标签:加载 版本 大学 uav 出现 获得 already ide 更新
在推荐服务中,虽然允许少量请求因计算超时等原因返回默认列表。但从运营指标来说,越高的“完算率”意味着越完整的算法效果呈现,也意味着越高的商业收益。(完算率类比视频的完播率,成功完成整个推荐线上流程计算的请求次数/总请求次数)
为了能够尽可能快地完成计算,多级缓存方案已经成为推荐线上服务的标配。其中本地缓存显得尤为重要,而 Caffeine Cache 就是近几年脱颖而出的高性能本地缓存库。Caffeine Cache 已经在 Spring Boot 2.0 中取代了 Google Guava 成为默认缓存框架,足见其成熟和可靠。
关于 Caffeine 的介绍文章有很多,不再累述,可阅读文末的参考资料了解 Caffeine 的简述、性能基准测试结果、基本 API 用法和 Window-TinyLFU 缓存算法原理等。虽然接触 Caffeine 的时间不长,但其简洁的 API 和如丝般顺滑的异步加载能力简直不要太好用。而本菜鸟在使用的过程中也踩了一些坑,使用不当甚至缓存也能卡得和磁盘 IO 一样慢。
经过一番学习尝试,总算了解到 Caffeine Cache 如丝般顺滑的奥秘,总结下来分享一下。
使用 Caffeine Cache,除了 Spring 中常见的 @EnableCache、@Cacheable 等注解外,直接使用 Caffeine.newBuilder().build() 方法创建 LoadingCache 也是推荐服务常用的方式。
我们先来看看 Caffeine#builder 都有哪些配置套路:
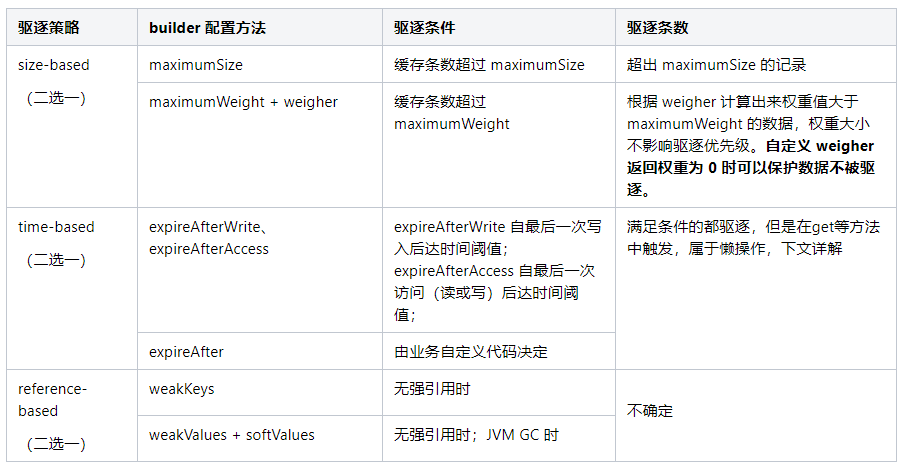
当然可以,光脚的不怕穿鞋的,上线后别走……
虽然 expireAfterWrite 和 expireAfterAccess 同时配置不报错,但 access 包含了 write,所以选一个就好了亲。
只要配置上都会使用 == 来比较对象相等,而不是 equals;还有一个非常重要的配置,也是决定缓存如丝般顺滑的秘诀:刷新策略 refreshAfterWrite。该配置使得 Caffeine 可以在数据加载后超过给定时间时刷新数据。下文详解。
机智如我在 Builder 上也能踩坑
和 lombok 的 builder 不同,Caffeine#builder 的策略调用两次将会导致运行时异常!这是因为 Caffeine 构建时每个策略都保存了已设置的标记位,所以重复设置并不是覆盖而是直接抛异常:
public Caffeine<K, V> maximumWeight(@NonNegative long maximumWeight) {
requireState(this.maximumWeight == UNSET_INT,
"maximum weight was already set to %s", this.maximumWeight);
requireState(this.maximumSize == UNSET_INT,
"maximum size was already set to %s", this.maximumSize);
this.maximumWeight = maximumWeight;
requireArgument(maximumWeight >= 0, "maximum weight must not be negative");
return this;
}
比如上述代码,maximumWeight() 调用两次的话就会抛出异常并提示 maximum weight was already set to xxx。
首先在实现类 LocalLoadingCache<K, V> 中可以看到;
default @Nullable V get(K key) {
return cache().computeIfAbsent(key, mappingFunction());
}
但突然发现这个 get 方法没有实现类!Why?我们跟踪 cache() 方法就可以发现端倪:
public BoundedLocalCache<K, V> cache() {
return cache;
}
public UnboundedLocalCache<K, V> cache() {
return cache;
}
根据调用 Caffeine.newBuilder().build() 的过程,决定了具体生成的是 BoundedLocalCache 还是 UnboundedLocalCache;
判定 BoundedLocalCache 的条件如下:
public <K1 extends K, V1 extends V> LoadingCache<K1, V1> build(
@NonNull CacheLoader<? super K1, V1> loader) {
requireWeightWithWeigher();
@SuppressWarnings("unchecked")
Caffeine<K1, V1> self = (Caffeine<K1, V1>) this;
return isBounded() || refreshes()
? new BoundedLocalCache.BoundedLocalLoadingCache<>(self, loader)
: new UnboundedLocalCache.UnboundedLocalLoadingCache<>(self, loader);
}
其中的 isBounded()、refreshes() 方法分别如下:
boolean isBounded() {
return (maximumSize != UNSET_INT)
|| (maximumWeight != UNSET_INT)
|| (expireAfterAccessNanos != UNSET_INT)
|| (expireAfterWriteNanos != UNSET_INT)
|| (expiry != null)
|| (keyStrength != null)
|| (valueStrength != null);
}
boolean refreshes() {
// 调用了 refreshAfter 就会返回 false
return refreshNanos != UNSET_INT;
}
可以看到一般情况下常规的配置都是 BoundedLocalCache。所以我们以它为例继续看 BoundedLocalCache#computeIfAbsent 方法吧:
public @Nullable V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction,
boolean recordStats, boolean recordLoad) {
// 常用的 LoadingCache#get 方法 recordStats、recordLoad 都为 true
// mappingFunction 即 builder 中传入的 CacheLoader 实例包装
requireNonNull(key);
requireNonNull(mappingFunction);
// 默认的 ticker read 返回的是 System.nanoTime();
// 关于其他的 ticker 见文末参考文献,可以让使用者自定义超时的计时方式
long now = expirationTicker().read();
// data 是 ConcurrentHashMap<Object, Node<K, V>>
// key 根据代码目前都是 LookupKeyReference 对象
// 可以发现 LookupKeyReference 保存的是 System.identityHashCode(key) 结果
// 关于 identityHashCode 和 hashCode 的区别可阅读文末参考资料
Node<K, V> node = data.get(nodeFactory.newLookupKey(key));
if (node != null) {
V value = node.getValue();
if ((value != null) && !hasExpired(node, now)) {
// isComputingAsync 中将会判断当前是否为异步类的缓存实例
// 是的话再判断 node.getValue 是否完成。BoundedLocaCache 总是返回 false
if (!isComputingAsync(node)) {
// 此处在 BoundedLocaCache 中也是直接 return 不会执行
tryExpireAfterRead(node, key, value, expiry(), now);
setAccessTime(node, now);
}
// 异步驱逐任务提交、异步刷新操作
// CacheLoader#asyncReload 就在其中的 refreshIfNeeded 方法被调用
afterRead(node, now, recordStats);
return value;
}
}
if (recordStats) {
// 记录缓存的加载成功、失败等统计信息
mappingFunction = statsAware(mappingFunction, recordLoad);
}
// 这里2.8.0版本不同实现类生成的都是 WeakKeyReference
Object keyRef = nodeFactory.newReferenceKey(key, keyReferenceQueue());
// 本地缓存没有,使用加载函数读取到缓存
return doComputeIfAbsent(key, keyRef, mappingFunction,
new long[] { now }, recordStats);
}
上文中 hasExpired 判断数据是否过期,看代码就很明白了:是通过 builder 的配置 + 时间计算来判断的。
boolean hasExpired(Node<K, V> node, long now) {
return
(expiresAfterAccess() &&
(now - node.getAccessTime() >= expiresAfterAccessNanos()))
| (expiresAfterWrite() &&
(now - node.getWriteTime() >= expiresAfterWriteNanos()))
| (expiresVariable() &&
(now - node.getVariableTime() >= 0));
}
继续看代码,doComputeIfAbsent 方法主要内容如下:
@Nullable V doComputeIfAbsent(K key, Object keyRef,
Function<? super K, ? extends V> mappingFunction,
long[] now, boolean recordStats) {
@SuppressWarnings("unchecked")
V[] oldValue = (V[]) new Object[1];
@SuppressWarnings("unchecked")
V[] newValue = (V[]) new Object[1];
@SuppressWarnings("unchecked")
K[] nodeKey = (K[]) new Object[1];
@SuppressWarnings({"unchecked", "rawtypes"})
Node<K, V>[] removed = new Node[1];
int[] weight = new int[2]; // old, new
RemovalCause[] cause = new RemovalCause[1];
// 对 data 这个 ConcurrentHashMap 调用 compute 方法,计算 key 对应的值
// compute 方法的执行是原子的,并且会对 key 加锁
// JDK 注释说明 compute 应该短而快并且不要在其中更新其他的 key-value
Node<K, V> node = data.compute(keyRef, (k, n) -> {
if (n == null) {
// 没有值的时候调用 builder 传入的 CacheLoader#load 方法
// mappingFunction 是在 LocalLoadingCache#newMappingFunction 中创建的
newValue[0] = mappingFunction.apply(key);
if (newValue[0] == null) {
return null;
}
now[0] = expirationTicker().read();
// builder 没有指定 weigher 时,这里默认为 SingletonWeigher,总是返回 1
weight[1] = weigher.weigh(key, newValue[0]);
n = nodeFactory.newNode(key, keyReferenceQueue(),
newValue[0], valueReferenceQueue(), weight[1], now[0]);
setVariableTime(n, expireAfterCreate(key, newValue[0], expiry(), now[0]));
return n;
}
// 有值的时候对 node 实例加同步块
synchronized (n) {
nodeKey[0] = n.getKey();
weight[0] = n.getWeight();
oldValue[0] = n.getValue();
// 设置驱逐原因,如果数据有效直接返回
if ((nodeKey[0] == null) || (oldValue[0] == null)) {
cause[0] = RemovalCause.COLLECTED;
} else if (hasExpired(n, now[0])) {
cause[0] = RemovalCause.EXPIRED;
} else {
return n;
}
// 默认的配置 writer 是 CacheWriter.disabledWriter(),无操作;
// 自己定义的 CacheWriter 一般用于驱逐数据时得到回调进行外部数据源操作
// 详情可以参考文末的资料
writer.delete(nodeKey[0], oldValue[0], cause[0]);
newValue[0] = mappingFunction.apply(key);
if (newValue[0] == null) {
removed[0] = n;
n.retire();
return null;
}
weight[1] = weigher.weigh(key, newValue[0]);
n.setValue(newValue[0], valueReferenceQueue());
n.setWeight(weight[1]);
now[0] = expirationTicker().read();
setVariableTime(n, expireAfterCreate(key, newValue[0], expiry(), now[0]));
setAccessTime(n, now[0]);
setWriteTime(n, now[0]);
return n;
}
});
// 剩下的代码主要是调用 afterWrite、notifyRemoval 等方法
// 进行后置操作,后置操作中将会再次尝试缓存驱逐
// ...
return newValue[0];
}
看完上面的代码,遇到这些问题也就心里有数了。
显式调用 invalid 方法时;弱引用、软引用可回收时;get 方法老值存在且已完成异步加载后调用 afterRead。
get 方法老值不存在,调用 doComputeIfAbsent 加载完数据后调用 afterWrite。
首先 CacheLoader#load 方法是必须提供的,缓存调用时将是同步操作(回顾上文 data.compute 方法),会阻塞当前线程。
而 CacheLoader#asyncReload 需要配合builder#refreshAfterWrite 使用这样将在computeIfAbsent->afterRead->refreshIfNeeded 中调用,并异步更新到 data 对象上;并且,load 方法没有传入oldValue,而 asyncReload 方法提供了oldValue,这意味着如果触发 load 操作时,缓存是不能保证 oldValue 是否存在的(可能是首次,也可能是已失效)。
CacheLoader#load 耗时长,将会导致缓存运行过程中查询数据时阻塞等待加载,当多个线程同时查询同一个 key 时,业务请求可能阻塞,甚至超时失败;
CacheLoader#asyncReload 耗时长,在时间周期满足的情况下,即使耗时长,对业务的影响也较小
首要前提是外部数据查询能保证单次查询的性能(一次查询天长地久那加本地缓存也于事无补);然后,我们在构建 LoadingCache 时,配置 refreshAfterWrite 并在 CacheLoader 实例上定义 asyncReload 方法;
灵魂追问:只有以上两步就够了吗?
机智的我突然觉得事情并不简单。还有一个时间设置的问题,我们来看看:
如果 expireAfterWrite 周期 < refreshAfterWrite 周期会如何?此时查询失效数据时总是会调用 load 方法,refreshAfterWrite 根本没用!
如果 CacheLoader#asyncReload 有额外操作,导致它自身实际执行查询耗时超过 expireAfterWrite 又会如何?还是 CacheLoader#load 生效,refreshAfterWrite 还是没用!
所以丝滑的正确打开方式,是 refreshAfterWrite 周期明显小于 expireAfterWrite 周期,并且 CacheLoader#asyncReload 本身也有较好的性能,才能如丝般顺滑地加载数据。此时就会发现业务不断进行 get 操作,根本感知不到数据加载时的卡顿!
computeIfAbsent 和 doComputeIfAbsent 方法可以看出如果加载结果是 null,那么每次从缓存查询,都会触发 mappingFunction.apply,进一步调用 CacheLoader#load。从而流量会直接打到后端数据库,造成缓存穿透。
防止的方法也比较简单,在业务可接受的情况下,如果未能查询到结果,则返回一个非 null 的“假对象”到本地缓存中。
灵魂追问:如果查不到,new 一个对象返回行不行?
key 范围不大时可以,builder 设置了 size-based 驱逐策略时可以,但都存在消耗较多内存的风险,可以定义一个默认的 PLACE_HOLDER 静态对象作为引用。
灵魂追问:都用同一个假对象引用真的大丈夫(没问题)?
这么大的坑本菜鸟怎么能错过!缓存中存的是对象引用,如果业务 get 后修改了对象的内容,那么其他线程再次获取到这个对象时,将会得到修改后的值!鬼知道那个深夜定位出这个问题的我有多兴奋(苍蝇搓手)。
当时缓存中保存的是 List<Item>,而不同线程中对这些 item 的 score 进行了不同的 set 操作,导致同一个 item 排序后的分数和顺序变幻莫测。本菜鸟一度以为是推荐之神降临,冥冥中加持 CTR 所以把 score 变来变去。
灵魂追问:那怎么解决缓存被意外修改的问题呢?怎么 copy 一个对象呢?
So easy,就在 get 的时候 copy 一下对象就好了。
灵魂追问4:怎么 copy 一个对象?……停!咱们以后有机会再来说说这个浅拷贝和深拷贝,以及常见的拷贝工具吧,聚焦聚焦……
根据 CacheLoader#load和 CacheLoader#asyncReload 的参数区别,我们可以发现:
应该在 asyncReload 中来处理,如果查询数据库异常,则可以返回 oldValue 来继续使用之前的缓存;否则只能通过 load 方法中返回预留空对象来解决。使用哪一种方法需要根据具体的业务场景来决定。
【踩坑】返回 null 将导致 Caffeine 认为该值不需要缓存,下次查询还会继续调用 load 方法,缓存并没生效。
根据代码可以知道,已经进入 doComputeIfAbsent 的线程将阻塞在 data.compute 方法上;
比如短时间内有 N 个线程同时 get 相同的 key 并且 key 不存在,则这 N 个线程最终都会反复执行 compute 方法。但只要 data 中该 key 的值更新成功,其他进入 computeIfAbsent 的线程都可直接获得结果返回,不会出现阻塞等待加载;
所以,如果一开始就有大量请求进入 doComputeIfAbsent 阻塞等待数据,就会造成短时间请求挂起、超时的问题。由此在大流量场景下升级服务时,需要考虑在接入流量前对缓存进行预热(我查我自己,嗯),防止瞬时请求太多导致大量请求挂起或超时。
灵魂追问:如果一次 load 耗时 100ms,一开始有 10 个线程冷启动,最终等待时间会是 1s 左右吗?
其实……要看情况,回顾一下 data.compute 里面的代码:
if (n == null) {
// 这部分代码其他后续线程进入后已经有值,不再执行
}
synchronized (n) {
// ...
if ((nodeKey[0] == null) || (oldValue[0] == null)) {
cause[0] = RemovalCause.COLLECTED;
} else if (hasExpired(n, now[0])) {
cause[0] = RemovalCause.EXPIRED;
} else {
// 未失效时在这里返回,不会触发 load 函数
return n;
}
// ...
}
所以,如果 load 结果不是 null,那么只第一个线程花了 100ms,后续线程会尽快返回,最终时长应该只比 100ms 多一点。但如果 load 结果返回 null(缓存穿透),相当于没有查到数据,于是后续线程还会再次执行 load,最终时间就是 1s 左右。
以上就是本菜鸟目前总结的内容,如有疏漏欢迎指出。在学习源码的过程中,Caffeine Cache 还使用了其他编码小技巧,咱们下次有空接着聊。
1.Caffeine使用及原理
2.Caffeine Cache-高性能Java本地缓存组件
3.Eviction和Ticker相关介绍
4.Efficiency
5.CacheWriter
6.System.identityHashCode(obj)与obj.hashcode
作者:vivo 互联网服务器团队-Li Haoxuan
标签:加载 版本 大学 uav 出现 获得 already ide 更新
原文地址:https://www.cnblogs.com/plus666/p/14756022.html