标签:strong 线性 本地 添加 开发 json 能力 缓冲 display
本文介绍的是斯坦福自然语言处理工具的升级版:Stanza,在v1.0.0之前,这个工具被称为StanfordNLP。
2021年了,今天想使用斯坦福自然语言处理工具发现人家升级了,不用安装JDK了,只需要
Stanza supports Python 3.6 or later. We recommend that you install Stanza via pip, the Python package manager. To install, simply run:
pip install stanza
This should also help resolve all of the dependencies of Stanza, for instance PyTorch 1.3.0 or above.
官方介绍页面:https://stanfordnlp.github.io/stanza/
使用手册发表在ACL2020上:https://arxiv.org/abs/2003.07082
Github仓库地址:https://github.com/stanfordnlp/stanza/
Abstract
我们将介绍stanza,一个支持66种人类语言的开源Python自然语言处理工具包。与现有的广泛使用的工具箱相比,stanza提供了一个与语言无关的完全神经网络的文本分析管道,包括标记化、多词标记扩展、引理化、部分语音和形态特征标记、依赖分析和命名实体识别。我们在112个数据集(包括通用依赖树库和其他多语言语料库)上训练了stanza,结果表明,相同的神经结构在所有被测语言上都具有良好的泛化能力和竞争力。此外,stanza还包括一个到广泛使用的Java Stanford CoreNLP软件的本地Python接口,该接口进一步扩展了它的功能,以涵盖其他任务,如协同引用解析和关系提取。
1 Introduction
开源自然语言处理(NLP)工具包的日益普及使得用户更容易构建具有复杂语言处理的工具。尽管CoreNLP(Manning et al.,2014)、FLAIR(Akbik et al.,2019)、spaCy(https://spacy.io/)和UDPipe(Straka,2018)等现有NLP工具包已得到广泛使用,但它们也存在一些局限性。首先,现有的工具箱通常只支持少数几种主要语言。这大大限制了社区处理多语言文本的能力。其次,由于注重效率(如spaCy)或使用功能不太强大的模型(如CoreNLP),广泛使用的工具有时在精度方面没有得到充分优化,这可能会误导下游应用程序和从中获得的见解。第三,一些工具假设输入文本已经用其他工具标记或注释,缺乏在统一框架内处理原始文本的能力。这限制了它们对不同来源文本的广泛适用性。
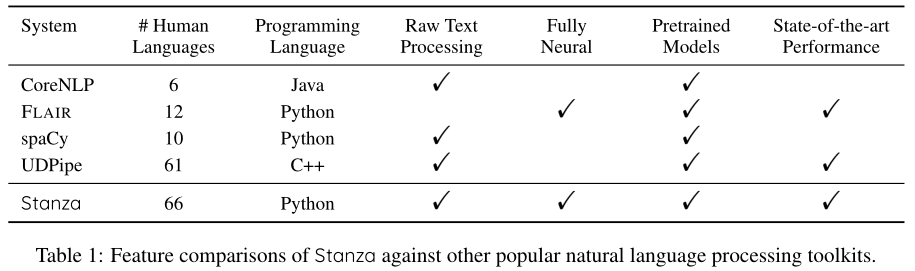
我们将介绍Stanza(在v1.0.0之前,这个工具箱被称为StanfordNLP),一个支持多种人类语言的Python自然语言处理工具包。如表1所示,与现有广泛使用的NLP工具包相比,Stanza具有以下优点:
From raw text to annotations
Stanza的特点是一个以原始文本为输入的完全神经管道,并产生注释,包括标记化、多词标记扩展、引理化、词性和形态特征标记、依赖分析和命名实体识别。
Multilinguality
Stanza的体系结构设计是语言不可知和数据驱动的,这使我们能够通过在Universal Dependencies(UD)树库和其他多语言语料库上训练管道pipeline来发布支持66种语言的模型。
State-of-the-art performance
我们在总共112个数据集上对stanza进行了评估,发现它的神经管道能够很好地适应不同类型的文本,在管道的每一步都达到了最先进的或有竞争力的性能。
2 System Design and Architecture
在顶层,Stanza由两个单独的组件组成:(1)完全神经的多语言NLP管道;a fully neural multilingual NLP pipeline;(2)Java-Stanford CoreNLP软件的Python客户端接口。在本节中,我们将介绍他们的设计
2.1 Neural Multilingual NLP Pipeline
Stanza的神经管道由各种模型组成,从标记原始文本到对整个句子进行句法分析(见图1)。所有组件的设计都考虑到处理多种人类语言,高级设计选择捕捉多种语言中的常见现象,数据驱动模型从数据中学习这些语言之间的差异。此外,stanza组件的实现是高度模块化的,并且尽可能地重用基本的模型体系结构以实现紧凑性。我们在此强调重要的设计选择,并请读者参考Qi et al(2018)的建模细节。
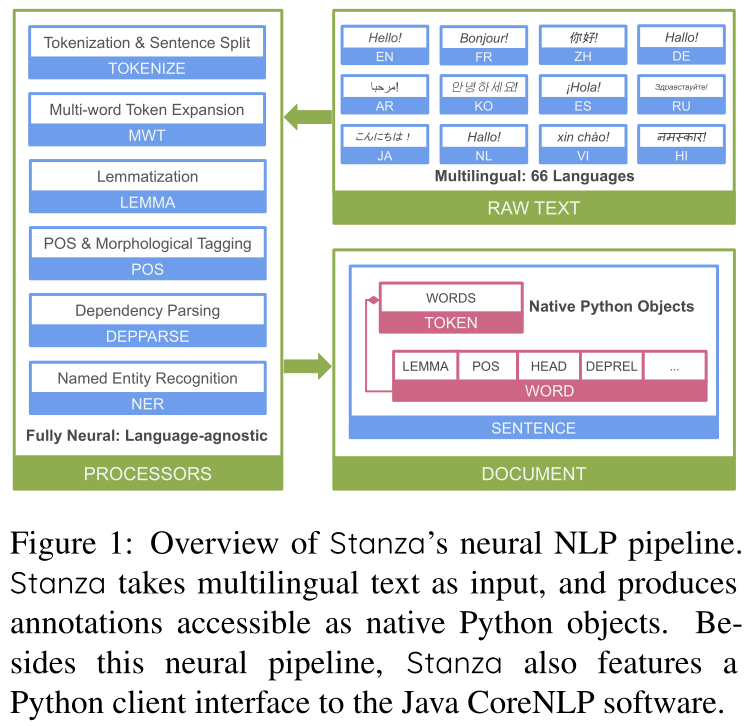
图1:Stanza的神经NLP管道概述。Stanza将多语言文本作为输入,并生成可作为本机Python对象访问的注释。除了这个神经管道,Stanza还提供了一个到Java Corenlp software的Python客户端接口。
Tokenization and Sentence Splitting.
当呈现原始文本raw text时,Stanza将其标记并将标记分组为句子,作为处理的第一步。与大多数现有的工具箱不同,Stanza将原始文本的标记化和句子分割结合到一个模块中。这被建模为字符序列上的标记问题,其中模型预测给定字符是标记的结尾、句子的结尾还是多词标记的结尾multi-word token(MWT,见图2)【遵循通用依赖关系(Nivre et al.,2020),我们区分了标记(输入文本中字符的连续跨度)和语法词。除了MWT的情况外,这些符号是可互换的,MWT的情况是一个标记可以对应多个单词。】。我们选择与标记化一起预测MWT,因为在某些语言中,此任务是上下文敏感的。
Multi-word Token Expansion.
一旦标记器识别出MWT,它们就被扩展到底层的语法词中,作为下游处理的基础。这是通过频率词典和神经序列对序列(seq2seq)模型的集成来实现的,以确保训练集中经常观察到的扩展总是稳健地扩展,同时保持对不可见词进行统计建模的灵活性。
POS and Morphological Feature Tagging形态特征标注.
对于一个句子中的每个单词,Stanza给它指定一个词性(POS),并分析它的普遍形态特征(UFeats,例如单数/复数、第一/第二/第三人称等)。为了预测POS和UFeats,我们采用了双向长短时记忆网络(bilstm)作为基本结构。为了使通用POS,universal POS (UPOS)、树库特定POS,treebank-specific POS(XPOS)和UFeats之间的一致性,我们采用Dozat and Manning(2017)的Biafine评分机制,将XPOS和UFeats预测条件化为UPOS的预测条件。
Lemmatization.词形还原
Stanza还将句子中的每个单词进行引理化,以恢复其规范形式(例如,did→do)。与多字标记扩展器类似,Stanza的lemmatizer实现为基于字典的lemmatizer和神经seq2seq lemmatizer的集成。在seq2seq模型的编码器输出上构建了一个额外的分类器,用于预测$shortcuts$ ,如小写和标识副本 lowercasing and identity copy,以便对长输入序列(如URLs)具有鲁棒性。
Dependency Parsing.
Stanza解析每个句子的句法结构,其中句子中的每个词都被指定一个句法头,该句法头要么是句子中的另一个词,要么是在词根的情况下,一个人工词根符号。我们实现了一个基于Bi LSTM的深度双仿射神经依赖解析器(Dozat and Manning,2017)。我们进一步用两个语言特征来扩充这个模型:一个预测给定语言中两个单词的线性化顺序,另一个预测它们之间的典型线性距离。我们之前已经证明,这些功能显著提高了解析精度(Qi et al,2018)。
Named Entity Recognition.
对于每个输入句子,Stanza还识别其中的命名实体(例如,人名、组织等)。对于NER,我们采用了来自Akbik et al(2018)的基于上下文的字符串表示的序列标记器。我们首先训练一个前向和后向字符级LSTM语言模型,在标记时将两个语言模型中每个单词位置末尾的表示与单词嵌入连接起来,并将结果输入一个标准的带有条件随机场(CRF)解码器的一层双LSTM序列标记器。
2.2 CoreNLP Client
斯坦福大学的Java CoreNLP软件提供了一整套专门针对英语的NLP工具。然而,由于缺乏官方支持,Python(许多NLP从业者选择的编程语言)很难访问这些工具。为了方便使用Python中的CoreNLP,我们利用了CoreNLP中现有的服务器接口,并实现了一个健壮的客户机作为其Python接口。
当CoreNLP客户机被实例化时,Stanza将自动启动CoreNLP服务器作为本地进程。然后,客户机通过其restfulapi与服务器通信,然后在协议缓冲区中传输注释,并转换回本机Python对象。用户还可以指定JSON或XML作为注释格式。为了确保健壮性,在使用客户机时,Stanza会定期检查服务器的运行状况,并在必要时重新启动服务器。
3 System Usage
Stanza的用户界面设计为允许快速开箱即用地处理多语言文本。为了实现这一点,Stanza支持通过Python代码自动下载模型,并使用所选处理器进行流水线定制。注释结果可以作为本机Python对象访问,以允许灵活的后处理。
3.1 Neural Pipeline Interface
Stanza的神经NLP管道可以用管道$Pipeline$类初始化,以语言名作为参数。默认情况下,将在输入文本上加载和运行所有处理器;但是,用户也可以指定要加载和运行的处理器,并将处理器名称列表作为参数。用户还可以在初始化时指定其他处理器级属性,例如处理器使用的批大小。
下面的代码片段显示了Stanza在下载中文模型、使用自定义处理器注释句子以及打印所有注释时的最小使用:

所有处理器运行后,将返回一个文档实例,该实例存储所有注释结果。在文档中,注释以自顶向下的方式进一步存储在句子、标记和单词中(图1)。以下代码段演示如何访问文档中每个单词以及文档中所有命名实体的文本和POS标记:

Stanza被设计成在不同的硬件设备上运行。默认情况下,只要CUDA设备在管道中可见,就会使用它们,否则就会使用cpu。但是,用户可以通过在初始化时设置use\ gpu=False来强制所有计算在cpu上运行。
3.2 CoreNLP Client Interface
CoreNLP客户端接口的设计方式是,与后端CoreNLP服务器的实际通信对用户透明。要使用CoreNLP客户机注释输入文本,需要初始化$CoreNLPClient$实例,并提供CoreNLP注释器的可选列表。注释完成后,结果将作为本机Python对象进行访问。
此代码片段演示如何建立CoreNLP客户端并获取英语句子的NER和coreference注释:

通过客户端界面,用户可以用CoreNLP支持的6种语言对文本进行注释
3.3基于Web的交互式演示 Interactive Web-based Demo
为了帮助可视化Stanza生成的文档及其注释,我们构建了一个交互式web演示程序,以交互方式运行管道。对于Stanza用这些语言提供的所有语言和注释,我们根据在最大的treebank/NER数据集上训练的模型生成预测,并使用Brat rapid annotation tool将结果可视化【https://brat.nlplab.org/】。此演示在客户机/服务器体系结构中运行,并在服务器端执行注释。我们在网站上公开了这个演示的一个实例http://stanza.run/。它也可以在本地运行并安装适当的Python库。
在德语句子上运行Stanza的示例如图3所示。
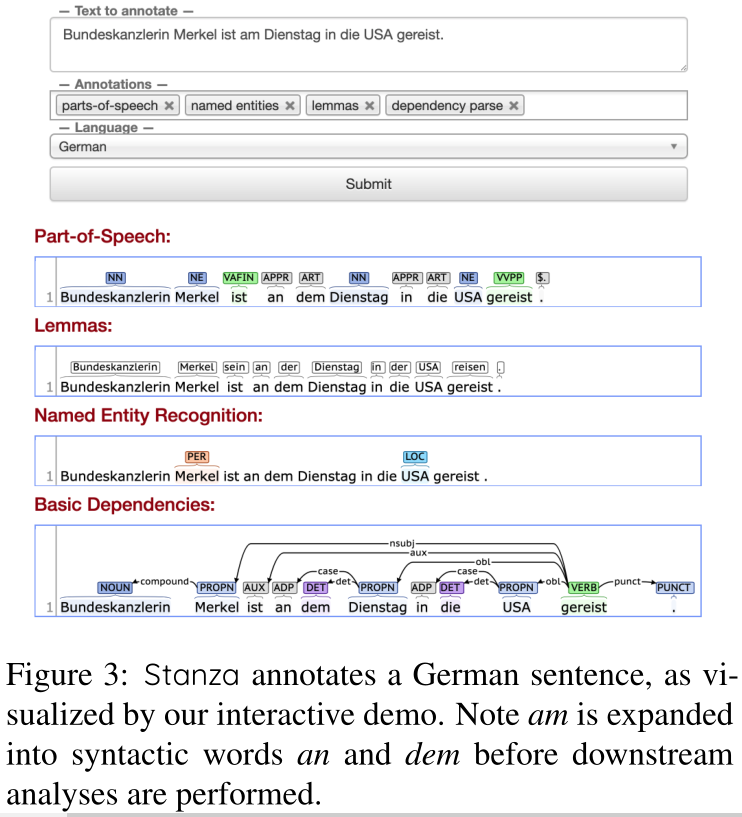
图3:stanza注释了一个德语句子,如我们的交互式演示所示。注:在进行下游分析之前,am被扩展为语法词an和dem。
3.4 Training Pipeline Models
对于所有的神经处理器,stanza为用户提供了命令行接口来训练他们自己的定制模型。为此,用户需要准备兼容格式的培训和开发数据(例如,universal dependencies管道的CoNLL-U格式和NER模型的BIO格式列文件)。以下命令使用用户指定的训练和开发数据训练神经依赖关系解析器:

4 Performance Evaluation
为了建立基准测试结果并与其他流行的工具包进行比较,我们在总共112个数据集上对Stanza进行了培训和评估。所有预先训练的模型都可以公开下载。
Datasets.
我们使用Universal Dependencies v2.5 treebanks(Zeman et al.,2019)对Stanza的标记器/句子拆分器、MWT扩展器、POS/UFeats标记器、lemmatizer和依赖解析器进行培训和评估。对于培训,我们使用此版本中100个具有非版权培训数据的树库,对于不包含开发数据的树库,我们随机将20%的培训数据分割为开发数据。
这些树状图Treebank代表66种语言,主要是欧洲语言,但跨越多种语系,包括印欧语系、亚非语系、乌拉尔语系、突厥语系、汉藏语系等。对于NER,我们使用12个公开数据集对Stanza进行了培训和评估,涵盖8种主要语言,如表3所示(Nothman等人,2013;Tjong Kim Sang)De Meulder,2003年;Tjong Kim-Sang,2002年;Benikova等人,2014年;Mohit等人,2012年;Taulé等人,2008年;Weischedel等人,2013年)。对于WikiNER语料库,由于没有规范划分,我们将它们随机划分为70%的训练、15%的开发和15%的测试划分。对于其他所有的语料库,我们都使用了它们的规范分裂。
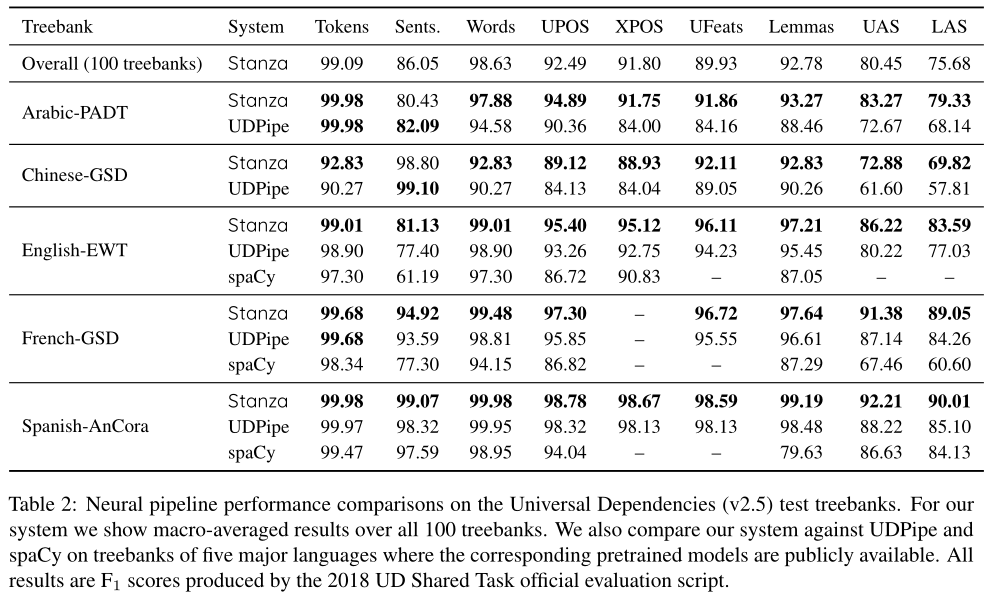
表2:通用依赖(v2.5)测试树库的神经管道性能比较。对于我们的系统,我们显示了所有100个树组的宏平均结果。我们还将我们的系统与五种主要语言的树库上的UDPipe和spaCy进行了比较,其中相应的预训练模型是公开的。所有结果均为2018环球开发商共享任务官方评估脚本产生的分数。
Training.
在通用依赖树库Universal Dependencies treebanks上,我们调整了几个大型树库上的所有超参数,并将它们应用于所有其他树库。当word2vec不可用时,我们使用作为2018 UD共享任务一部分发布的word2vec嵌入(Zeman等人,2018),或fastText嵌入(Bojanowski等人,2017)。对于NER组件中的字符级语言模型,我们在常见爬网和Wikipedia转储以及WMT19共享任务发布的新闻语料库(Barrault等人,2019)的混合上对它们进行了预训练,但英语和汉语除外,我们在Google 10亿字(Chelba等人。,2013)和中国千兆字语料库【https://catalog.ldc.upenn.edu/ LDC2011T13】。我们再次将相同的超参数应用于所有语言的模型。
Universal Dependencies Results.
对于UD树库Treebank的性能,我们将Stanza(v1.0)与UDPipe(v1.2)和spaCy(v2.2)在5种主要语言的树库上进行了比较,只要有一个预训练模型可用。如表2所示,Stanza在所报告的大多数分数上取得了最好的成绩。值得注意的是,我们发现Stanza的语言不可知体系结构能够适应不同语言和流派的数据集。Stanza的高宏平均分数也表明了这一点,它覆盖了66种语言的100个树库。
NER Results.
对于NER组件的性能,我们比较了Stanza(v1.0)与FLAIR(v0.4.5)和SpaCy(v2.2)。对于spaCy,只要能找到一个在同一数据集上训练过的模型,我们就报告其公开可用的预训练模型的结果,否则,我们就用默认的超参数在数据集上重新训练其模型,遵循公开可用的教程【https://spacy.io/usage/training\ner注意,在本公开教程之后,我们在训练spaCy-NER模型时没有使用预训练词嵌入,尽管使用预训练词嵌入可能会改善NER结果。】。对于FLAIR,因为他们的可下载模型是在不同于规范模型的数据集版本上预先训练的,所以我们用他们最好的超参数在我们自己的数据集分裂上重新训练了所有模型。所有试验结果见表3。
我们发现,在所有的数据集上,与FLAIR相比,Stanza的F1得分都更高或接近。与spaCy相比,Stanza的NER性能要好得多。值得注意的是,与FLAIR相比,Stanza的高性能是通过更小的模型实现的(小到75%),因为我们有意压缩模型以提高内存效率和易于分发。
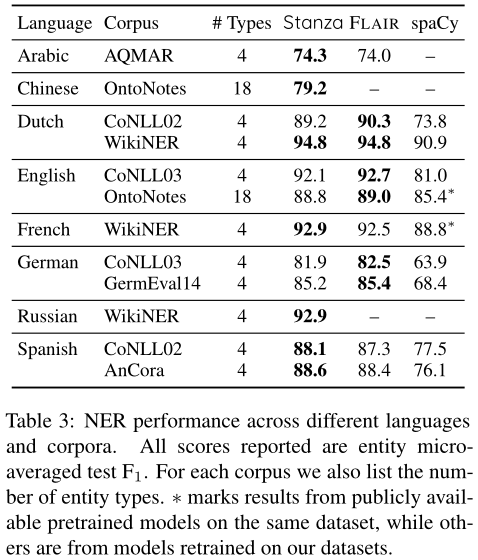
表3:NER在不同语言和语料库中的表现。所有报告的分数均为实体微平均测试F1。对于每个语料库,我们还列出了实体类型的数量。*标记来自同一数据集上公开可用的预训练模型的结果,而其他来自我们的数据集上重新训练的模型。
Speed comparison.
我们将Stanza与现有的工具箱进行比较,以评估注释文本所需的时间(见表4)。对于GPU测试,我们使用单个NVIDIA Titan RTX卡。不出所料,Stanza广泛使用精确的神经模型,使得注释文本所需的时间明显长于SpaCy,但与类似精度的工具箱相比,它仍然具有竞争力,特别是借助GPU加速。
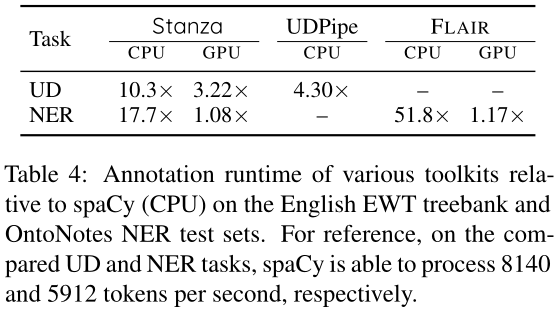
表4:英语EWT Treebak 和OntoNotes NER测试集上与空间(CPU)相关的各种工具箱的注释运行时。作为参考,在比较的UD和NER任务上,SpaCy每秒可以分别处理8140和5912个令牌。
5 Conclusion and Future Work
我们介绍了Stanza,一个支持多种人类语言的Python自然语言处理工具包。我们已经证明,Stanza的神经管道不仅覆盖了人类语言,而且由于其语言不可知的、完全神经结构的设计,在所有任务上都是准确的。同时,Stanza的CoreNLP客户端通过附加的NLP工具扩展了它的功能。
对于今后的工作,我们考虑在近期内改进以下方面:
Stanza中可下载的模型主要在单个数据集上进行训练。为了使模型对许多不同类型的文本具有健壮性,我们希望研究汇集各种兼容数据源以训练每种语言的“默认”模型的可能性;
我们可用的计算量和资源是有限的。因此,我们希望为Stanza建立一个开放的“模型动物园”,以便我们团队以外的研究人员也可以贡献他们的模型,并从其他人发布的模型中获益;
Stanza被设计用来优化其预测的准确性,但这有时会以计算效率为代价,并限制了工具箱的使用。我们希望进一步研究在工具箱中减少模型大小和加速计算,同时仍然保持相同的精度水平。
我们还想通过添加其他处理器来扩展Stanza的功能,例如用于更丰富文本分析的神经共指解析或关系提取。
【论文阅读】Stanza: A Python Natural Language Processing Toolkit for Many Human Languages[ACL2020]
标签:strong 线性 本地 添加 开发 json 能力 缓冲 display
原文地址:https://www.cnblogs.com/Harukaze/p/14650864.html