标签:amp lte info 大量 name 创建 高级 实现 商业
关系数据库已经流行多年,能较好的满足各类商业公司的业务数据管理需求,但关系数据库在大数据时代已经不能满足各种新增的用户需求。用户需要从不同数据源执行各种操作(包括结构化和非结构化数据),也需要执行高级分析(在实际大数据应用中,经常需要融合关系查询和复杂分析算法)。
Spark SQL 的出现,填补了这个鸿沟。首先,Spark SQL 可以对内部和外部各种数据源执行各种关系操作;其次,可以支持大量的数据源和数据分析算法,有效地满足各种复杂的应用需求。
Pandas 中 DataFrame 是可变的,而 Spark 中 RDDs 是不可变的,因此 DataFrame 也是不可变的。
spark.read.text()
file = ‘file:///usr/local/spark/examples/src/main/resources/people.txt‘
df = spark.read.text(file)

spark.read.json()
file = ‘file:///usr/local/spark/examples/src/main/resources/people.json‘
df = spark.read.json(file)

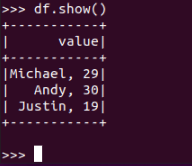
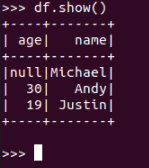
df.show() 默认打印前20条数据,df.show(n)
text:
json:
df.printSchema()
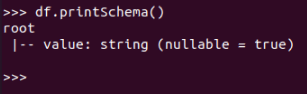
text:
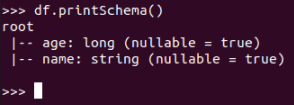
json:
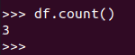
df.count()
df.head(3) #list 类型,list 中每个元素是 Row 类
text:

json:

df.collect() # list 类型,list 中每个元素是Row类
text:

json:

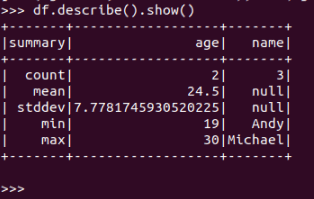
df.describe().show()
text:
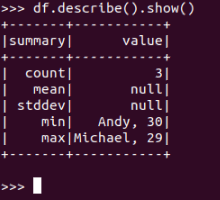
json:
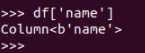
df[‘name‘]
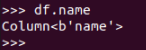
df.name
df.select()
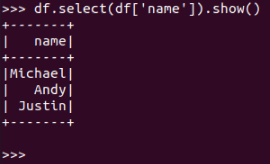
df.select(df[‘name‘]).show()
df.filter()
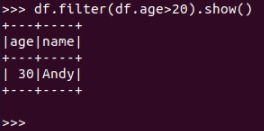
df.filter(df.age>20).show()
df.groupBy()
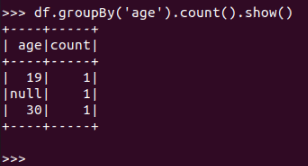
df.groupBy(‘age‘).count().show()
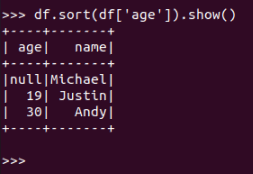
df.sort()
df.sort(df[‘age‘]).show()
标签:amp lte info 大量 name 创建 高级 实现 商业
原文地址:https://www.cnblogs.com/86xiang/p/14753074.html