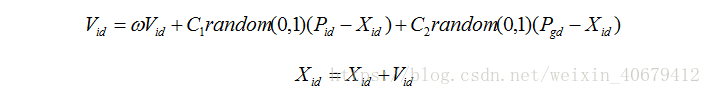标签:lpm cap 速度 cte 结构 群体智能 redo classes 改变
粒子群算法的发展过程。粒子群优化算法(Partical Swarm Optimization PSO),粒子群中的每一个粒子都代表一个问题的可能解,通过粒子个体的简单行为,群体内的信息交互实现问题求解的智能性。由于PSO操作简单、收敛速度快,因此在函数优化、 图像处理、大地测量等众多领域都得到了广泛的应用。 随着应用范围的扩大,PSO算法存在早熟收敛、维数灾难、易于陷入局部极值等问题需要解决,主要有以下几种发展方向。
(1)调整PSO的参数来平衡算法的全局探测和局部开采能力。如Shi和Eberhart对PSO算法的速度项引入了惯性权重,并依据迭代进程及粒子飞行情况对惯性权重进行线性(或非线性)的动态调整,以平衡搜索的全局性和收敛速度。2009年张玮等在对标准粒子群算法位置期望及方差进行稳定性分析的基础上,研究了加速因子对位置期望及方差的影响,得出了一组较好的加速因子取值。
(2)设计不同类型的拓扑结构,改变粒子学习模式,从而提高种群的多样性,Kennedy等人研究了不同的拓扑结构对SPSO性能的影响。针对SPSO存在易早熟收敛,寻优精度不高的缺点,于2003年提出了一种更为明晰的粒子群算法的形式:骨干粒子群算法(Bare Bones PSO,BBPSO)。
(3)将PSO和其他优化算法(或策略)相结合,形成混合PSO算法。如曾毅等将模式搜索算法嵌入到PSO算法中,实现了模式搜索算法的局部搜索能力与PSO算法的全局寻优能力的优势互补。
(4)采用小生境技术。小生境是模拟生态平衡的一种仿生技术,适用于多峰函数和多目标函数的优化问题。例如,在PSO算法中,通过构造小生境拓扑,将种群分成若干个子种群,动态地形成相对独立的搜索空间,实现对多个极值区域的同步搜索,从而可以避免算法在求解多峰函数优化问题时出现早熟收敛现象。 Parsopoulos提出一种基于“分而治之”思想的多种群PSO算法,其核心思想是将高维的目标函数分解成多个低维函数,然后每个低维的子函数由一个子粒子群进行优化,该算法对高维问题的求解提供了一个较好的思路。
不同的发展方向代表不同的应用领域,有的需要不断进行全局探测,有的需要提高寻优精度,有的需要全局搜索和局部搜索相互之间的平衡,还有的需要对高维问题进行求解。这些方向没有谁好谁坏的可比性,只有针对不同领域的不同问题求解时选择最合适的方法的区别。
粒子群算法( Particle Swarm Optimization, PSO)最早是由Eberhart和Kennedy于1995年提出,它的基本概念源于对鸟群觅食行为的研究。设想这样一个场景:一群鸟在随机搜寻食物,在这个区域里只有一块食物,所有的鸟都不知道食物在哪里,但是它们知道当前的位置离食物还有多远。最简单有效的策略?寻找鸟群中离食物最近的个体来进行搜素。PSO算法就从这种生物种群行为特性中得到启发并用于求解优化问题。
用一种粒子来模拟上述的鸟类个体,每个粒子可视为N维搜索空间中的一个搜索个体,粒子的当前位置即为对应优化问题的一个候选解,粒子的飞行过程即为该个体的搜索过程.粒子的飞行速度可根据粒子历史最优位置和种群历史最优位置进行动态调整.粒子仅具有两个属性:速度和位置,速度代表移动的快慢,位置代表移动的方向。每个粒子单独搜寻的最优解叫做个体极值,粒子群中最优的个体极值作为当前全局最优解。不断迭代,更新速度和位置。最终得到满足终止条件的最优解。
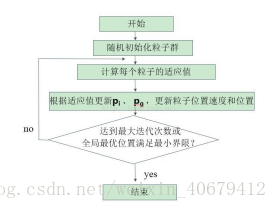
算法流程如下:
1、初始化
首先,我们设置最大迭代次数,目标函数的自变量个数,粒子的最大速度,位置信息为整个搜索空间,我们在速度区间和搜索空间上随机初始化速度和位置,设置粒子群规模为M,每个粒子随机初始化一个飞翔速度。
2、 个体极值与全局最优解
定义适应度函数,个体极值为每个粒子找到的最优解,从这些最优解找到一个全局值,叫做本次全局最优解。与历史全局最优比较,进行更新。
3、 更新速度和位置的公式
![]() ?
?
![]() ?
?
4、 终止条件
(1)达到设定迭代次数;(2)代数之间的差值满足最小界限
![]() ?
?
以上就是最基本的一个标准PSO算法流程。和其它群智能算法一样,PSO算法在优化过程中,种群的多样性和算法的收敛速度之间始终存在着矛盾.对标准PSO算法的改进,无论是参数的选取、小生境技术的采用或是其他技术与PSO的融合,其目的都是希望在加强算法局部搜索能力的同时,保持种群的多样性,防止算法在快速收敛的同时出现早熟收敛。
2 水电站调度模型
3 代码
%------主函数源程序-周调度(main.m) %------基本粒子群优化算法(Particle Swarm Optimization)----------- %------名称:基本粒子群优化算法(PSO) %------作用:求解优化问题(周调度) %------说明:全局性,并行性,高效的群体智能算法 ? %------初始格式化-------------------------------------------------- tic clear all; clc; format short; %% ------给定水电站初始化条件---------------------------------------------- %------------水电站1--------------------------------------- Vmax1=9015*10^4; %水库容量上限(m3) Vmin1=7000*10^4; %水库容量下限(m3) H1=640; %水库容量初始值水位(m) V1=(2.0554*H1^2-2413.5002*H1+709934.65)*10^4 ; %水库库容与水位的关系 h1=91; %初始水库水头(m) qr(:,1:7)=[20.4 25.2 22.1 19.3 16.4 23.3 28.6 ]; %水库来水流量(m3/s) qmax1=44; %水库引用流量上限(m3/s) qmin1=0; %水库引用流量下限(m3/s) A1=9.8*10^3; %水库出力系数 k1=0.65; %发电效率 t=8.64*10^4; %水库发电引用流量时间段(s) fengdian1=[10 15 11 12 16 17 18];%水库1每个时段风电发电量 %-----------水电站2-------------------------------------- Vmax2=2080*10^4; %水库容量上限(m3) Vmin2=1530*10^4; %水库容量下限(m3) H2=540; %水库容量初始值水位(m) V2=(2.6408*H2^2-2763.6392*H2+724014.90)*10^4; %水库库容与水位的关系 h2=57; %初始水库水头(m) qr(:,8:14)=[22.4 18.3 26.4 25.2 17.6 24.6 27.2]; %水库来水流量(m3/s) fengdian2=[13 12 14 11 19 13 16];%水库2每个时段风电发电量 qmax2=32; %水库引用流量上限(m3/s) qmin2=0; %水库引用流量下限(m3/s) A2=9.8*10^3; %水库出力系数 k2=0.6; %发电效率 %% 给定粒子群计算初始化条件 T=7; %周期 c1=0.5; %学习因子1 c2=0.6; %学习因子2 w1=0.9; %惯性权重 w2=0.4; MaxIter=1500; %最大迭代次数 Iter=0; vmax=2; %最大运动速度 vmin=0; %最小运动速度 N=30; %初始化群体个体数目 %------初始化种群的个体(可以在这里限定位置和速度的范围)------------ ? q=zeros(N,2*T); %位置随机初始化位置 v=rand(N,2*T); %速度随机初始化速度 ? ? %------适应度函数源程序(fitness.m)---------------------------- for i=1:N Fx1(i)=sum((k1*A1*q(i,1:7).*h1*t/(3.6*10^10))‘+fengdian1‘)‘; %水库1总发电量(万kWh) Fx2(i)=sum((k2*A2*q(i,8:14).*h2*t/(3.6*10^10))‘+fengdian2‘)‘; %水库2总发电量(万kWh) Fx(i)=Fx1(i)+Fx2(i); %水库总发电量(万kWh) end %------设置当前粒子的最好位置---------------------------------- ? ? %% -----------------最后给出计算结果------------------------------------ disp(‘****************************结果显示*******************************‘) Best ? disp(‘水库来水预测流量(米/秒):‘) QR1=Qr1(r,:) QR2=Qr2(r,:) ? disp(‘水库各时段初始水位(米):‘) HS1=Hs1(r,:) HS2=Hs2(r,:) ? disp(‘水库各时段平均库容大小(万立方米):‘) VJ1=Vj1(r,:)/(10^4) VJ2=Vj2(r,:)/(10^4) ? disp(‘水库各时段发电量(万kWh):‘) HJ1=Hj1(r,:) e1=k1*A1*Best(1,1:7).*(HJ1-539.3).*t/(3.6*10^10) %-----************************************ sum(e1) disp(‘水库各时段发电量(万kWh):‘) HJ2=Hj2(r,:) e2=k2*A2*Best(1,8:14).*(HJ2-478.28).*t/(3.6*10^10) sum(e2) disp(‘水库平均发电量功率(万kW):‘) e1/24 e2/24 ? disp(‘水库总发电量(万kWh):‘) E ? disp(‘水库各时段弃水量(万立方米):‘) Quit1=((quit1(r,:)‘)/(10^4))‘ Quit2=((quit1(r,:)‘)/(10^4))‘ ? disp(‘水库总弃水量(万立方米):‘) ZQuit1=sum(Quit1) ZQuit2=sum(Quit1) ? %------------------------仿真结果------------------------------------ figure(1) x=1:7; subplot(2,3,1),bar(x,Best(:,1:7),‘g‘),title(‘引用流量与时段的关系‘ ),xlabel(‘时段T‘),ylabel(‘发电水量(米/秒)‘),grid subplot(2,3,2),bar(x,QR1,‘b‘),title(‘来水预测流量与时段的关系‘),xlabel(‘时段T‘),ylabel(‘来水量(米/秒)‘),grid subplot(2,3,3),bar(x,VJ1,‘c‘),title(‘平均库容与时段的关系‘),xlabel(‘时段T‘),ylabel(‘库容(万立方米)‘),grid x=1:8; subplot(2,3,4),plot(x,HS1,‘b‘), hold on ,plot(x,HS1,‘*r‘), hold off ,title(‘各时段初始水位与时段的关系‘),xlabel(‘时段T‘),ylabel(‘水位(米)‘),grid, x=1:7; subplot(2,3,5),bar(x,e1,‘m‘),title(‘发电量与时段的关系‘),xlabel(‘时段T‘),ylabel(‘发电量(万kWh)‘),grid subplot(2,3,6),bar(x,Quit1,‘k‘),title(‘弃水量与时段的关系‘),xlabel(‘时段T‘),ylabel(‘弃水量(万立方米)‘),grid figure(2) x=1:7; subplot(2,3,1),bar(x,Best(:,8:14),‘g‘),title(‘引用流量与时段的关系‘ ),xlabel(‘时段T‘),ylabel(‘发电水量(米/秒)‘),grid subplot(2,3,2),bar(x,QR2,‘b‘),title(‘来水预测流量与时段的关系‘),xlabel(‘时段T‘),ylabel(‘来水量(米/秒)‘),grid subplot(2,3,3),bar(x,VJ2,‘c‘),title(‘平均库容与时段的关系‘),xlabel(‘时段T‘),ylabel(‘库容(万立方米)‘),grid x=1:8; subplot(2,3,4),plot(x,HS2,‘b‘), hold on ,plot(x,HS2,‘*r‘), hold off ,title(‘各时段初始水位与时段的关系‘),xlabel(‘时段T‘),ylabel(‘水位(米)‘),grid, x=1:7; subplot(2,3,5),bar(x,e2,‘m‘),title(‘发电量与时段的关系‘),xlabel(‘时段T‘),ylabel(‘发电量(万kWh)‘),grid subplot(2,3,6),bar(x,Quit2,‘k‘),title(‘弃水量与时段的关系‘),xlabel(‘时段T‘),ylabel(‘弃水量(万立方米)‘),grid ? disp(‘****************************结果显示*******************************‘) %----------------算法结束---DreamSun GL & HF------------------------------- figure(3) plot(y) xlabel(‘迭代次数‘) ylabel(‘水电和风电发电总量适应度值‘) % axis([0 1500 200 300]) toc
完整代码添加QQ1575304183
标签:lpm cap 速度 cte 结构 群体智能 redo classes 改变
原文地址:https://www.cnblogs.com/ttmatlab/p/14749123.html