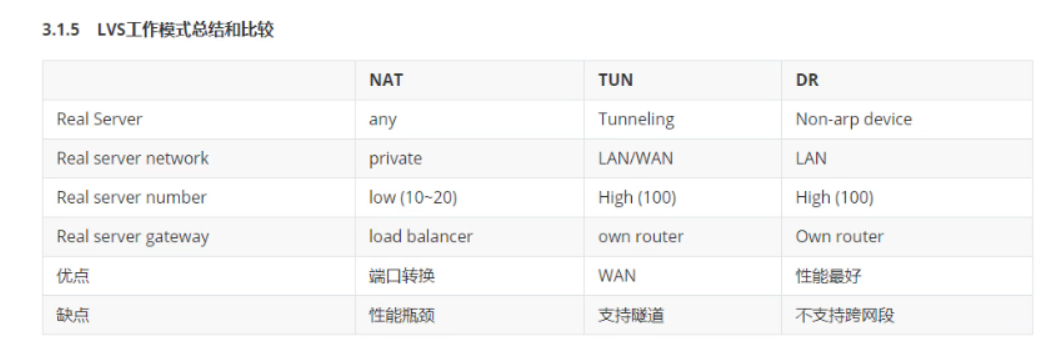
LVS-NAT:修改请求报文的目标ip,多目标ip的DNAT
LVS-DR:操纵封装新的MAC地址
LVS-TUN::在原请求报文之外新加一个ip首部
LVS-FULLNAMT:修改请求报文的源和目标ip
4.2 LVS的NAT模式:
思考:SNAT与DNAT
SNAT:当局域网内部的主机访问互联网时,需要将其源地址转换为公网地址,再用公网访问互联网;
DNAT:当互联网中的某台机器范围跟局域网内部的某台主机时,当请求到达局域网时,需要将其转换为局域网内部对应的主机的ip地址。
LVS-NAT 实现原理:(本质时多目标的DNAT,通过将亲贵报文中的目标地址和目标端口修改为某挑出的RS的RIP和PORT实现转发)
RIP和DIP应在在同一个IP网络(如果不在同一个网络中,会影响传输效率)。且使用私网地址,RS的网关要指向DIP
请求报文和响应报文都必须经由director转发,director易于成系统瓶颈
支持端口映射,可修改请求报文的目标port
VS必须时linux系统,RS可以是任意OS系统
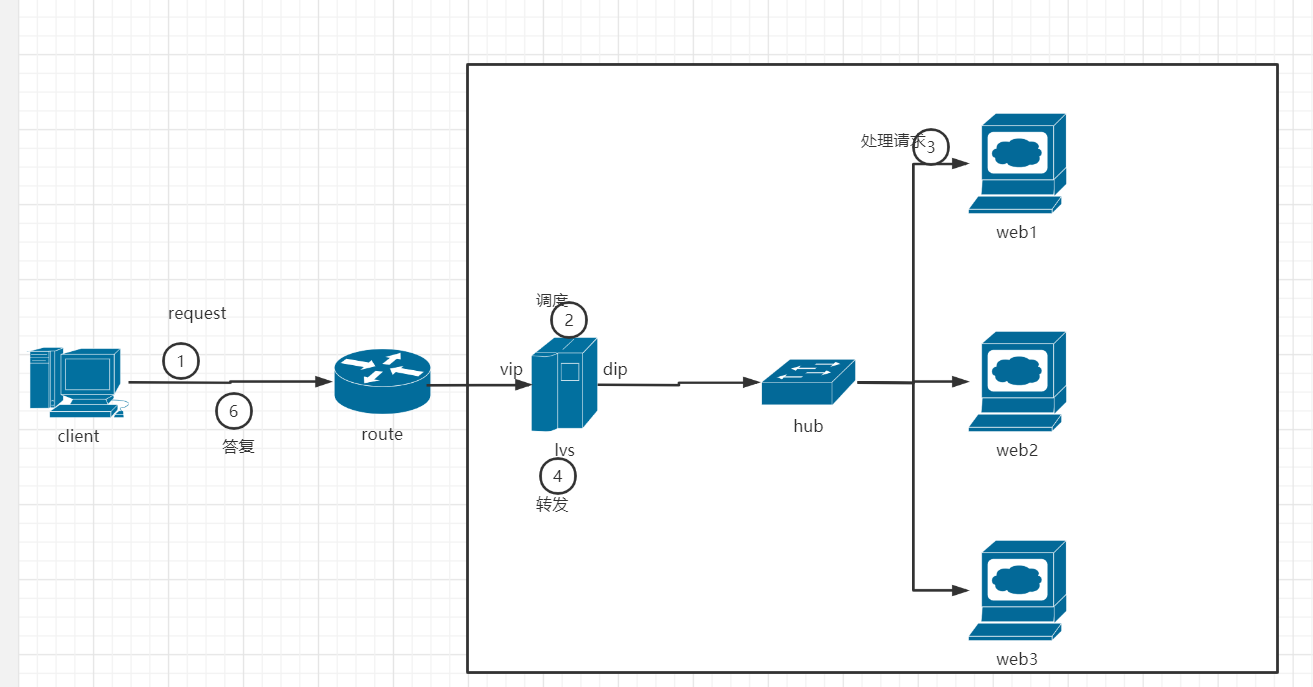
IP地址转换过程
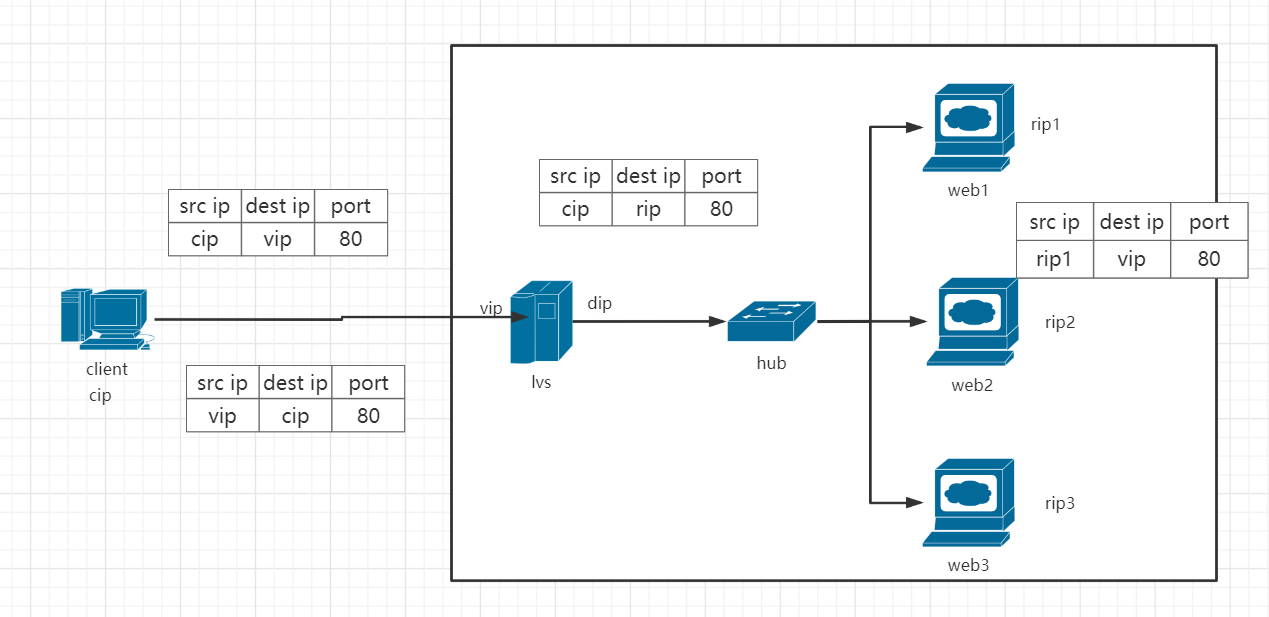
内核角度分析ip地址的转换过程
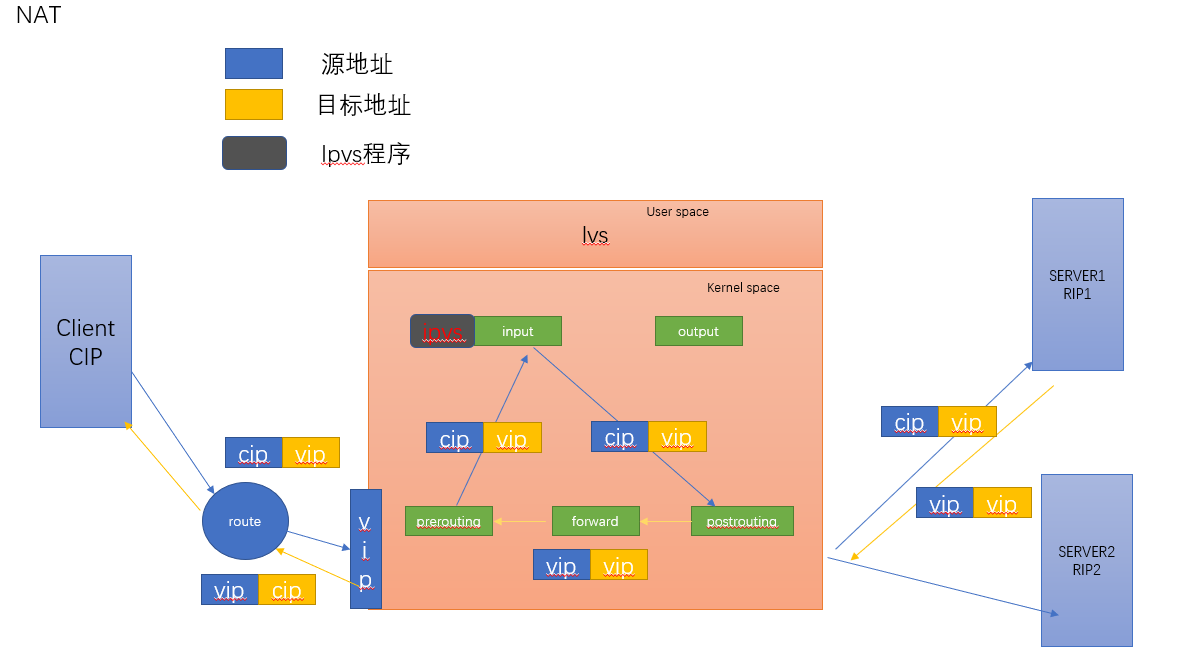
可以看出LVS-NAT模式缺陷:lvs容易成为系统瓶颈,负载任务量过大(请求和响应都需要经由lvs)
范例:实现NAT模式:脚本方式实现
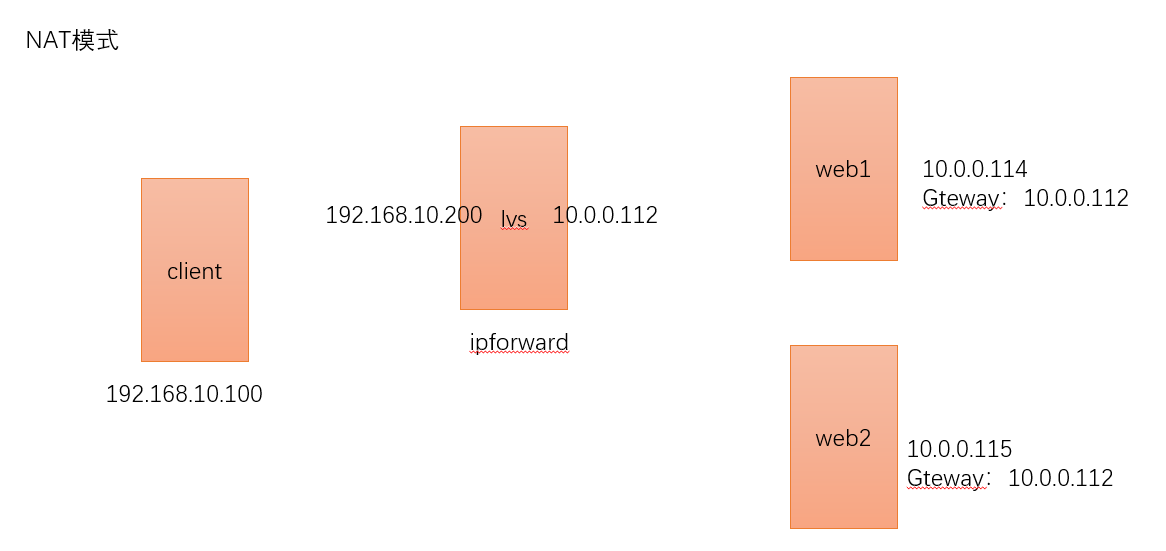
client端运行:需要修该网卡模式: 192.168.10.100
#!/bin/bash
#配合NAT模式搭建LVS,用于测试
#此脚本需要在client端运行,运行前需要修改网卡模式
IP_ADDRESS=192.168.10.100
PREFIX_NU=24
dev=ens33
cat > /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
TYPE="Ethernet"
IPADDR=${IP_ADDRESS}
PREFIX=${PREFIX_NU}
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
EOF
nmcli con reload && nmcli con up ${dev}
lvs端运行:10.0.0.112 #需要提前添加网卡(仅主机)
#!/bin/bash
#运行此脚本之前需要添加对应的网卡
PREFIX_NU=24 #地址掩码
dev0=ens33
IP_ADDRESS0=10.0.0.112 #dip地址
dev1=ens37
IP_ADDRESS1=192.168.10.200 #vip地址
scheduling=rr #调度算法
web_ipaddr1=10.0.0.114
web_ipaddr2=10.0.0.115
PORT=80
rpm -ql ipvsadm &> /dev/null || yum install -y -q ipvsadm
cat > /etc/sysconfig/network-scripts/ifcfg-${dev0} << EOF
TYPE="Ethernet"
IPADDR=${IP_ADDRESS0}
PREFIX=${PREFIX_NU}
NAME="${dev0}"
DEVICE="${dev0}"
ONBOOT="yes"
EOF
cat > /etc/sysconfig/network-scripts/ifcfg-${dev1} << EOF
TYPE="Ethernet"
IPADDR=${IP_ADDRESS1}
PREFIX=${PREFIX_NU}
NAME="${dev1}"
DEVICE="${dev1}"
ONBOOT="yes"
EOF
nmcli connection reload
nmcli connection up ${dev0}
nmcli connection up ${dev1}
ipvsadm -A -t ${IP_ADDRESS1}:${PORT} -s ${scheduling}
ipvsadm -a -t ${IP_ADDRESS1}:${PORT} -r ${web_ipaddr1}:${PORT} -m
ipvsadm -a -t ${IP_ADDRESS1}:${PORT} -r ${web_ipaddr2}:${PORT} -m
ipvsadm -Sn > /etc/sysconfig/ipvsadm
systemctl enable --now ipvsadm.service
cat > /etc/sysctl.conf <<EOF
net.ipv4.ipforward =1
EOF
sysctl -p
hostnamectl set-hostname lvs
web端运行(10.0.0.114)
#!/bin/bash
#运行此脚本
dev0=ens33
web_ipaddr=10.0.0.114 #dip地址
PREFIX_NU=24
comment="114"
GATEWAY=10.0.0.112
rpm -ql httpd &> /dev/null || yum install -y -q httpd
echo ${comment} > /var/www/html/index.html
cat > /etc/sysconfig/network-scripts/ifcfg-${dev0} << EOF
TYPE="Ethernet"
IPADDR=${web_ipaddr}
PREFIX=${PREFIX_NU}
NAME="${dev0}"
DEVICE="${dev0}"
GATEWAY=${GATEWAY}
ONBOOT="yes"
EOF
nmcli con reload
nmcli con up ${dev0}
systemctl enable --now httpd
hostnamectl set-hostname web1
4.3 VS-DR模式:
LVS-DR实现原理:(本质:通过为请求报文重新封装一个MAC首部进行转发,源MAC是DIP所在的接口的MAC,目标MAC是某挑选出的RS的RIP所在接口的MAC地址;源IP/PORT,以及目标IP/PORT均保持不变)
mac地址转换过程:
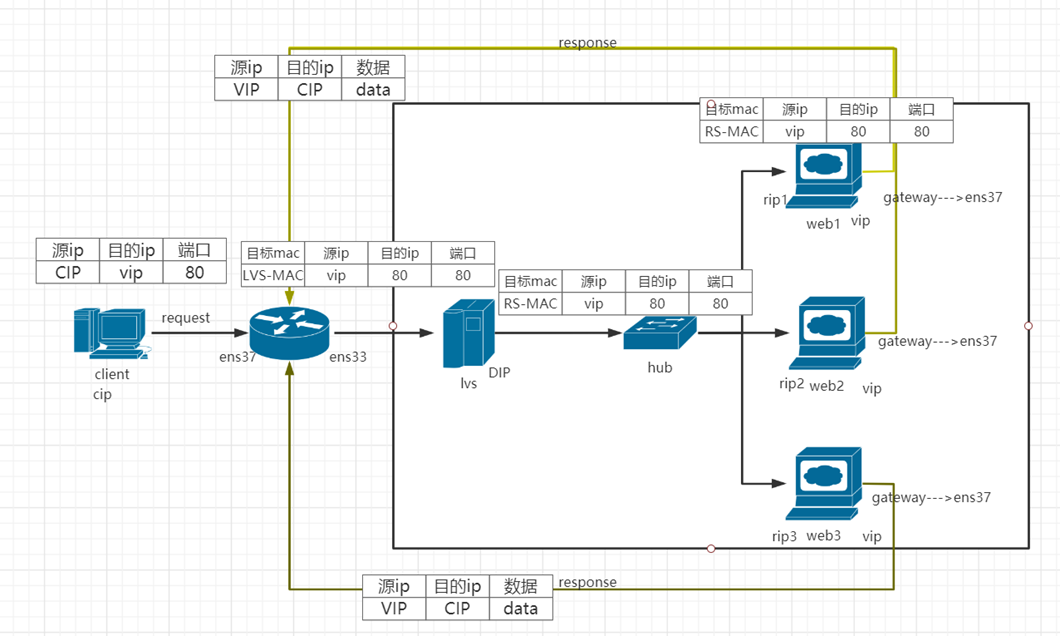
基于内核角度分析mac地址转换过程:
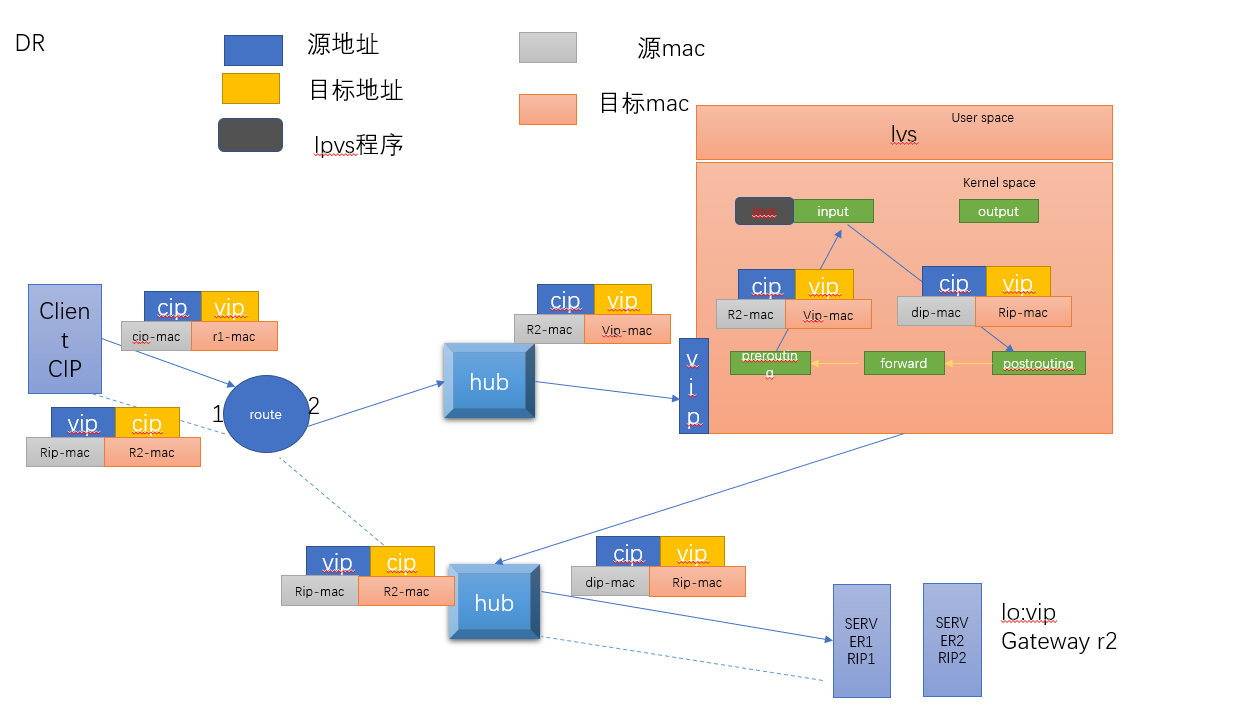
DR模式的特点:
DIRECTOR和各RS都配置有VIP
确保前端路由器将目标ip为VIP的请求报文发往DIRECTOR,3中处理方式
1. 在前端网关做静态绑定VIP和DIRECTOR的MAC地址
2. 在RS上使用arptables工具
范例:arptables -A IN -d $VIP -j DROP
arptables -A OUT -s $VIP -j mangle --mangle-ip-s $RIP
3. 在RS上修改内核参数以限制arp通告应答级别(推荐)
范例: /proc/sys/net/ipv4/conf/all/arp_ignore
/proc/sys/net/ipv4/conf/all/arp_announce
RS的RIP可以使用私网地址,也可以使用公网地址;RIP与DIP在同一ip网络;RIP的网关不能指向DIP,以确保响应报文不会经由director
RS和DIRECTOR要在同一个物理网络
请求报文要经由DIRECTOR,但响应报文不经由director,而由RS直接发往client
不支持端口映射(端口不能修改)
无需开启ip_forward
RS可以使用大多数OS系统
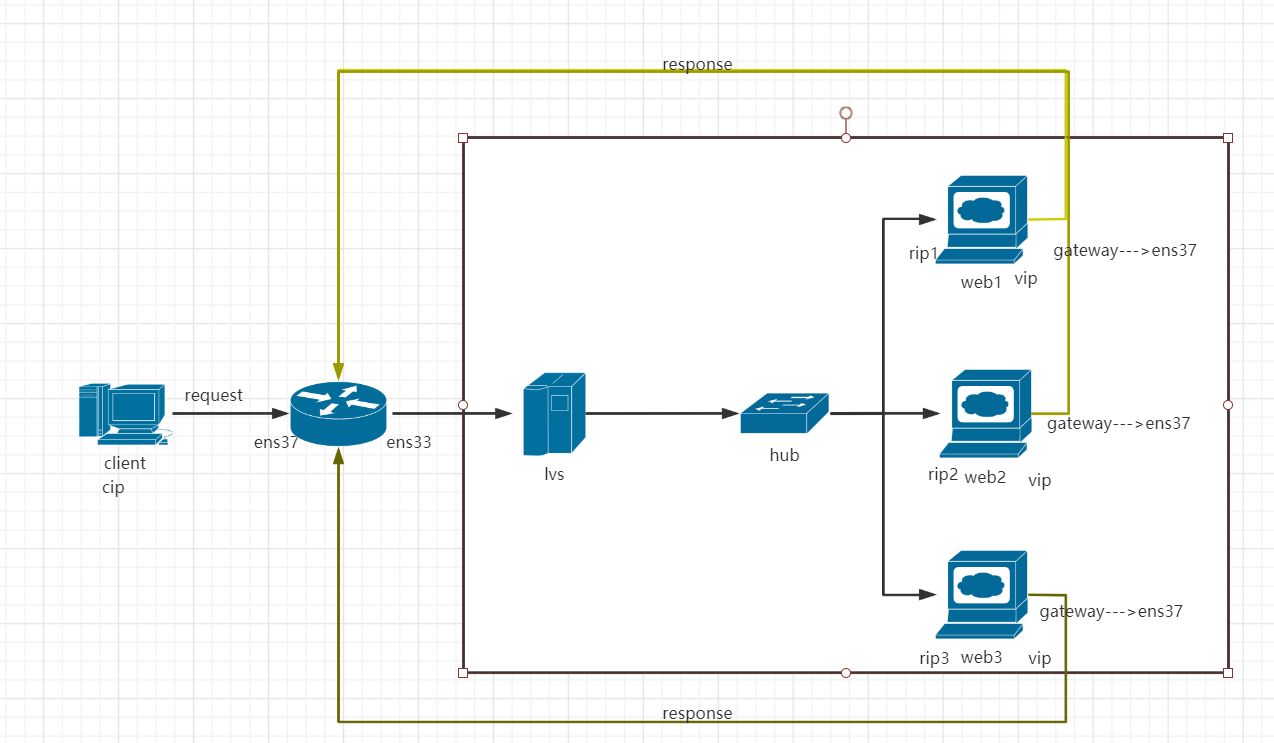
范例:实现DR模式(脚本方式实现),案例图如下 (单网段)
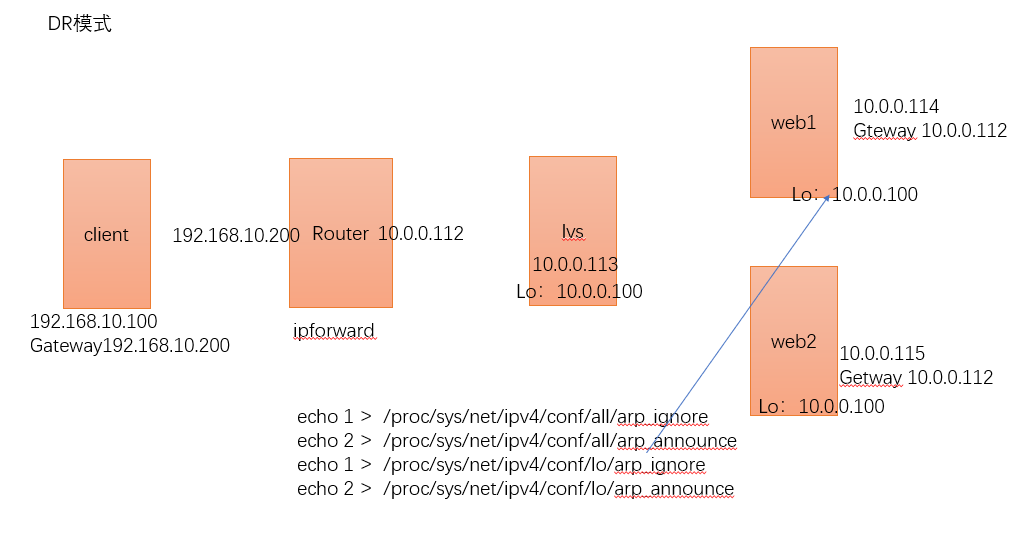
client端[测试端](即192.168.10.100)上运行如下脚本:
#!/bin/bash
#配合DR模式搭建LVS
#此脚本需要在client端运行,运行前需要修改网卡模式(仅主机模式)
IP_ADDRESS=192.168.10.100
PREFIX_NU=24 #掩码
dev=ens33 #网卡名
GATEWAY=192.168.10.200 #该地址是route的第一个接口的地址
cat > /etc/sysconfig/network-scripts/ifcfg-${dev} << EOF
TYPE="Ethernet"
IPADDR=${IP_ADDRESS}
PREFIX=${PREFIX_NU}
NAME="${dev}"
DEVICE="${dev}"
ONBOOT="yes"
GATEWAY=${GATEWAY}
EOF
nmcli con reload && nmcli con up ${dev}
hostnamectl set-hostname client && hostname client
route 端(192.168.10.200),脚本
#!/bin/bash
#此脚本是创建一个route,一个地址指向外网[192.168.10.*] ,内网[10.0.0.*]
dev0=ens33
ipaddress0=10.0.0.112
prefix=24
dev1=ens37
ipaddress1=192.168.10.200
cat > /etc/sysconfig/network-scripts/ifcfg-${dev0} << EOF
TYPE="Ethernet"
IPADDR=${ipaddress0}
PREFIX=${prefix}
NAME="${dev0}"
DEVICE="${dev0}"
ONBOOT="yes"
EOF
cat > /etc/sysconfig/network-scripts/ifcfg-${dev1} << EOF
TYPE="Ethernet"
IPADDR=${ipaddress1}
PREFIX=${prefix}
NAME="${dev1}"
DEVICE="${dev1}"
ONBOOT="yes"
EOF
nmcli con reload
nmcli con up ${dev0}
nmcli con up ${dev1}
cat >> /etc/sysctl.conf << EOF
net.ipv4.ip_forward = 1
EOF
sysctl -p
hostnamectl set-hostname reoute
lvs(10.0.0.113)
#!/bin/bash
dip=10.0.0.113
scheduling=rr
PORT=80
vip=10.0.0.100 #vip地址
prefix=24
dev=ens33
GATEWAY=10.0.0.112 #前面route主机上的ens37网卡的ip地址
web_ipaddr1=10.0.0.114
web_ipaddr2=10.0.0.115
rpm -ql ipvsadm &> /dev/null || yum install -y ipvsadm
cat > /etc/sysconfig/network-scripts/ifcfg-${dev} << EOF
TYPE="Ethernet"
IPADDR=${dip}
PREFIX=${prefix}
NAME="${dev}"
DEVICE="${dev}"
GATEWAY=${GATEWAY}
ONBOOT="yes"
EOF
nmcli con reload
nmcli con up ${dev}
ifconfig lo:1 ${vip}/32
ipvsadm -A -t ${vip}:${PORT} -s ${scheduling}
ipvsadm -a -t ${vip}:${PORT} -r ${web_ipaddr1}:${PORT} -g
ipvsadm -a -t ${vip}:${PORT} -r ${web_ipaddr2}:${PORT} -g
ipvsadm -Sn > /etc/sysconfig/ipvsadm
systemctl enable --now ipvsadm.service
hostnamectl set-hostname lvs_nat
web1端(10.0.0.114)
#!/bin/bash
#运行此脚本
vip=10.0.0.100
dev=ens33
web_ipaddr=10.0.0.114 #dip地址
PREFIX_NU=24
comment="114"
GATEWAY=10.0.0.112
rpm -ql httpd &> /dev/null || yum install -y -q httpd
echo ${comment} > /var/www/html/index.html
cat > /etc/sysconfig/network-scripts/ifcfg-${dev} << EOF
TYPE="Ethernet"
IPADDR=${web_ipaddr}
PREFIX=${PREFIX_NU}
NAME="${dev}"
DEVICE="${dev}"
GATEWAY=${GATEWAY}
ONBOOT="yes"
EOF
nmcli con reload
nmcli con up ${dev}
ifconfig lo:1 ${vip}
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
systemctl enable --now httpd
hostnamectl set-hostname web1
web2端(10.0.0.115)
#!/bin/bash
#运行此脚本
dev=ens33
vip=10.0.0.100
web_ipaddr=10.0.0.115 #dip地址
PREFIX_NU=24
comment="115"
GATEWAY=10.0.0.112
rpm -ql httpd &> /dev/null || yum install -y httpd
systemctl enable --now httpd
echo ${comment} > /var/www/html/index.html
cat > /etc/sysconfig/network-scripts/ifcfg-${dev} << EOF
TYPE="Ethernet"
IPADDR=${web_ipaddr}
PREFIX=${PREFIX_NU}
NAME="${dev}"
DEVICE="${dev}"
GATEWAY=${GATEWAY}
ONBOOT="yes"
EOF
nmcli con reload
nmcli con up ${dev}
ifconfig lo:1 ${vip}/32
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
hostnamectl set-hostname web2
systemctl enable --now httpd
4.4 LVS-TUN模式:
实现原理:不修改请求报文的ip首部(源ip为CIP,目标ip为VIP),而在原ip报文之外在封装一个ip首部(源ip是DIP,目标是RIP),将报文发往挑选出的目标RS;RS直接响应给客户端(源ip是VIP,目标ip是CIP)
因为DR和NAT模型,rip和dip都应在同一个网段中;而且每个rip都必须在同一个网段里,而TUN模型,基于隧道的方式与后端的rip进行交互,这使得每个rip或rip与dip可以不在同一个网段中。
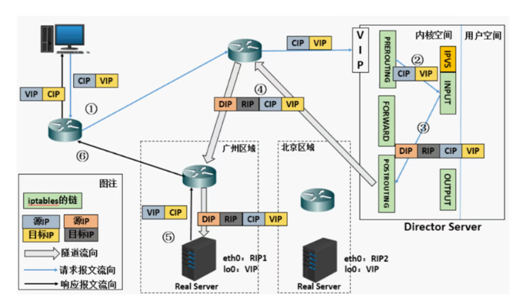
特点:
RIP和DIP可以处于不同物理网络中,RS的网关一般不指向DIP,且RIP可以和公网通信。也就是说集群节点可以跨互联网实现。DIP,VIP,RIP可以是公网地址
realserver 的tun接口上需要配置VIP地址,以便于接受director转发过来的数据包,以及作为响应的报文源IP
director转发给realserver时需要借助隧道,隧道外层的ip头部的源ip是DIP,目标IP是RIP,而realserver响应给客户端的IP头部是根据隧道内层的ip头分析得到的,源ip是VIP,目标IP是CIP
请求报文要经由director,但响应不经由director,响应由realserver自己完成
不支持端口映射
RS的os须支持隧道功能
应用场景:
一般来说,TUN模式常用来负载调度缓存服务器组,这些缓存服务器一般放置在不同的网络环境,可以就近折返给客户端。在请求对象不在cache服务器本地命中的情况下,cache服务器要向源服务器发送请求,将结果取回,最后将结果返回给用户。
4.5 LVS-FULLNAT模式: (此类型kernel默认不支持)
实现原理:通过同时修改请求报文的源ip地址和目标IP地址进行转发
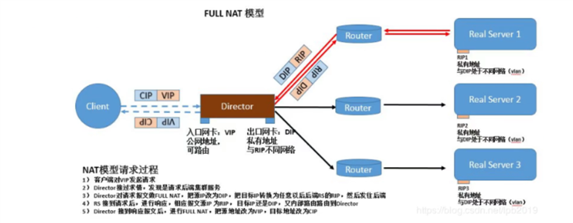
fullnat特点:
VIP是公网地址,RIP和DIP是私网地址,且通常不在统一ip网络;因此,RIP的网关一般不会指向DIP
RS收到的请求报文源地址是DIP,因此,只需响应给DIP;但director还要将其发往client
请求和响应报文都经由director
相对NAT模式,可以更好的实现LVS-REALSERVER间跨wlan通讯
支持端口映射
LVS-NAT与LVS-FULLNAT:
请求和响应报文都经由director
lvs-nat: rip的网关要指向DIP
lvs-fullnat:rip与dip未必在同一个网络中
LVS-DR与LVS-TUN:
请求报文要经由diretor,但响应报文由RS直接发往client
lvs-dr:通过封装新的MAC首部,通过MAC网络转发
lvs-tun:通过在源ip报文外封装新的ip头实现转发,支持远距离通信
5 LVS 调度算法:
ipvs shceduler[调度器] 根据器调度时是否考虑各RS当前的负载状态分为两种调度方法:静态调度和动态调度
静态方法: 仅根据算法本身进行调度
RR: 轮询,较常用
WRR: 加权轮询,较常用。
但是要注意权重的分配(如:1,2,3 如果是三台同样配置的机器,这样分配有些不合理)
SH: source hash 实现seccion sticky,源地址ip地址hash;将来自于同一个ip地址请求始终发往第一次挑中的RS,从而实现会话绑定。
缺陷,有可能client来自某个网络,这使得这个网络中的所有主机的请求调度至第一次调度的RS上。
DH: destination hash,目标地址hash,第一次轮询调度至RS,后续将发往同一个目标地址的请求始终转发至第一次挑中的RS,典型使用场景是正向代理缓存场景中的负载均衡,如web缓存
比如:某小区内的所有主机访问web时,为了减少网路中的带宽,如果该小区的某个主机下载的资源(活月的资源),一般作为调度器都会缓存一份,如果该小区的其他主机再次下载该资源时,就不需再次调度到RS取下载同样的资源。
动态方法:主要根据每RS当前的负载状态及调度算法进行调度(Overhaed=value),较小的RS将被调度
LC: least connections 最小连接调度。 如果RS服务器系统性能相近,采用最小连接调度算法可以比较好的实现均衡负载。
即把新的连接请求分配得到当前连接数最小的服务器。它通过服务器当前活跃的连接数来估计服务器情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度至某台服务器后,器连接数加1,当连接中断时或超时时,其连接数减1。
overhead=activecons*256+inactivecons
WLC(Weighted Least-Connection Scheduling):加权最小连接,LVS默认算法。 overhead的值表示其RS的性能,如果RS越小,表示其性能越好(权值越大)。相当于领导(责任大,负载就越大)
overhead=(activecons*256+inactivecons)/weight
缺陷:如果所有的RS刚上线,这时连接数和非连接数都为0,这使权重小的RS将会被优先调度。
SED (shortest expected delay scheduling) 最少期望延迟。 初始连接高权重优先,只检查活动连接,而不考虑非活动连接。
缺陷:在不考虑非活动连接情况下,权重越大,越优先被调度。但是会出现这种情况: 就是权重越大的RS会很忙,而权重较小的RS很闲,甚至就收不到请求。
Overhead=(activeconns+1)*256/weight
NQ (nerver queue) 第一轮均匀分配,后续sed。 相当于sed算法的进阶版
LBLC(locality-Based Least connection) 基于局部性的最小连接。相当于动态的DH算法,使用场景:根据负载实现正向代理,实现web,cache等。
相当于能检测RS的连接数,如果RS连接数比较多,那么lvs将会把该请求调度至连接数比较小的RS上。但是用户第一次请求,将会被轮询调度至RS上。
LBLCR( REPLCATION), 带复制功能的LBLC,解决LBLC负载不均衡问题,从负载重的复制至负载轻的RS,实现web,CACHED等。
内核版本4.15 版之后 新增调度算法:FO和OVF
FO(Weighted Fail Over)调度算法,在此FO算法中,遍历虚拟服务所关联的真实服务器链表,找到还未过载(未设置IP_VS_DEST_F_OVERLOAD标志)的且权重最高的真实服务器,进行调度,属于静态算法
OVF(Overflow-connection)调度算法,基于真实服务器的活动连接数量和权重值实现。将新连接调度到权重值最高的真实服务器,直到其活动连接数量超过权重值,之后调度到下一个权重值最高的真实服务器,在此OVF算法中,遍历虚拟服务相关联的真实服务器链表,找到权重值最高的可用真实服务器。,属于动态算法
一个可用的真实服务器需要同时满足以下条件:
未过载(未设置IP_VS_DEST_F_OVERLOAD标志)
真实服务器当前的活动连接数量小于其权重值
其权重值不为零
6. lvs相关软件:
程序包:ipvsadm
服务(脚本):ipvsadm
主程序:/usr/sbin/ipvsadm
规则保存工具:/usr/sbin/ipvsadm-save
规则重载工具:/usr/sbin/ipvsadm-restore
规则文件:/etc/sysconfig/ipvsadm-config
ipvs调度规则文件:/etc/sysconfig/ipvsadm
ipvsad命令:
ipvsadm 核心功能
集群服务管理:增,删,改
集群服务的RS管理:增,删,改
查看
管理集群服务:
选项说明:
service-address:
rip[:port] 如省略port,不做端口映射
lvs类型:
-g :gateway ,dr模型,默认
-i :ip ,tun模型
-m:masquerade,nat模型
-w weight 权重
-s scheduler 算法:rr,wrr ,sh,dh, lc,wlc,sed,nq,lblc,lblcr
-r RS-ADDRESS: RS服务器的ip
-f label_num: 防火墙标签
集群管理:
ipvsadm -A|E virtual-service [-s scheduler] [-p [timeout]] [-M netmask] [-b sched-flags]
删除:ipvsadm -D -t| u| f service-address
清空:ipvsadm -C
重载,相当于ipvsadm-restore : ipvsadm -R
保存: ipvsadm -S [-n] 保存,相当于ipvsadm-save
集群中的rRS管理:
ipvsadm -a|e virtual-service -r server-address [-g|i|m] [-w weight] [-x upper] [-y lower]
ipvsadm -a|e -t|u|f service-address -r server-address [-g|i|m] [-w weight]
ipvsadm -d -t|u|f service-address -r server-address
ipvsadm -L|l [options]
ipvsadm -Z [-t|u|f service-address]
添加一个集群服务:
ipvsadm -A -t 10.0.0.110:80 -s rr
删除:
ipvsadm -D -t|u|f service-address
管理集群上的RS,增,删,改
增,改 ipvsadm -a|e -t|u|f service-address -r service-address [-g|i|m] [-w weight]
删 ipvsadm -a|e -t|u|f service-address -r service-address
范例:ipvsadm -a -t 10.0.0.110:80 -r 10.0.0.100:80 -m -w 3
ipvsadm -C 清空定义的所有内容
ipvsadm -Z [-t| u| f service-address] 清空记数器
ipvsadm -L|l [options] 查看
--numeric ,-n 以数字形式输出地址和端口号
--exact:扩展信息,精确值
--stats 统计信息
--rate 输出速率信息
ipvs规则 :/proc/net/ip_vs
ipvs连接:/proc/net/ip_vs_conn
保存ipvsadm定义的规则于文件中。
ipvsadm-save >/path/to/ipvsadm_file
ipvsadm -S >/path/to/ipvsadm_file
ipvsadm-restore </path/from/ipvsadm_file
systemctl stop|start ipvsadm.service #开启|关闭ipvsadm服务,会自动保存|加载 规则至/etc/sysconfig/ipvsadm
6.2 防火墙标记(FVM :FIREWALL MARK)
借助于防火墙标签来分类报文,而后基于标记定义集群服务;可将多个不同的应用使用同一个集群服务进行调度。
比如:web程序一般都会打开两个端口80 443[https],而当我们分别定义,访问时,有可能都会被调度至同一个RS上。
实现方法:
iptables -t mangle -A PREROUTING -d $vip -p $proto -m multiport --dports $port1,$port2,… -j MARK --set-mark NUMBER
范例:
[root@lvs ~]#iptables -t mangle -A PREROUTING -d 172.16.0.100 -p tcp -m
multiport --dports 80,443 -j MARK --set-mark 10
[root@lvs ~]#ipvsadm -C
[root@lvs ~]#ipvsadm -A -f 10 -s rr
[root@lvs ~]#ipvsadm -a -f 10 -r 10.0.0.7 -g
[root@lvs ~]#ipvsadm -a -f 10 -r 10.0.0.17 -g
[root@lvs ~]#ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
FWM 10 rr
-> 10.0.0.7:0 Route 1 0 0
-> 10.0.0.17:0 Route 1 0 0
[root@lvs ~]#cat /proc/net/ip_vs
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
FWM 0000000A rr
-> 0A000011:0000 Route 1 0 9
-> 0A000007:0000 Route 1 0 9
6.3 持久连接
session 绑定:对共享同一组RS的多个集群服务,需要统一进行绑定,LVS sh算法无法实现持久连接。
实现原理:基于(lvs persistence) 模板实现:实现无论使用任何算法任何调度,在一段时间内(默认为360s),能够实现将来自同一个地址的请求始终发往同一个RS。
即通过-p TIMEOUT 选项定义
ipvsadm -A|E -t|u|f service-address [-s scheduler] [-p [timeout]]
范例:
[root@lvs ~]#ipvsadm -E -f 10 -p
[root@lvs ~]#ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
FWM 10 wlc persistent 360
-> 10.0.0.7:0 Route 1 0 15
-> 10.0.0.17:0 Route 1 0 7
[root@lvs ~]#ipvsadm -E -f 10 -p 3600
[root@lvs ~]#ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
FWM 10 wlc persistent 3600
-> 10.0.0.7:0 Route 1 0 79
-> 10.0.0.17:0 Route 1 0 7
至此lvs已介绍完,但lvs高可用性很差。
lvs不可用时,将会导致整个系统不可用
解决方法:keepalived配合使用
RS不可用时,lvs依然会继续调度(即不能检查RS的健康性)
解决方法:keepalive配合使用
对RS健康性检测方式:
网络层检测:icmp
传输层检测,端口探测
应用层检测,请求某关键资源
标签:统计 设定 real conf 通用 linux 均衡负载 orm 代码
原文地址:https://www.cnblogs.com/ldlx/p/14541508.html