标签:lazy 替代 例子 net current 64bit fonts get details
上篇文章记录到volatile在硬件层面怎么保证线程间可见性的,是通过lock锁缓存行缓存一致性协议来实现的。但是这样会有一个伪共享的问题。
首先缓存行在64bit机中一般为64字节,具体缓存行大小可以通过下面的命令查看:
cat /proc/cpuinfo

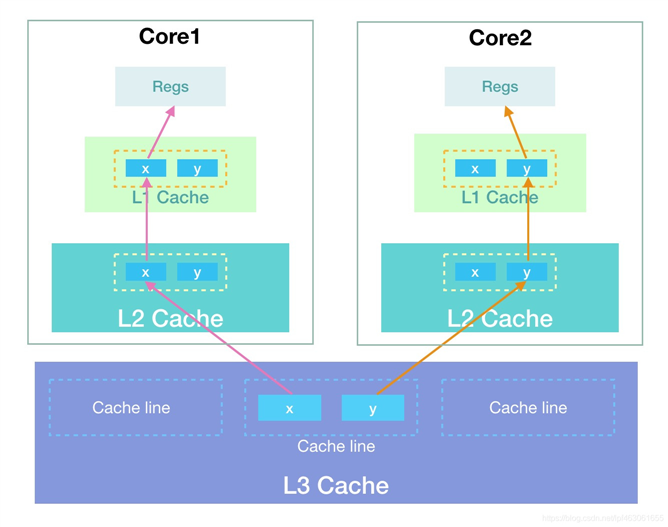
假设有一个对象有两个long类型的数据x,y,在java中long类型数据长度为8个字节,所以读取一个对象数据后x,y会在一个缓存行中。有两个CPU读取这个对象如下图的Core1,Core2,其中Core1只对x进行修改,Core2只对y进行修改。
根据缓存一致性协议知道,当Core1中数据修改后会导致Core2中的缓存行失效,Core2中的数据就要从主存中重新获取,同理:当Core2中数据修改后会导致Core1中的缓存行失效,Core1中的数据就要从主存中重新获取。两核之间存在缓存行的竞争关系。
这会导致性能损耗。下面举个例子看下这种情况。

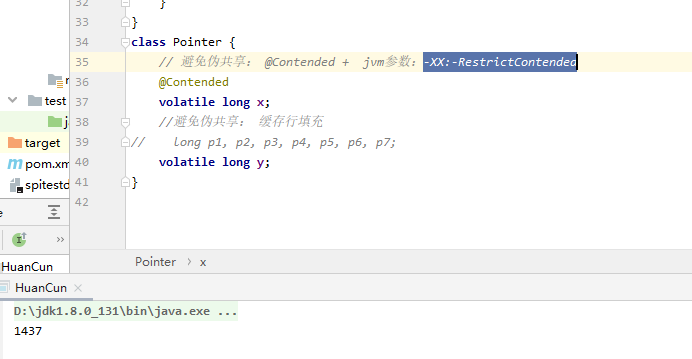
public class HuanCun { public static void main(String[] args) throws InterruptedException { testPointer(new Pointer()); } private static void testPointer(Pointer pointer) throws InterruptedException { long start = System.currentTimeMillis(); Thread t1 = new Thread(() -> { for (int i = 0; i < 100000000; i++) { pointer.x++; } }); Thread t2 = new Thread(() -> { for (int i = 0; i < 100000000; i++) { pointer.y++; } }); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println(System.currentTimeMillis() - start); } } class Pointer { // 避免伪共享: @Contended + jvm参数:-XX:-RestrictContended //@Contended volatile long x; //避免伪共享: 缓存行填充 //long p1, p2, p3, p4, p5, p6, p7; volatile long y; }
上面的代码执行结果:
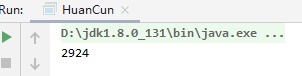
将近三秒执行。
为了避免让x,y在同一个缓存行,我们可以把x,y分开在不同缓存行,可以通过在x变量后面添加七个long类型变量,这样x,y就位于不同的缓存行上了。
如下: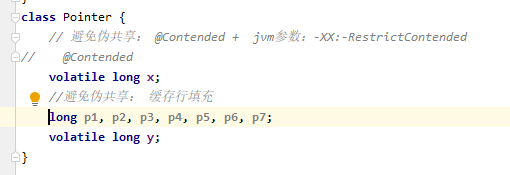
这样运行结果看下:
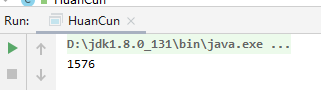
速度提升还是很明显的。
但是上面消除伪共享的方法不太合适,还要再单独定义 其它变量。在jdk8中有新的方式可以消除伪共享的情况。
就是:
避免伪共享: @Contended + jvm参数:-XX:-RestrictContended
这种方式的执行时间也提升了很多。
我上面以及上一篇都是在讲volatile的可见性是如何保证的,volatile还有一种作用就是有序性。
我们可以从double check中看到场景。
JMM中关于synchronized有如下规定,线程加锁时,必须清空工作内存中共享变量的值,从而使用共享变量时需要从主内存重新读取;线程在解锁时,需要把工作内存中最新的共享变量的值写入到主存,以此来保证共享变量的可见性。(ps这里是个泛指,不是说只有在退出synchronized时才同步变量到主存)。
那么加了 synchronized, myInstance的可见性已经保证了,为什么还要加上volatile呢?
private volatile static SingletonFactory myInstance; public static SingletonFactory getMyInstance() { if (myInstance == null) {
synchronized (SingletonFactory.class) { if (myInstance == null) { myInstance = new SingletonFactory(); } } } return myInstance; }
这个要说下对象的创建过程说起了,对象创建也就是说new这个操作JVM到底做了什么事,这个问题之前在CSDN上记录过可以去看下:https://blog.csdn.net/A7_A8_A9/article/details/105730007
我把new操作的汇编贴一下:
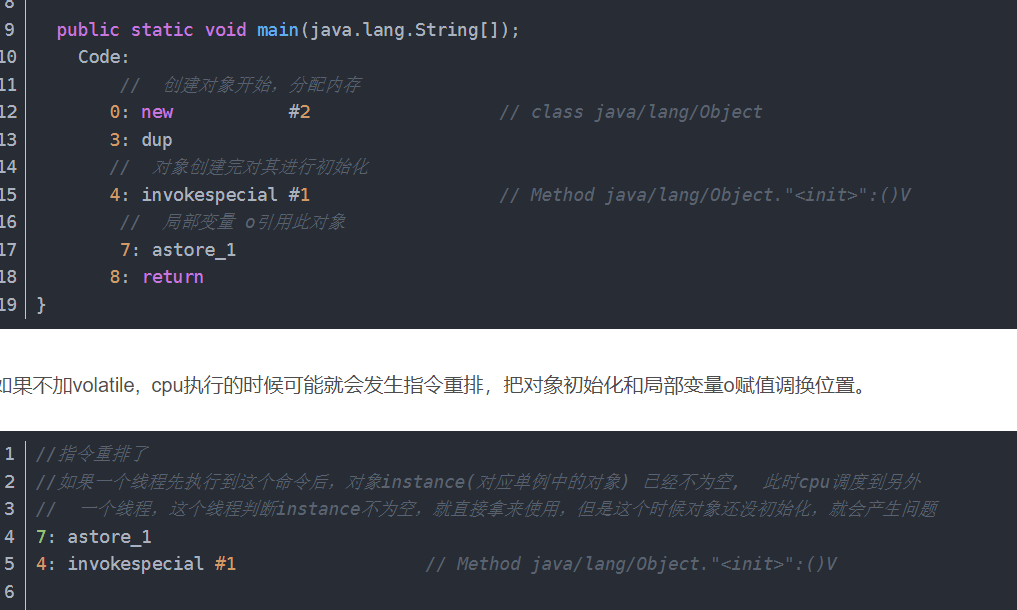
JIT可能会对指令重排序,处理器也有可能是乱序执行,因为这样可以提升性能。对于如何提升性能的我们可以从下面的伪代码中窥探一二:
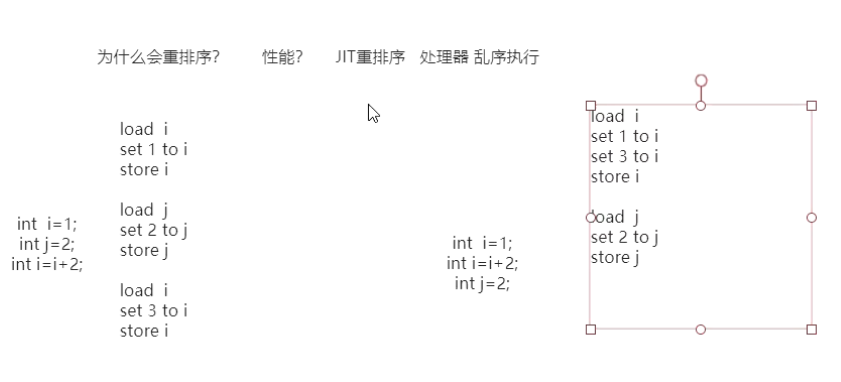
右边调整了顺序之后可以减少i的加载和store,虽然例子只是一个int变量,如果是一个很大的对象/数据,这个节约的时间就是值得的。这种指令重排是JIT编译之后的结果。处理器的乱序执行是当前指令在Load数据等待中,cpu可能先执行下面的指令了。
为什么JIT会进行重排序呢?我们知道我们java文件编译成class文件,然后JVM编译成指令序列再到汇编指令,JVM有两个编译方式,一种是读取一行解释一行,这种效率自然是很慢的,还有一种是JIT即时编译它会检测一些频繁使用的代码编译成热点代码,这样不用每次使用都要编译了。

指令重排的重现例子:
private static int x = 0, y = 0; private static int a = 0, b = 0; public static void main(String[] args) throws InterruptedException{ int i=0; while (true) { i++; x = 0; y = 0; a = 0; b = 0; /** * x,y: * 每次循环,x,y,a,b都会赋初值0,两个线程各执行一次,执行完,x,y可能的值有: * 0,1 1,0 1,1 这是我们按正常逻辑思考可能出现的结果,但是有一种情况是只会在重排序的情况出现 * 就是 0,0 也就是这种情况下两个线程变成了这样的逻辑。 * thread1: * x=b; * a=1; * thread2: * y=a; * b=1; * 我们执行看下是否会出现这样的情况呢? */ Thread thread1 = new Thread(new Runnable() { @Override public void run() { shortWait(20000); a = 1; x = b; } }); Thread thread2 = new Thread(new Runnable() { @Override public void run() { b = 1; y = a; } }); thread1.start(); thread2.start(); thread1.join(); thread2.join(); System.out.println("第" + i + "次(" + x + "," + y + ")"); if (x==0&&y==0){ break; } } } public static void shortWait(long interval){ long start = System.nanoTime(); long end; do{ end = System.nanoTime(); }while(start + interval >= end); }
结果:
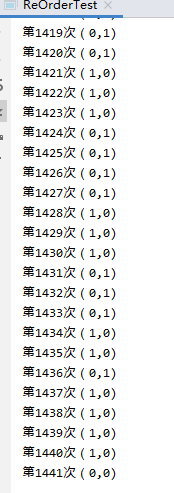
指令重排出现了。
为了避免指令重排,可以给变量加上volatile关键字,禁止重排序,保证有序性也保证了可见性。我们从上篇知道,可见性它是靠Lock,触发缓存一致性协议保证的。禁止指令重排也是靠这个Lock保证的,
它起到了内存屏障的作用,它虽然不是内存屏障指令。注意在linux_x86的系统中内存屏障mfence用lock来替代了。
我们也可以手动添加内存屏障来禁止重排序,使用Unsafe类。
public class UnsafeUtil { public static Unsafe getUnsafe(){ try { Field field= Unsafe.class.getDeclaredField("theUnsafe"); field.setAccessible(true); return (Unsafe)field.get(null); } catch (Exception e) { e.printStackTrace(); } return null; } }
使用的地方。
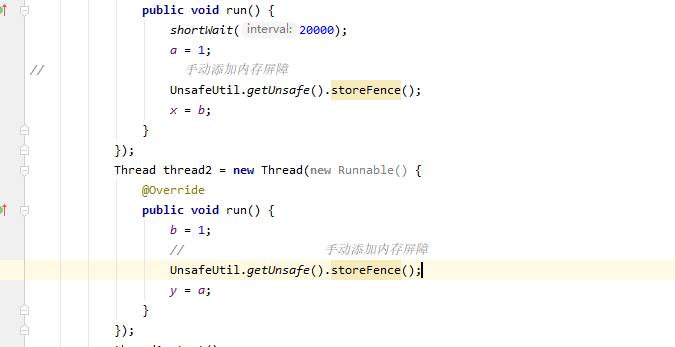
storefence是本地方法,我们可以去看下jdk的源码。

可以看到 jvm屏蔽掉了不同的cpu。
我以linux_x86为例来看。
查看orderAccess
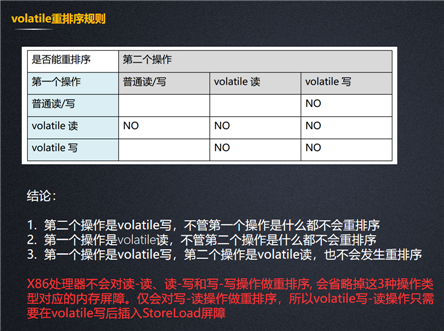
我们看到定义了四种"内存屏障操作"但是对于x86处理器来说,它只关心sotreload这一种内存屏障,其它的它不管。这里我们只要看fence就可以了,


if里判断是否是多核处理架构,根据上面的注释也可以知道使用 lock; addl来代替mfence。这是x86里面的内存屏障实现方式。
Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。它后面可以跟ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG等指令
为什么只关注StoreLoad指令呢,因为在JSR-133规范中定义了x86内核是如何对内存屏障和原子性进行支持的。
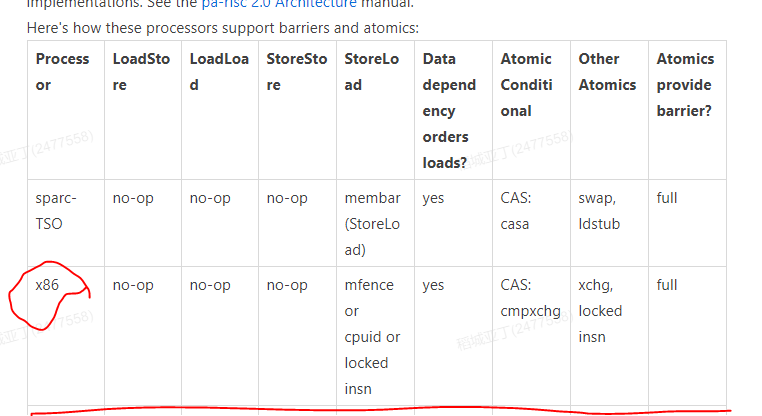
x86就是靠lock指令实现的。具体这个的解释如下 ,参考了:https://www.zhihu.com/question/65372648


JMM模型就是在先行发生模型上面的优化。线程的可见性,有序性,原子性都可以从先行发生模型来考虑。
我们从一个例子来看下:
我们约定线程A执行write(),线程B执行read(),且线程A优先于线程B执行(时间先后顺序),那么线程B获得结果是什么?这段代码是线程安全的吗
private int i = 0; public void write(int j ){ i = j; } public int read(){ return i; }
按上面的执行是线程不安全的,虽然线程A先于线程B执行,但是线程B对于线程A的执行结果确实不可见的,这也是先行发生模型强调的点,这个先行不是代码执行时间上的先后顺序而是执行结果是顺序的。
线程内存模型有:

标签:lazy 替代 例子 net current 64bit fonts get details
原文地址:https://www.cnblogs.com/krock/p/14596247.html
