标签:一个 评分 nbsp 评价 Dimension namespace 日本 效果图 else
这是老师上课布置的一道算法题
刚开始理解还是有些困难的
查阅一些大佬的博客做出如下理解:
1.首先你要先确定你要对相关数据分成几类(或者说是几组) —— 先假定为k
2.再从这些数据中选出 k 个数据(成员)为组长(centroid) —— 为便于理解,下面把数据看成成员
>可以随机选择,也可以指定第一个
3.再遍历每一个成员,判断哪个成员属于哪个组长
>判断方法:强强联合
>’实力‘强的分为一组,’实力弱的分为一组‘ (也可以细分多个组,这里只是举列k = 2)
4.分完组后,再寻找新的组长,但是这个组长并不在成员中寻找,可以理解为再造一个成员当组长
>寻找方法:取均值
>假如每个成员的 ’强弱‘ 根据 语 数 英 三门成绩来决定
>那么该组的新组长的语数英成绩就是该组 语数英 的平均成绩
>这就是一个三维的比较
>像如果单纯比身高的话就是一维的比较
5.然后只需要重复循环 n 次(自己随便定)就可以达到聚类的效果了
>n的大小要根据不同情况来调节,来达到更好的聚类效果
下面就来看看老师给的ppt上面讲了些啥子吧:—— 有些复制不上来的我就先翻译一下吧
1.部分概念
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标(还有按比例 --- 正余弦好像),即认为两个对象的距离越近,其相似度就越大。
该算法认为类是有距离靠近的对象组成的,因此把得到紧凑且独立的类作为最终目标
2.举例

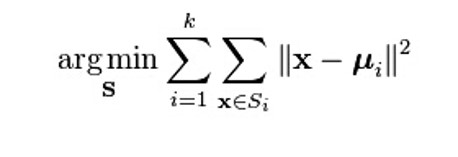
这表达式看不懂呢就随便猜猜是干嘛的就行,影响不大

我就不解释了,老师给的ppt我也没怎么看,我就照搬下来了
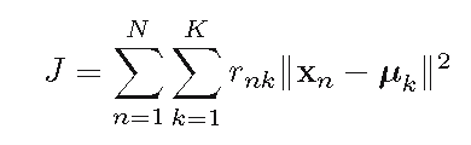

-------------------------------------------------------------------------------------------------------

-----------------------------------------------------------
![]()
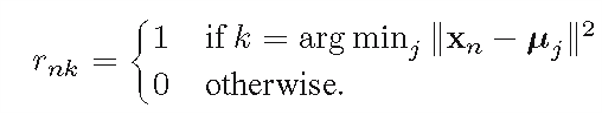
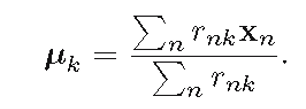
效果图变化过程:
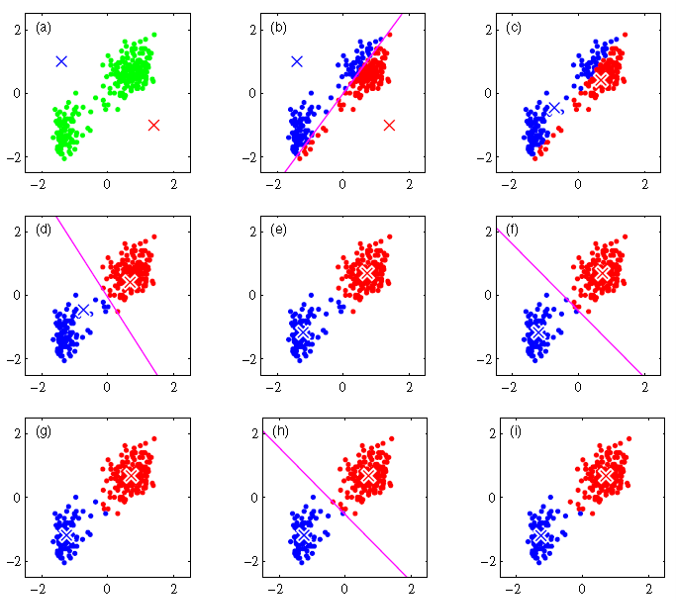
最后给上我的代码和修改老师的源代码
1 /*K-Means*/ 2 //#include "stdafx.h" 3 #include<iostream> 4 #include<cmath> 5 #include<vector> 6 #include<ctime> 7 #include<cstdlib> 8 using namespace std; 9 typedef unsigned int uint; 10 11 class Cluster 12 { 13 public: 14 15 vector<double> centroid; 16 vector<uint> samples; 17 }; 18 double cal_distance(vector<double> a, vector<double> b)//计算距离 19 { 20 uint da = a.size(); 21 uint db = b.size(); 22 if (da != db) //cerr << "Dimensions of two vectors must be same!!\n"; 23 { 24 cout<<"ERROR"<<endl; 25 return 0; 26 } 27 double val = 0.0; 28 for (uint i = 0; i < da; i++) 29 { 30 val += pow((a[i] - b[i]), 2); 31 } 32 return pow(val, 0.5); 33 } 34 vector<Cluster> k_means(vector<vector<double> > trainX, uint k, uint maxepoches) 35 { 36 const uint row_num = trainX.size(); // 训练的样本大小 37 const uint col_num = trainX[0].size(); // 维度 38 39 /*初始化聚类中心*/ 40 vector<Cluster> clusters(k); 41 uint seed = (uint)time(NULL); 42 43 for (uint i = 0; i < k; i++) 44 { 45 srand(seed); 46 int c = rand() % row_num; 47 clusters[i].centroid = trainX[c]; 48 seed = rand(); 49 } 50 /*多次迭代直至收敛,本次试验迭代100次*/ 51 for (uint it = 0; it < maxepoches; it++) 52 { 53 /*每一次重新计算样本点所属类别之前,清空原来样本点信息*/ 54 for (uint i = 0; i < k; i++) 55 { 56 clusters[i].samples.clear(); 57 } 58 /*求出每个样本点距应该属于哪一个聚类*/ 59 for (uint j = 0; j < row_num; j++) 60 { 61 /*都初始化属于第0个聚类*/ 62 uint c = 0; 63 double min_distance = cal_distance(trainX[j], clusters[c].centroid); // 寻找距离最小的 64 for (uint i = 1; i < k; i++) 65 { 66 double distance = cal_distance(trainX[j], clusters[i].centroid); 67 if (distance < min_distance) 68 { 69 min_distance = distance; 70 c = i; 71 } 72 } 73 clusters[c].samples.push_back(j); 74 } 75 76 /*更新聚类中心*/ 77 for (uint i = 0; i < k; i++) 78 { 79 vector<double> val(col_num, 0.0); // 新组长 80 for (uint j = 0; j < clusters[i].samples.size(); j++) 81 { 82 uint sample = clusters[i].samples[j]; // i组j小弟 83 for (uint d = 0; d < col_num; d++) 84 { 85 val[d] += trainX[sample][d]; 86 if (j == clusters[i].samples.size() - 1) 87 clusters[i].centroid[d] = val[d] / clusters[i].samples.size(); 88 } 89 } 90 } 91 } 92 return clusters; 93 } 94 95 int main() 96 { 97 vector<vector<double> > trainX(9, vector<double>(1, 0)); 98 //对9个数据{1 2 3 11 12 13 21 22 23}聚类 99 double data = 1.0; 100 uint kk = 2; 101 for (uint i = 0; i < 9; i++) 102 { 103 trainX[i][0] = data; 104 if ((i + 1) % kk == 0) data += 8; 105 else data++; 106 } 107 108 /*k-means聚类*/ 109 vector<Cluster> clusters_out = k_means(trainX, kk, 100); 110 cout << "***********" << kk << endl; 111 112 /*输出分类结果*/ 113 for (uint i = 0; i < clusters_out.size(); i++) 114 { 115 cout << "Cluster " << i << " :" << endl; 116 117 /*子类中心*/ 118 cout << "\t" << "Centroid: " << "\n\t\t[ "; 119 for (uint j = 0; j < clusters_out[i].centroid.size(); j++) 120 { 121 cout << clusters_out[i].centroid[j] << " "; 122 } 123 cout << "]" << endl; 124 125 /*子类样本点*/ 126 cout << "\t" << "Samples:\n"; 127 for (uint k = 0; k < clusters_out[i].samples.size(); k++) 128 { 129 uint c = clusters_out[i].samples[k]; 130 cout << "\t\t[ "; 131 for (uint m = 0; m < trainX[0].size(); m++) 132 { 133 cout << trainX[c][m] << " "; 134 } 135 cout << "]\n"; 136 } 137 } 138 return 0; 139 }
老师给的是一维的,
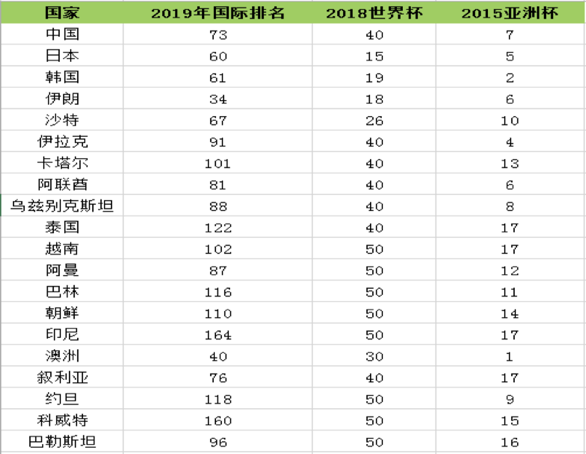
这个表格是要聚类的三维数据
1 #include <iostream> 2 #include <cstring> 3 #include <cmath> 4 #include <cstdlib> 5 #include <vector> 6 #include <ctime> 7 using namespace std; 8 class Country{ 9 public: 10 Country &operator=(Country c) 11 { 12 this->Paim = c.Paim; 13 this->m_Name = c.m_Name; 14 return *this; 15 } 16 string m_Name; 17 vector<int>Paim; 18 }; 19 class Cluster{ 20 public: 21 Country Centroid; 22 vector<int>Samples; 23 }; 24 25 double cal_(Country a,Country b) 26 { 27 int la = a.Paim.size(); 28 int lb = b.Paim.size(); 29 30 if(la != lb) 31 { 32 cout<<"ERROR"<<endl; 33 return 0; 34 } 35 36 double val = 0.0; 37 for(int i = 0;i < la;i++) 38 { 39 val += pow((a.Paim[i] - b.Paim[i]),2); 40 } 41 42 return pow(val,0.5); 43 } 44 45 vector<Cluster> k_means(vector<Country>TrainX,int k,int train_num) 46 { 47 vector<Cluster>Clu(k); 48 const int row_num = TrainX.size(); // 计算有多少国家 49 const int col_num = TrainX[0].Paim.size(); // 计算有多少个评分标准 50 51 //初始化 52 int seed = (unsigned)time(NULL); 53 for(int i = 0;i < k;i++) 54 { 55 srand(seed); 56 int c = rand() % row_num; 57 Clu[i].Centroid = TrainX[c]; 58 seed = rand(); 59 } 60 61 for(int t = 0;t < train_num;t++) // 训练次数 62 { 63 //清空小弟 64 for(int i = 0;i < k;i++) 65 { 66 Clu[i].Samples.clear(); 67 } 68 for(int it = 0;it < row_num;it++) // 给每组的组长分配组员 69 { 70 int c = 0; 71 double min_d = cal_(Clu[c].Centroid,TrainX[it]); // 先默认该成员是属于第一组 72 for(int i = 1;i < k;i++) // 寻找到底属于哪一组 73 { 74 double dist = cal_(Clu[i].Centroid,TrainX[it]); 75 if(min_d > dist) 76 { 77 min_d = dist; 78 c = i; 79 } 80 } 81 Clu[c].Samples.push_back(it); 82 } 83 84 85 //分配完了再重新选择组长 —— 虚拟组长 86 for(int i = 0;i < k;i++) // k组 87 { 88 int s = Clu[i].Samples.size(); // 该组有多少个组员 89 Country val; 90 for(int j = 0;j < col_num;j++) 91 { 92 val.Paim.push_back(0); 93 } 94 for(int j = 0;j < s;j++) 95 { 96 for(int l = 0;l < col_num;l++) // 维度 97 { 98 val.Paim[l] += TrainX[Clu[i].Samples[j]].Paim[l] / s; 99 } 100 } 101 Clu[i].Centroid = val; 102 } 103 } 104 return Clu; 105 } 106 int main() 107 { 108 vector<Country>C; 109 int n = 12; //就实验12个数据吧 数据太多不想打了 110 Country c[n]; 111 112 c[0].m_Name = "中国"; 113 c[0].Paim.push_back(73); 114 c[0].Paim.push_back(40); 115 c[0].Paim.push_back(7); 116 117 c[1].m_Name = "日本"; 118 c[1].Paim.push_back(60); 119 c[1].Paim.push_back(15); 120 c[1].Paim.push_back(5); 121 122 c[2].m_Name = "韩国"; 123 c[2].Paim.push_back(61); 124 c[2].Paim.push_back(19); 125 c[2].Paim.push_back(2); 126 127 c[3].m_Name = "伊朗"; 128 c[3].Paim.push_back(34); 129 c[3].Paim.push_back(18); 130 c[3].Paim.push_back(6); 131 132 c[4].m_Name = "沙特"; 133 c[4].Paim.push_back(67); 134 c[4].Paim.push_back(26); 135 c[4].Paim.push_back(10); 136 137 c[5].m_Name = "伊拉克"; 138 c[5].Paim.push_back(91); 139 c[5].Paim.push_back(40); 140 c[5].Paim.push_back(4); 141 142 c[6].m_Name = "卡塔尔"; 143 c[6].Paim.push_back(101); 144 c[6].Paim.push_back(40); 145 c[6].Paim.push_back(13); 146 147 c[7].m_Name = "阿联酋"; 148 c[7].Paim.push_back(81); 149 c[7].Paim.push_back(40); 150 c[7].Paim.push_back(6); 151 152 c[8].m_Name = "乌兹别克斯坦"; 153 c[8].Paim.push_back(88); 154 c[8].Paim.push_back(40); 155 c[8].Paim.push_back(8); 156 157 c[9].m_Name = "泰国"; 158 c[9].Paim.push_back(122); 159 c[9].Paim.push_back(40); 160 c[9].Paim.push_back(17); 161 162 c[10].m_Name = "越南"; 163 c[10].Paim.push_back(102); 164 c[10].Paim.push_back(50); 165 c[10].Paim.push_back(17); 166 167 c[11].m_Name = "阿曼"; 168 c[11].Paim.push_back(87); 169 c[11].Paim.push_back(50); 170 c[11].Paim.push_back(12); 171 172 for(int i = 0;i < n;i++) 173 { 174 C.push_back(c[i]); 175 } 176 int kk = 2; 177 vector<Cluster> clusters_out = k_means(C, kk,100); 178 179 for(int i = 0;i < clusters_out.size();i++) 180 { 181 182 } 183 cout << "***********" << kk << endl; 184 185 /*输出分类结果*/ 186 for (int i = 0; i < clusters_out.size(); i++) 187 { 188 cout << "Cluster " << i << " :" << endl; 189 190 /*子类中心*/ 191 cout << "\t" << "Centroid: " << "\n\t\t[ "; 192 for (int j = 0; j < clusters_out[i].Centroid.Paim.size(); j++) 193 { 194 cout << clusters_out[i].Centroid.Paim[j] << " "; 195 } 196 cout << "]" << endl; 197 198 /*子类样本点*/ 199 cout << "\t" << "Samples:\n"; 200 for (int k = 0; k < clusters_out[i].Samples.size(); k++) 201 { 202 int c = clusters_out[i].Samples[k]; 203 cout << "\t\t[ "; 204 cout<<C[c].m_Name<<"\t"; 205 for (int m = 0; m < C[0].Paim.size(); m++) 206 { 207 cout << C[c].Paim[m] << " "; 208 } 209 cout << "]\n"; 210 } 211 } 212 return 0; 213 }
就先这样吧
再把输出给一下吧’
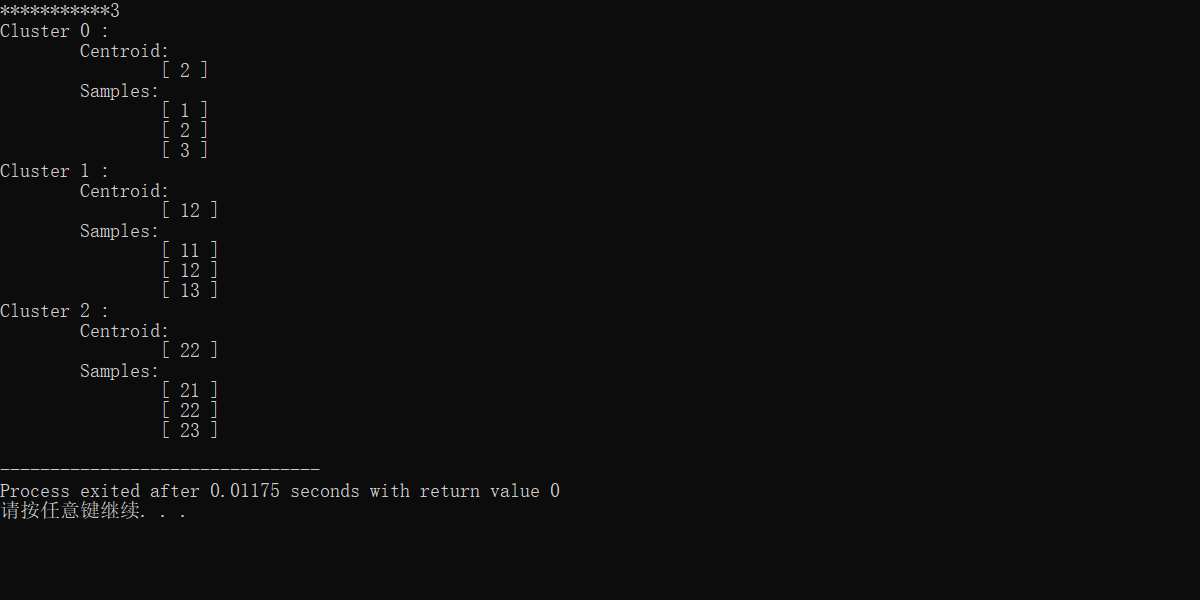
----------------------------------
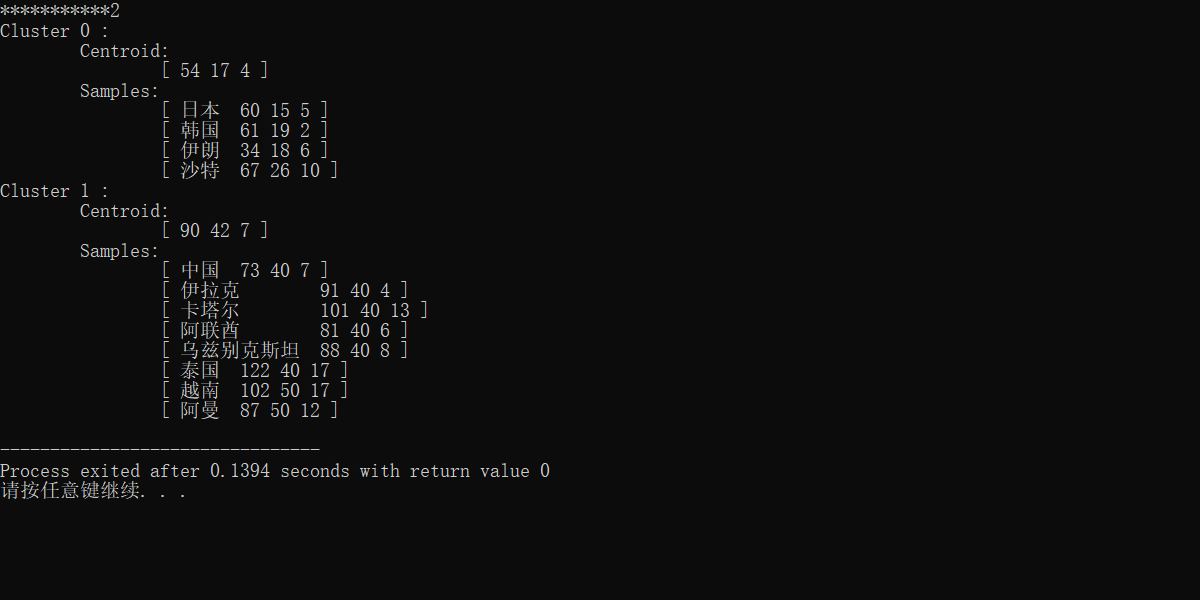
标签:一个 评分 nbsp 评价 Dimension namespace 日本 效果图 else
原文地址:https://www.cnblogs.com/Alan-Wangyoubiao/p/14689070.html