标签:path round text ext line hone location cursor dump
scrapy安装配置不在本文 提及,
1.在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令
scrapy startproject mySpider
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
mySpider/spiders/__init__.py :爬虫主要处理逻辑
2. 今天通过爬虫调用 百度地图api来获取 全国学校的经纬度信息 并入库。
百度地图接口api :http://api.map.baidu.com/place/v2/search?query=小学、中学或者大学®ion=地市名字&output=json&ak=你的开发者ak&page_num=页码
1)打开mySpider目录下的items.py
Item 定义结构化数据字段,用来保存爬取到的数据,也是爬取数据后导出的字段,有点像Python中的dict字典,但是提供了一些额外的保护减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item。
items.py
1 import scrapy 2 3 4 class GetpointItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 name = scrapy.Field() #学校名称 8 lat = scrapy.Field() #纬度 9 lng = scrapy.Field() #经度11 city = scrapy.Field() #地市 12 area = scrapy.Field() #区县 13 address = scrapy.Field() #地址 14 types = scrapy.Field() #学校类型(小学,中学,大学)
2) 打开 mySpider/spiders目录里的 __init__.py写逻辑 ,直接上代码,有注释
1 import scrapy 2 import json 3 from urllib.parse import urlencode 4 from .. import items 5 class DmozSpider(scrapy.Spider): 6 name = "map" 7 allowed_domains = [] 8 #三层循环数组分别请求api,由于百度api返回的数据不是所有,所以必须传入页码,来爬取更多数据。 10 def start_requests(self): 11 cities = [‘北京‘,‘上海‘,‘深圳‘]14 types =[‘小学‘,‘中学‘,‘大学‘] 15 for city in cities: 16 for page in range(1, 16): 17 for type_one in types: 18 base_url = ‘http://api.map.baidu.com/place/v2/search?‘ 19 params = { 20 ‘query‘: type_one, 21 ‘region‘: city, 22 ‘output‘:‘json‘, 23 ‘ak‘: ‘你的ak‘, 25 ‘page_num‘: page 26 } 27 url = base_url + urlencode(params) 28 yield scrapy.Request(url, callback=self.parse,meta={"types":type_one}) 29 30 def parse(self, response): 31 res = json.loads(response.text) #请求回来数据需转成json 32 result= res.get(‘results‘) 33 types = response.meta["types"] #由于api返回来数据没有学校type的数据,这里需要自己接一下 传参时的type参数 34 #print(types) 35 if result: 36 for result_one in result: 37 item = items.GetpointItem() #调用item的GetpointItem类,导出item 38 item[‘name‘] = result_one.get(‘name‘) 39 item[‘lat‘] = result_one.get(‘location‘).get(‘lat‘) 40 item[‘lng‘] = result_one.get(‘location‘).get(‘lng‘)42 item[‘city‘] = result_one.get(‘city‘) 43 item[‘area‘] = result_one.get(‘area‘) 44 item[‘types‘] = types 45 item[‘address‘] = result_one.get(‘address‘) 46 yield item 47 else: 48 print(‘网络请求错误‘)
3)item导出来了,数据获取到了,然后 入库,打开pipelines.py ,代码如下:
from itemadapter import ItemAdapter import pymysql import json class DBPipeline(object): def __init__(self): # 连接MySQL数据库 self.connect=pymysql.connect(host=‘localhost‘,user=‘root‘,password=‘1q2w3e‘,db=‘mapspider‘,port=3306) self.cursor=self.connect.cursor() def process_item(self, item, spider): # 往数据库里面写入数据 try: self.cursor.execute("""select * from school where name = %s""", item[‘name‘]) ret = self.cursor.fetchone() if ret: print(item[‘name‘]+‘***********数据重复!***************‘) else: self.cursor.execute( """insert into school(name, lng, lat, type,city,county,address) value (%s, %s, %s, %s, %s, %s, %s)""", ( item[‘name‘], json.dumps(item[‘lng‘]), json.dumps(item[‘lat‘]), item[‘types‘], item[‘city‘], item[‘area‘], item[‘address‘] )) self.connect.commit() return item except Exception as eror: print(‘错误‘) # 关闭数据库 def close_spider(self,spider): self.cursor.close() self.connect.close()
重复数据的话,fecthOne直接排除 ,入库。。。。,
4)执行脚本 scray crawl map
scrapy crawl map
name 要写对哦

回车 ,开始 唰唰唰
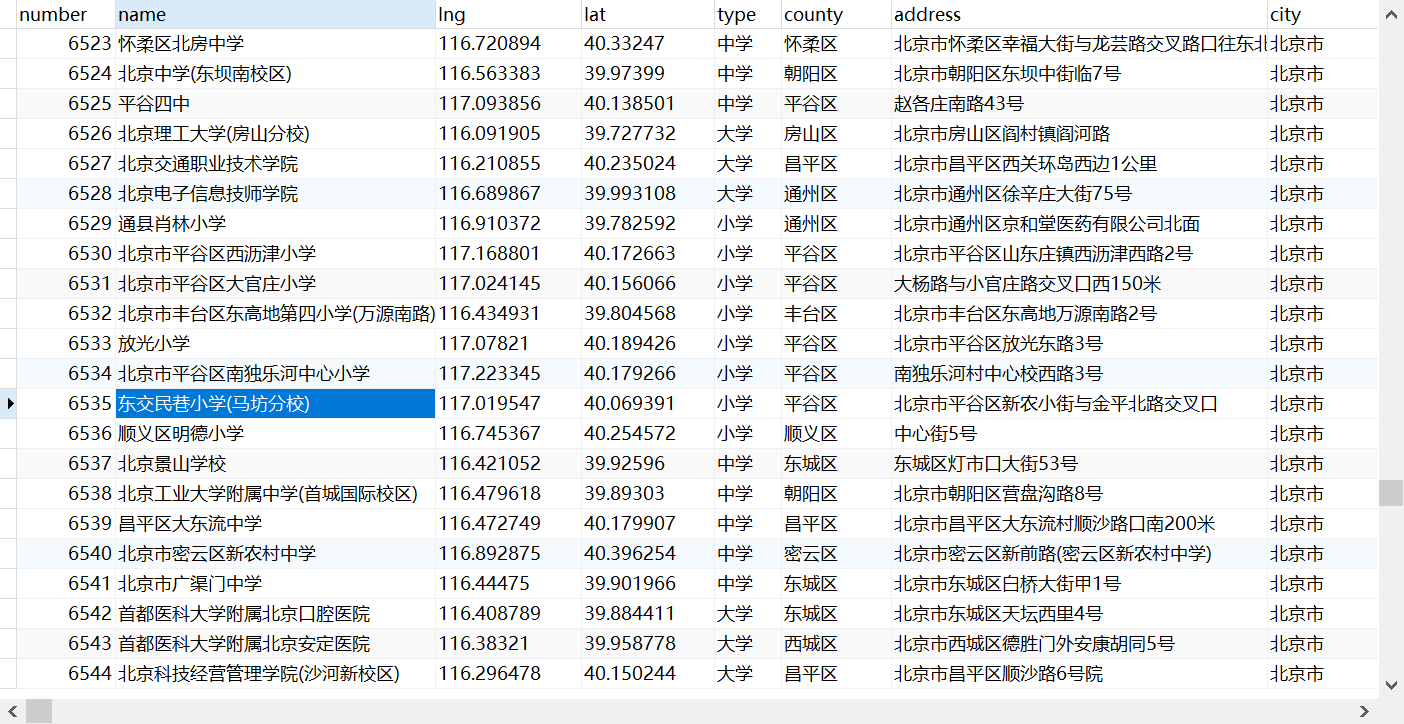
成果如下:
期间 ,百度地图 api 多次并发,不让访问了,多爬几次就好了,程序逻辑 晓得就好了。
接口api爬完了,下次爬一爬 页面xpath上的内容。
标签:path round text ext line hone location cursor dump
原文地址:https://www.cnblogs.com/realdanielwu/p/14722656.html