标签:有序表 有用 的区别 primary char 记录 and inf 重要
SQL语句的执行顺序
(1)from
(3) join
(2) on
(4) where
(5)group by(开始使用select中的别名,后面的语句中都可以使用)
(6) avg,sum....
(7)having
(8) select
(9) distinct
(10) order by
删除表
delete from user 与 turncat table user 的区别:
delete是清空表的数据(不会刷新自增字段的记录数),turncat是删除表然后新建表(会刷新自增字段的记录数)
聚合查询
count()统计指定列不为NULL (空) 的记录行数
sum()计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0
max()计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算
min()计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算
avg()计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0
分组查询
分组之后,select 的后面只能跟被分组字段或者聚合函数
select product.category_id,count(*) from product group by product.category_id
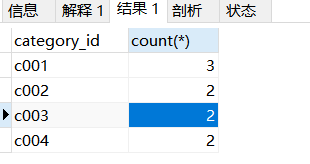
group by内部执行过程: 
分组后对数据进行过滤,where是在分组之前对数据进行过滤
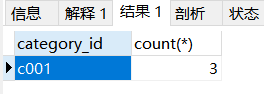
select product.category_id,count(*) from product group by product.category_id having count(*)>2
分页查询
每页显示5条,从0开始
limit M,N
M:从第几条数据开始 M=(当前页数-1)*(每页显示条数)N
N:一页显示多少条数据(一般是固定的)
第一页 : select * from product limit 0,5
第一页 : select * from product limit 5,5
第一页 : select * from product limit 10,5
Insert Into,select语句
从一个表中查询到的数据导入到另外一张表中(字段的类型和数量需要能够匹配的上)
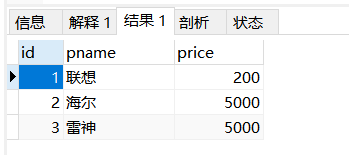
insert into product2 select p.pid,p.pname,p.price from product as p where p.category_id=‘c001‘;
select * from product2
表与表之间的关系
一对一,一对多,多对多
外键约束

声明外键约束(建立实质的约束关系):
建立约束之前,需要确保外键列中不存在主键列中没有的值
#声明外键约束
alter table product #修改表
add constraint product_fk #添加约束的名称,便于以后删除约束
foreign key(category_id) #选择需要添加外键约束的是哪一列
references category(cid); #选择哪个表的外键建立外键约束
根据外键名称删除外键约束:
alter table product drop foreign key product_fk
主表的数据受到从表的依赖是不能够随便删除的
从表的外键的数据的添加也受到主表的约束
多表查询
交叉连接查询:笛卡尔积
交叉连接查询出来的数据有的是有用的数据,有的是无用的数据,可以对查询的东西进行筛选,得到自己需要的数据
select * from category,product
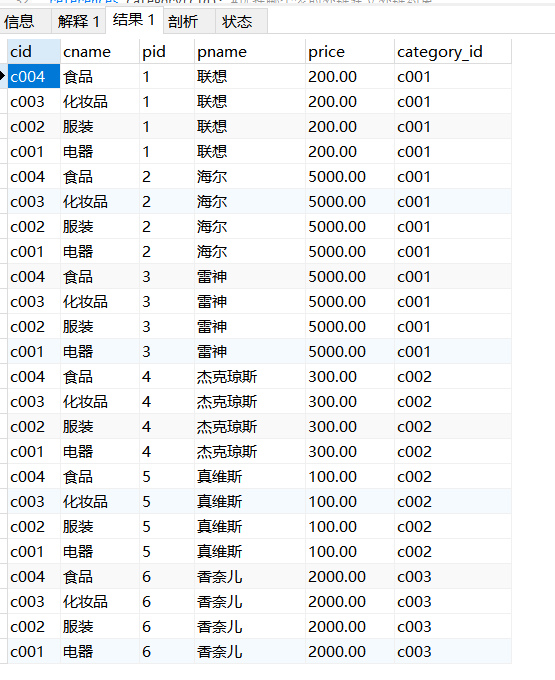
内连接查询:求的是两张表的交集(查询的显示以两张表的交集为主)
隐式内连接:(加上where条件判断,筛出自己需要的数据)
select * from category,product where cid=category_id
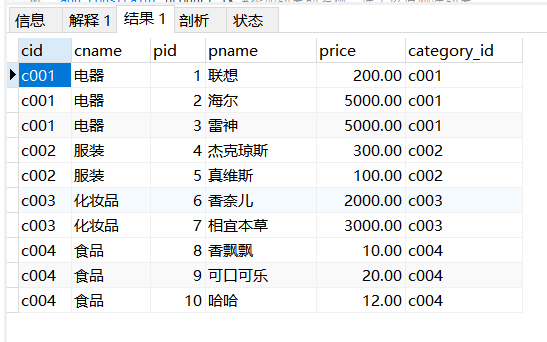
显示内连接:(使用inner join)
select * from category as c inner join product as p on c.cid=p.category_id
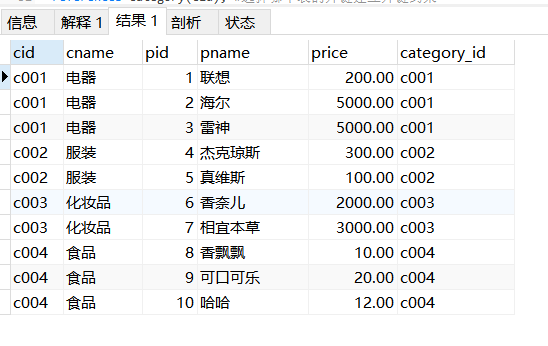
外连接查询:(outer join --outer可以省略)对于有对应的数据输出,没有对应的数据补NULL
左外连接查询:(left outer join --outer可以省略,以左表的数据为主)左边的表的信息会全部显示,右边的表没有对应的数据则补NULL
select * from category as c left join product as p on c.cid=p.category_id
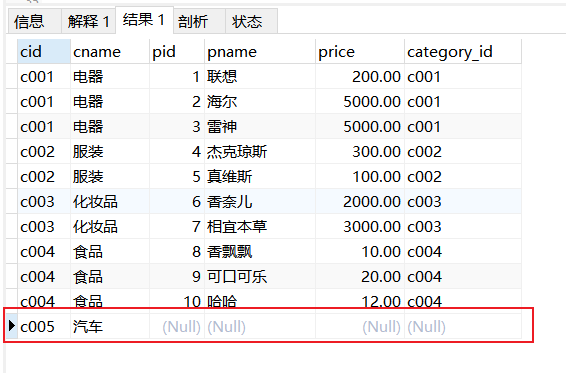
右外连接查询:同理左外连接(右与左相对)
select * from category as c right join product as p on c.cid=p.category_id
子查询:一个select查询中嵌套另一个select查询(select的嵌套查询)(子查询中的表需要取一个别名)
Every derived table must have its own alias(每一个派生表都需要一个别名)
将查询的结果当做一张表或者一个值,与其他的表建立连接查询
select * from product as p where p.category_id=(select c.cid from category as c where c.cname=‘化妆品‘)
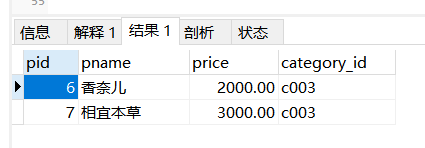
in的用法
select * from product as p where p.category_id in (‘c001‘,‘c002‘);
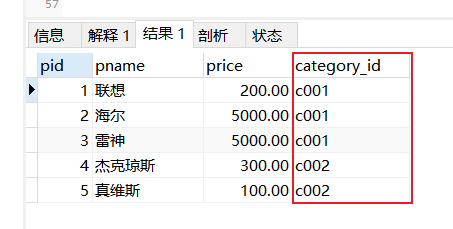
MySQL索引
概念:索引是MySQL中的一种重要的数据库对象,它是数据库性能调优技术的基础,常用于实现数据的快速检索。
索引就是根据表中的一列或若干列按照一定顺序建立的列值与记录行之间的对应关系,实质上是一张描述索引列的列值与原表中记录行之间--对应关系的有序表。
在MySQL中,通常两种方式访问数据库表的行数据:
顺序访问:
顺序访问时在表中实行全表扫描,从头到尾逐行遍历,直到在无序的行数据中找到符合条件的目标数据。这种方式实现比较简单,但是当表中有大量的数据时,效率极低。
索引访问:
索引访问是通过遍历索引来直接访问表中的记录行的方式。使用这种方式的前提是对表建立一个索引,在列上创建索引之后,查找数据时可以直接根据该列上的索引找到对应记录行的位置,从而快捷的查找到数据。索引存储了指定列数据值的指针,根据指定的排序顺序对这些指针排序。
索引的两大分类:
B-树索引:
哈希索引:
根据索引的用途,MySQL中的索引分为3类:
普通索引:最基本的索引类型,唯一的任务就是加快对数据的访问速度,没有任何限制,创建普通索引时,通常使用的关键字是INDEX或KEY
唯一性索引:不允许索引列具有相同索引值的索引。数据列的值不会相同,使用关键字UNIQUE将这个字段定义为唯一性索引,目的往往不是为了提高访问速度,而是为了避免值的重复。
主键索引:一种唯一性索引,不允许重复值,不允许为空,每个表只能有一个主键,可以在创建的时候使用PRIMARYKEY指定也可以后期修改表的时候添加。
索引操作;
创建索引:
普通索引(两种方式):
直接创建索引:create index price_index on product(price)
修改表结构创建索引:alter table product add index pname_index(pname)
创建表的时候直接指定:
create table product3(
pid int not null,
pname varchar(255) not null,
index pname_index(pname)
)
查询索引:
#查询表索引
show index from product;
#查询数据库索引
select * from mysql.innodb_index_stats a where a.database_name=‘BigData‘
#查询某一表索引
select * from mysql.innodb_index_stats a where a.database_name=‘BigData‘ and a.table_name like ‘%product%‘
删除索引:
drop index pname_index on product3;
alter table product3 add index pname_index(pname);
alter table product3 drop index pname_index;
索引的使用原则:
对表中的数据进行增删改的时候是会对创建了索引的列进行维护的,所以如果表中的数据操作的很是频繁的话就需要考虑创建索引的必要性。
对于不常使用的列最好不创建索引,因为不常使用的到,创建了反而降低了维护的速度。增大了空间要求。
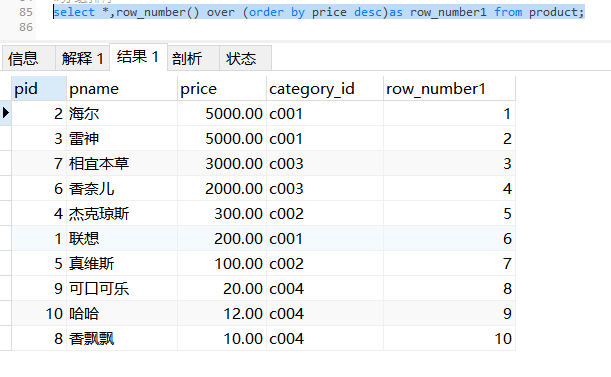
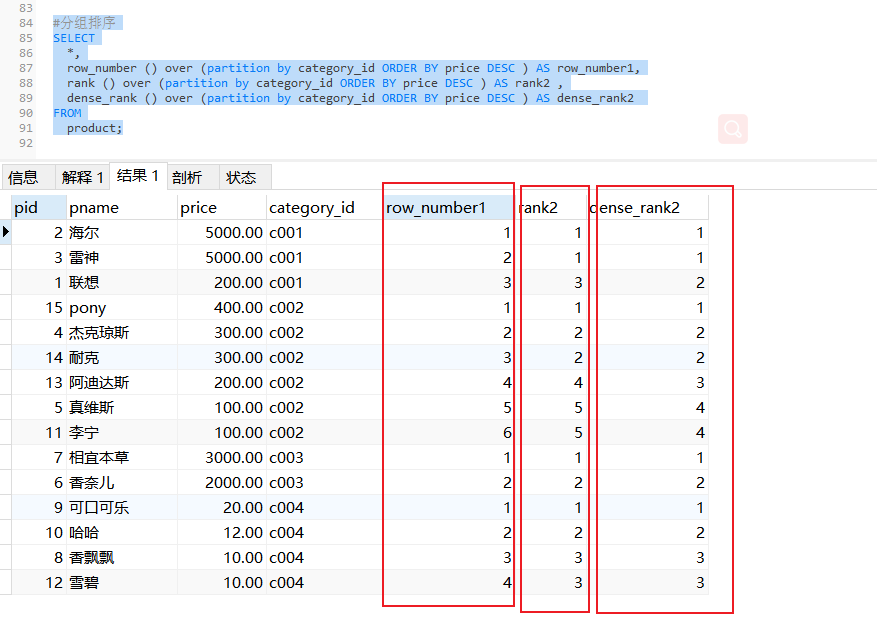
开窗函数(MySQL8.0的新特性):(row_number(),rank(),dense_rank())
应用于分组排序的场合
row_number:不管排名是否有相同的都按照1.2.3.4........n
rank:排名相同的名次一样,同一排名有几个,后面排名就会跳过几次1.2.2.4........n
dense_rank:排名相同的名次一样,且后面名次不跳跃1.2.2.3.3.3.4.4.......n
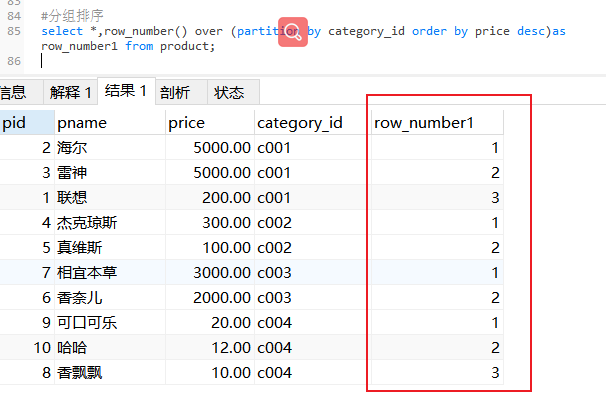
全表排序打编号
标签:有序表 有用 的区别 primary char 记录 and inf 重要
原文地址:https://www.cnblogs.com/Gpengbolg/p/14698019.html