标签:ams string ext 说明 tag 思考 括号 mp4 known
想取如下字段里的访问的域名:
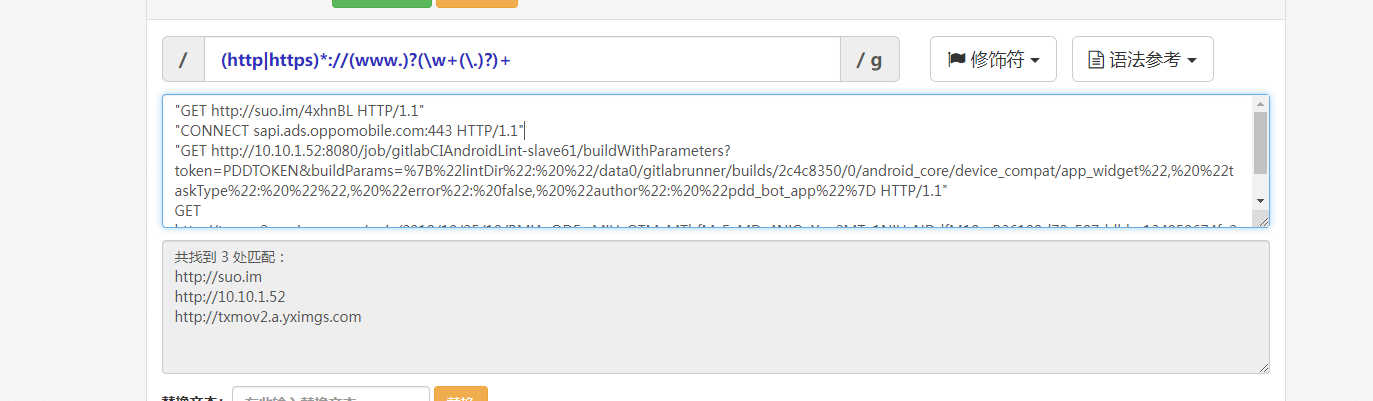
"GET http://suo.im/4xhnBL HTTP/1.1"
"CONNECT sapi.ads.544.com:443 HTTP/1.1"
"GET http://100.110.1.52:8080/job/1/buildWithParameters?token=TOKEN&buildParams=%7B%22lintDir%22:%20%22 HTTP/1.1"
GET http://txmov2.a.yxis.com/u/BMjAxODEwjUzNDdfM18z_B36199d79e3.mp4?tag=1-1598-unknown4849&di=d4402759&bp=10000 HTTP/1.1
一开始思考的时候直接正则匹配http,但发现匹配不到如下字符串的域名:
正则参考:https://blog.csdn.net/yong472727322/article/details/73321935
(http|https)*://(www.)?(\w+(\.)?)+
"CONNECT sapi.ads.oppomobile.com:443 HTTP/1.1"
发现hive有个函数regexp_extract很好:
语法: regexp_extract(string subject, string pattern, int index)
返回值: string
说明:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
第三个参数:
0 是显示与之匹配的整个字符串
1 是显示第一个括号里面的
2 是显示第二个括号里面的字段
hive> select regexp_extract(‘foothebar‘, ‘foo(.*?)(bar)‘, 1) from dual;
the
hive> select regexp_extract(‘foothebar‘, ‘foo(.*?)(bar)‘, 2) from dual;
bar
hive> select regexp_extract(‘foothebar‘, ‘foo(.*?)(bar)‘, 0) from dual;
foothebar
hive> select regexp_extract(‘中国abc123!‘,‘[\\u4e00-\\u9fa5]+‘,0) from dual; //实用:只匹配中文
hive> select regexp_replace(‘中国abc123‘,‘[\\u4e00-\\u9fa5]+‘,‘‘) from dual; //实用:去掉中文
注意,在有些情况下要使用转义字符,等号要用双竖线转义,这是java正则表达式的规则。
参考:
HIVE字符串处理技巧【总结】:https://zhuanlan.zhihu.com/p/82601425
regexp_extract(request, ‘\\w+ ((http[s]?)?(://))?([^/\\s]*)(/?.*) HTTP/.*‘, 4) as domain,
regexp_extract(request, ‘"(.*?)( )‘, 1) as method,
regexp_extract(request, ‘(HTTP/.*)(")‘, 1) as protocol,
hive parse_url 只能解析标准的url
https://blog.csdn.net/oracle8090/article/details/79637982
https://blog.csdn.net/weixin_30861459/article/details/96178140
标签:ams string ext 说明 tag 思考 括号 mp4 known
原文地址:https://www.cnblogs.com/Mang0/p/14655528.html