标签:应用 了解 语言 方便 上下文 方式 去掉 types 静态
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,一类是编译,一类是解释。
解释型语言
程序执行前不需要先进行编译,而是在执行时才通过解释器对代码进行翻译,翻译一句然后执行一句,直至结束。
编译型语言
编译性语言写的程序在被执行之前,需要一个专门的编译过程,把程序编译成为机器语言(二进制代码)的文件,比如 exe 文件,此后再运行时就不用重新翻译了,直接使用编译后的结果文件(exe 文件)来运行就行。
因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,因此效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着 Java 等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。用 Java 来举例,Java 首先是通过编译器编译成字节码文件(不是二进制码),然后在运行时通过解释器(JVM)给解释成机器代码才能在各个平台执行,这同时也是 Java 跨平台的原因。所以我们说 Java 是一种先编译后解释的语言。
总结:将由高级语言编写的程序文件转换为可执行文件(二进制的)有两种方式,编译和解释,编译是在程序运行前,已经将程序全部转换成二进制码,而解释是在程序执行的时候,边翻译边执行。
其实 Python 和 Java 一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下 Python 程序的运行过程。
当我们在命令行中输入 python hello.py 时,其实是激活了 Python 的“解释器”,告诉“解释器”要开始工作了。可是在“解释”之前,其实执行的第一项工作和 Java 一样,是编译。
熟悉 Java 的同学可以想一下我们在命令行中如何执行一个 Java 的程序:
只是我们在用 Eclipse 等 IDE 时,将这两步给融合成了一步而已。其实 Python 也一样,当我们执行 python hello.py 时,他也一样执行了这么一个过程,所以我们应该这样来描述 Python,Python 是一门先编译后解释的语言。
在说这个问题之前,我们先来说两个概念,PyCodeObject 和 pyc 文件。
当 Python 程序首次运行时,编译的结果保存在位于内存中的 PyCodeObject 中。当 Python 程序运行结束时,Python 解释器则将 PyCodeObject 写回到硬盘中的 pyc 文件中。
当 Python 程序第二次运行时,首先程序会在硬盘中寻找 pyc 文件,如果找到则直接载入,否则就重复上面的过程。
所以我们应该这样来定位 PyCodeObject 和 pyc 文件,我们说 pyc 文件其实是 PyCodeObject 的一种持久化保存方式。
也就是说保存 pyc 文件是为了下次再次使用该脚本时避免重复编译,以此来节省时间。因此,只执行一次的脚本,就没必要保存其编译结果 pyc 文件,这样只是浪费空间。下面举例解释。
a.py 代码如下:
print("hello world")
执行 a.py:
E:\test>python a.py hello world
此时我们可以发现,在执行所在目录下并没有产生 pyc 文件,仍只有 a.py。
新增 b.py,代码如下:
import a
执行 b.py:
E:\test>python b.py hello world
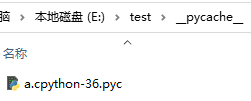
此时我们可以发现,pyc 文件产生了。
编译型语言的优点在于,我们可以在程序运行时不用解释,而直接利用已经“翻译”过的文件。也就是说,我们之所以要把 py 文件编译成 pyc 文件,最大的优点在于我们在运行程序时,不需要重新对该模块进行重新的解释。
所以,我们需要编译成 pyc 文件的应该是那些可以重用的模块,这与我们在设计软件时是一样的目的。所以 Python 解释器认为:只有 import 进来的模块,才是需要被重用的模块。
这个时候也许有人会说,不对啊!你的这个问题没有被解释通啊,我的 test.py 不是也需要运行么,虽然不是一个模块,但是以后我每次运行也可以节省时间啊!OK,我们从实际情况出发,思考下我们在什么时候才可能运行 python xxx.py:
第一种情况(执行测试),这时哪怕所有的文件都没有 pyc 文件都是无所谓的。
第二种情况(开启一个 web 进程),我们试想一个 web 程序通常这样执行:
或
然后这个程序就类似于一个守护进程一样一直监听着 8181/9002 端口,而一旦中断,只可能是程序被杀死,或者其他的意外情况,那么你需要恢复要做的是把整个的 Web 服务重启。既然一直监听着,把 PyCodeObject 一直放在内存中就足够了,完全没必要持久化到硬盘上。
最后一种情况(执行一个程序脚本),一个程序的主入口其实很类似于 Web 程序中的 Controller,也就是说,它负责的应该是 Model 之间的调度,而不包含任何的主逻辑在内,如在 http://www.cnblogs.com/kym/archive/2010/07/19/1780407.html 中所提到,Controller 应该就是一个 Facade(外观模式),无任何的细节逻辑,只是把参数转来转去而已。做算法的同学可以知道,在一段算法脚本中,最容易改变的就是算法的各个参数,那么这个时候给持久化成 pyc 文件就未免有些画蛇添足了。
所以我们可以这样理解 Python 解释器的意图,Python 解释器只把我们可能重用到的模块持久化成 pyc 文件。
说完了 pyc 文件,可能有人会想到,每次 Python 的解释器都把模块给持久化成了 pyc 文件,那么当我的模块发生了改变的时候,是不是都要手动地把以前的 pyc 文件 remove 掉呢?
当然 Python 的设计者是不会犯这么白痴的错误的。而这个过程其实就取决于 PyCodeObject 是如何写入 pyc 文件中的。
我们来看一下 import 过程的源码吧:
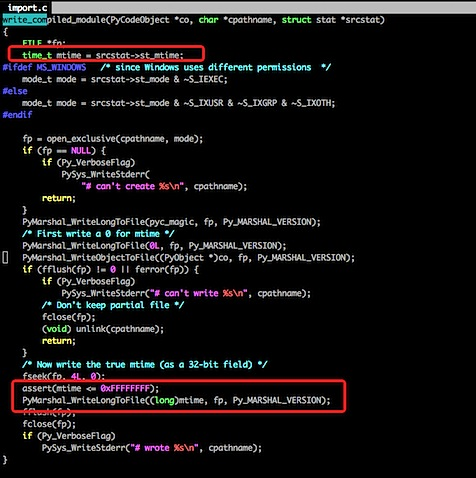
这段代码比较长,我们只看标注的代码,其实它在写入 pyc 文件的时候,写了一个 Long 型变量,变量的内容则是文件的最近修改日期,同理,我们再看下加载 pyc 的代码:
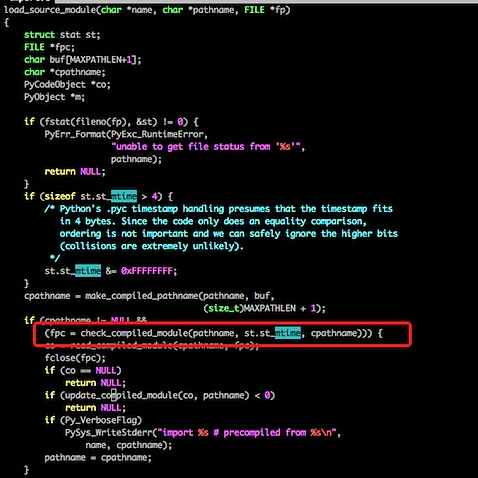
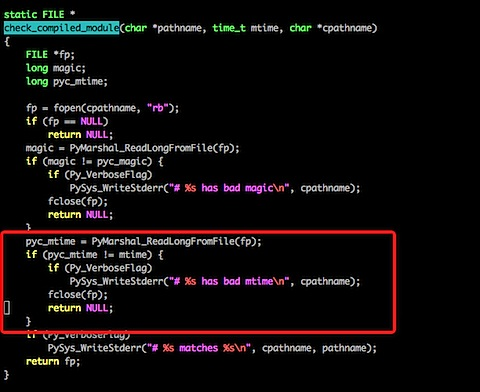
不用仔细看代码,我们可以很清楚地看到原理,其实每次在加载 pyc 之前都会先检查一下 py 文件和 pyc 文件保存的最后修改日期,如果不一致则重新生成一份 pyc 文件。
其实了解 Python 程序的执行过程对于大部分程序员(包括 Python 程序员)来说意义都是不大的,那么真正有意义的是,我们可以从 Python 的解释器的做法上学到什么,我认为有这样的几点:
所谓动态类型语言,就是(变量、属性、方法以及方法的返回值)类型的检查(确定)是在运行时才做。
即编译时与类型无关。一般在变量使用之前不需要声明变量类型,而变量的类型通常是由被赋的值的类型决定。 如 Php、Python 和 Ruby。
与动态类型语言正好相反,在编译时便需要确定类型的语言。即写程序时需要明确声明变量类型。如 C/C++、Java、C# 等。
对于动态语言与静态语言的区分,套用一句流行的话就是:Static typing when possible, dynamic typing when needed。
强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。因此强类型定义语言是类型安全的语言。
数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。
Python 属于动态类型语言和弱类型语言。
严格意义上,强类型与静态类型不是一回事,同理弱类型和动态类型。
静态类型语言:
动态类型语言:
在强类型、静态类型语言的支持者,与动态类型、自由形式的支持者之间,经常发生争执:
根据维基百科,动态(编程)语言的定义如下:
动态编程语言是高级编程语言的一个类别,在计算机科学领域已被广泛应用。它是一类在运行时可以改变其结构的语言,例如新的函数、对象、甚至代码可以被引进,已有的类、函数也可以被删除或是其他结构上的变化。
动态语言目前非常具有活力,例如 JavaScript 便是一个动态语言,除此之外如 PHP、Ruby、Python 等也都属于动态语言,而 C、C++ 等语言则不属于动态语言。
动态语言是一门在运行时可以改变其结构的语言,这句话如何理解?

class Person(object):
def __init__(self, name=None, age=None):
self.name = name
self.age = age
Jack = Person("Jack",18)
print(Jack.age)
在上述代码中,我们定义了 Person 类,然后创建了 Jack 对象,打印对象的 age 属性,这没毛病。现实中人除了名字和年龄,还会有其他属性,例如身高和体重。我们尝试打印一下身高属性。
print(Jack.height)
毫无疑问,这会报错,因为 Person 类中没有定义 height 属性。
但是如果在程序运行的时候添加 height 属性,会发生什么呢?
Jack.height = 170 print(Jack.height) # 输出结果:170 setattr(Jack, ‘height‘, 170) print(Jack.height) # 输出结果:170
在上述代码中,我们给 Jack 添加了 height 属性,然后打印,没有报错,可以输出结果。
我们再打印一下对象的属性:
print(Jack.__dict__) # 输出结果:{‘name‘: ‘Jack‘, ‘age‘: 18, ‘height‘: 170}
本来对象是没有 height 属性,但是可以在程序运行过程中给实例对象动态绑定属性,这就是动态语言的魅力。
需要注意:
Mia = Person(‘Mia‘, 18)
print(Mia.__dict__) # 输出结果:{‘name‘: ‘mia‘, ‘age‘: 18}
Mia 对象居然没有 height 属性。为什么?事实上我们只是给类示例动态地绑定了一个属性,而不是给类绑定属性,所以重新创建的对象是没有 height 属性的。如果想要给类添加,也是可以的。
Person.height = None
Mia = Person("Mia", 18)
print(Mia.height) # 输出结果:None
class Person(object):
def __init__(self,name=None,age=None):
self.name = name
self.age = age
def speak_name(self):
print(self.name)
Jack = Person("Jack", 18)
Jack.speak_name = speak_name
Jack.speak_name(Jack) # Jack
print(Jack.__dict__) # {‘name‘: ‘Jack‘, ‘age‘: 18, ‘speak_name‘: <function speak_name at 0x000001F86CAE1E18>}
Mia = Person("Mia", 18)
print(Mia.__dict__) # {‘name‘: ‘Mia‘, ‘age‘: 18}
在上述代码中,对象 Jack 的属性中已经成功添加了 speak_name 函数。但是!有没有感觉 Jack.speak_name(Jack) 这个语句很别扭。按习惯来说,应该 Jack.speak_name() 就行了。如果想要达到这种效果,应该要像下面这样子做:
import types Jack.speak_name = types.MethodType(speak_name, Jack) Jack.speak_name() # 输出结果:Jack
其中 MethodType 用于绑定方法对象。
import types
class Person(object):
def __init__(self, name=None, age=None):
self.name = name
self.age = age
def speak_ok(cls):
print(OK)
Person.speak_name = types.MethodType(speak_ok, Person)
Person.speak_ok() # OK
Mia = Person("Mia", 18)
delattr(Mia,‘height‘) # 等价于 del Mia.height
print(Mia.__dict__)
# 输出结果:{‘name‘: ‘mia‘, ‘age‘: 18}
通过以上例子可以得出一个结论:相对于动态语言,静态语言具有严谨性!所以,玩动态语言的时候,小心动态的坑!
如果我们想要限制实例对象的属性怎么办?比如,只允许对 Person 的实例对象添加 name 和 age 属性。
为了达到限制的目的,Python 允许在定义类的时候,定义一个 __slots__() 方法,来限制该实例对象能添加的属性:
>>> class Person:
... __slots__ = ("age", "name")
...
>>> p = Person()
>>> p.age = 12
>>> p.name = "xiaoming"
>>> p.hobby = "football"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: ‘Person‘ object has no attribute ‘hobby‘
注意:__slots__ 定义的属性仅对当前类的实例对象起作用,对继承的子类是不起作用的:
>>> class Student(Person): ... pass ... >>> s = Student() >>> s.hobby = "football" >>>
眼下 Python 应用非常广泛,不论是 DevOps、数据科学、Web 开发还是安全领域,都在用 Python——但是它在速度上却没有任何优势。
与 C、C++、C# 或 Python 相比,Java 的速度如何?答案很大程度上依赖于你需要运行的应用种类。世上没有完美的性能测试,但计算机语言评测游戏(Computer Language Benchmarks Game)是个很好的测试方式:http://algs4.cs.princeton.edu/faq/。
与 Java、C#、Go、JavaScript、C++ 等其他语言相比,Python 是最慢的语言之一。这里包括:
本文中所说的“Python”是指语言的具体实现,即 CPython。
下图是 Python 3 与 Java 的速度比较:
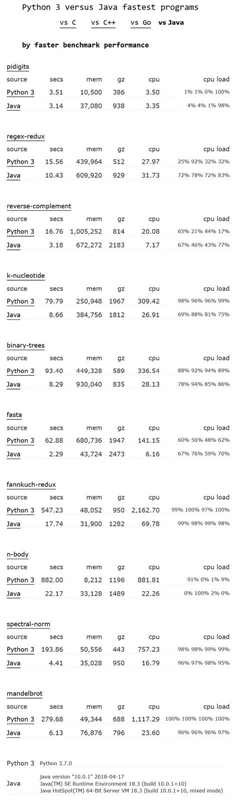
如果 Python 完成相同的任务要花费其他语言二至十倍的时间,那么它为什么慢,能不能更快一些呢?
以下是几种常见的原因:
究竟哪个原因对性能的影响最大呢?
GIL 是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程运行。即使在多核 CPU 上运行,只要使用了 GIL 的解释器也只允许某一时刻只能执行一个线程。
首先要理解 Python 的对象管理机制,CPython 在创建变量时会分配内存,然后用一个计数器计算对该变量的引用的次数。这个概念叫做“引用计数”。如果引用的数目为 0,那就可以将这个变量从系统中释放掉。这样,创建“临时”变量(如在 for 循环的上下文环境中)不会耗光应用程序的内存。
比如:线程 A 与线程 B 同时引用对象 obj,那么 obj 的计数为 2,当 ojb 计数为 0 的时候就会将对象释放。但这个时候就会涉及到一个安全问题,即如果多线程的时候引用一个对象的时候,会出现数据安全问题。
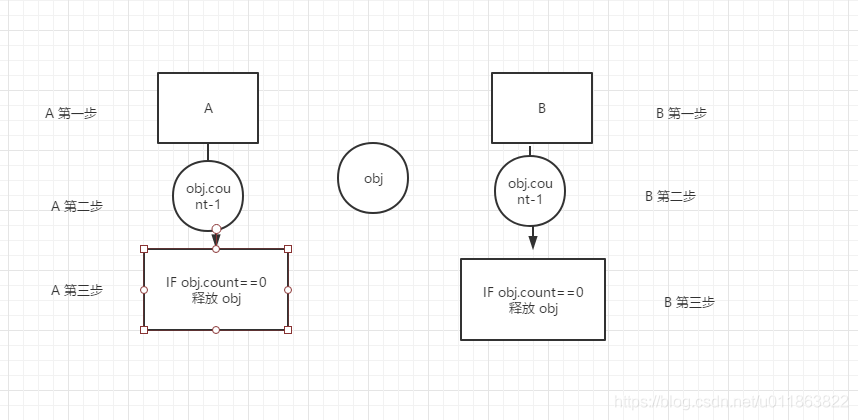
当 A 或 B 运行后 count = 1-1 等于 0,那么 A 或者 B 就会释放 obj,但是另一个线程再调用 obj 的时候发现其已经不存在,因为前面的 obj 已经被释放掉了。所以引用了 GIL,保证了程序数据的安全。
在多线程编程中,你要确保改变内存中的变量时,多个线程不会试图同时修改或访问同一个内存地址。
随之而来的问题就是,如果变量在多个线程中共享,CPython 需要对引用计数器加锁。有一个“全局解释器锁”会谨慎地控制线程的执行。不管有多少个线程,解释器一次只能执行一个操作。
Python 的多线程在多核 CPU 上,只对于 I/O 密集型计算产生正面效果;而当有至少有一个 CPU 密集型线程存在,那么多线程效率会由于 GIL 而大幅下降。
如果应用程序是单线程、单解释器的,那么这不会对速度有任何影响。去掉 GIL 也不会影响代码的性能。
但如果想用一个解释器(一个 Python 进程)通过线程实现并发执行 CPU 密集型任务,那么就会出现下面这种 GIL 竞争:

来自于 David Beazley 的“图解GIL”一文:http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html
如果 Web 应用(如 Django)使用了 WSGI,那么发往 Web 应用的每个请求都会由独立的 Python 解释器执行,且由于 Python 解释器启动很慢,一些 WSGI 实现就支持“守护模式”,保持 Python 进程长期运行。
PyPy 的 GIL 通常要比 CPython 快三倍以上。
Jython 没有 GIL,因为 Jython 中的 Python 线程由 Java 线程表示,因此能享受到 JVM 内存管理系统的好处。
首先,所有 JavaScript 引擎都是用标记-清除垃圾回收算法。如前所述,对 GIL 的需求主要是由 CPython 的内存管理算法导致的。
JavaScript 没有 GIL,但它也是单线程的,所以它根本不需要。JavaScript 的时间循环和 Promise/Callback 模式实现了异步编程,取代了并发编程。Python 也能通过 asyncio 的事件循环实现类似的模式。
这个原因过于简化了 CPython 的实际工作原理。当你在终端上写 python myscript.py 时,CPython 会启动一长串操作,包括读取、词法分析、语法分析、编译、解释以及执行。
这个过程的重点就是它会在编译阶段生成 .pyc 文件,字节码会写到 __pycache__/ 下的文件中(如果是 Python 3),或者写到与源代码同一个目录中(Python 2)。
因此绝大多数情况下(除非你写的代码只会运行一次),Python 是在解释字节码并在本地执行。
与 Java 和 C#.NET 比较一下:
Java 将源代码编译成“中间语言”,然后 Java 虚拟机读取字节码并即时编译成机器码。.NET CIL 也是一样的,.NET 的公共语言运行时(CLR)使用即时编译将字节码编译成机器码。
那么,既然它们都使用虚拟机,以及某种字节码,为什么 Python 在性能测试中比 Java 和 C# 慢那么多?第一个原因是,.NET 和 Java 是即时编译的(JIT)。
JIT 本身并不能让执行更快,因为它执行的是同样的字节码序列。但是 JIT 可以在运行时做出优化。好的 JIT 优化器能找到应用程序中执行最多的部分,称为“热点”。然后对那些字节码进行优化,将它们替换成效率更高的代码。
也就是说,如果你的应用程序会反复做某件事情,那么速度就会快很多。此外,别忘了 Java 和 C# 都是强类型语言,所以优化器可以对代码做更多的假设。
PyPy 也因为有 JIT,因此它比 CPython 要快很多。
哪个版本的 Python 的运行速度最快?
https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
JIT 也有缺点:首先就是启动速度。CPython 的启动速度已经比较慢了,而 PyPy 的启动速度要比 CPython 慢两到三倍。Java 虚拟机的启动速度也是出了名的慢。.
如果你有一个 Python 进程需要运行很长时间,而且代码里包含“热点”可以被优化,那么使用 JIT 就很不错。
但是,CPython 是个通用的实现。因此如果要用 Python 开发命令行程序,那么每次等待启动就特别久了。
CPython 试图满足大部分情况下的需求。有一个在 CPython 中实现 JIT(https://www.slideshare.net/AnthonyShaw5/pyjion-a-jit-extension-system-for-cpython)的项目,不过这个项目已经停止很久了。
如果你想要享受 JIT 的好处,并且要处理的任务适合 JIT,那就使用 PyPy。
“静态类型”语言要求必须在变量定义时指定其类型,例如 C、C++、Java、C# 和 Go 等。
而动态类型语言中尽管也有类型的概念,但变量的类型是动态的。
a = "foo"
a = 1
在这个例子中,Python 用相同的变量名和整型定义了第二个变量,同时释放了第一个 a 所引用的对象占用的内存。
静态类型语言的设计目的并不是折磨人,这样设计是因为 CPU 就是这样工作的。如果任何操作最终都要转化成简单的二进制操作,那就需要将对象和类型都转换成低级数据结构。
Python 帮你做了这一切,只不过你从来没有关心过,也不需要关心。
Python 的设计可以让你把一切都做成动态的。你可以在运行时替换对象的方法,可以在运行时给底层系统调用打补丁。几乎一切都有可能。
Python 慢的主要原因是因为它的动态型和多样性。它能用于解决各种问题,但多数问题都有优化得更好和更快的解决方案。
Python 语言特性:编译+解释、动态类型语言、动态语言、运行速度
标签:应用 了解 语言 方便 上下文 方式 去掉 types 静态
原文地址:https://www.cnblogs.com/qwera/p/14710386.html