标签:count() tco 下标 字段名 page div src try nic
查询的方法还挺多的
查询所有
这两个一样
db.getCollection(‘userInfo‘).find({}) db.userInfo.find()
distinct
db.userInfo.distinct("name")
返回去重复后的所有name字段的值
按条件查询
db.userInfo.find({"name":"李四"})
查询name是李四的文档
比较查询
db.userInfo.find({"age":{"$lt":"20"}})
查询年纪小于20的集合
$lt 是 <; $ne 是 !=;$gt是>;$gte是>=;$lte是<=。
这些没必要记,用的时候再查就好了。
逻辑运算
and,or,not
db.userInfo.find({ $and:[ {"age":{"$lt":"25","$gt":"18"}}, {"name":"李四"} ] })
查询age小于25大于18,name是李四的数据
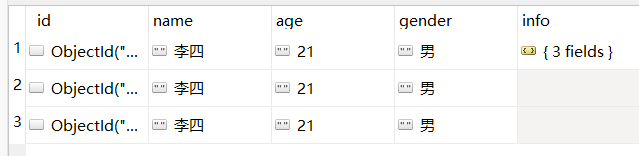
db.userInfo.find({ $or:[ {"age":{"$lt":"25","$gt":"18"}}, {"name":"张三"} ] })
查询age在18到25之间,或者name是张三的数据
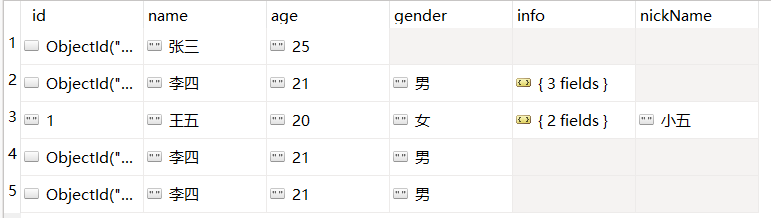
db.userInfo.find({ "age":{$not:{$gt:"20"}} })
查询不大于20的数据

要注意not只能和其他操作符一起用,因为它实际是影响其他操作符,而不是影响字段和文档
投影
就是查询部分字段
db.userInfo.find({ "age":{$not:{$gt:"25"}} }, { "name":1, "_id":0, "age":1, "nickName":1, "info":1 } )
就这样,想要查哪个字段,就 字段名:1 就行,不想查的字段给0。
查询数组
先插入一条带数组字段的文档
user1 = { "name":"读书人", "age":"19", "gender":"男", "hobbies":["read","write","sport"] } db.userInfo.insert(user1)
查询hobbies中有read的
db.userInfo.find({"hobbies":"read"})
查询既有read又有write的
db.userInfo.find({"hobbies":{$all:["write","read"]}})
查询第2个是wirte的,也就是数组下标是1
db.userInfo.find({"hobbies.1":"write"})
查询前2个hobbies
db.userInfo.find({}, { "hobbies":{"$slice":[0,2]} } )
注意这里的[ ] 是左闭右开的,所以必须写0,2
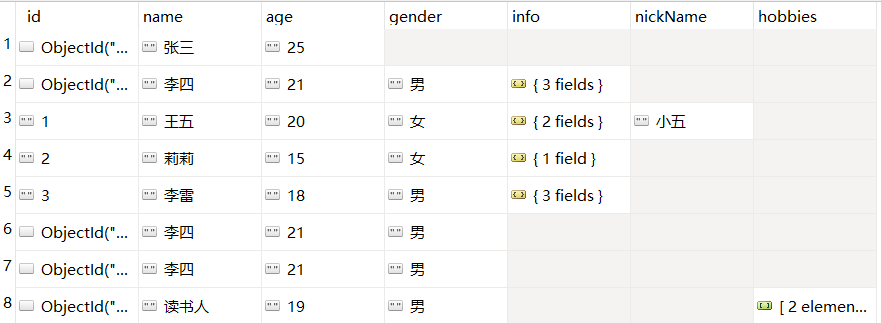
看结果也知道,这个读书人有的hobbies字段有3个,这里只查了2个。
查询最后1个hobbies
db.userInfo.find({}, { "hobbies":{"$slice":-1} } )
想查几个就写负几。
子文档
查询country是中国的
db.userInfo.find({ "info.country":"中国" })
排序
db.userInfo.find().sort({"age":1})
按age升序,-1是降序
分页
db.userInfo.find().sort({"age":1}).limit(2).skip(2)
跟mysql的一样,limit是pagesize取多少条,skip是根据pageindex和pagesize算出的要跳过的条数,像这个就是跳过2条取2条,也就是一页显示2条数据,取第2页。
统计
db.userInfo.count({"name":"李四"})
统计name是李四的数量,也可以用大于,小于这些操作符
db.userInfo.count({"age":{"$gt":"18"}})
统计age大于18的数量
也可以用这种形式,等价的。
db.userInfo.find({"age":{"$gt":"18"}}).count()
标签:count() tco 下标 字段名 page div src try nic
原文地址:https://www.cnblogs.com/luyShare/p/14758133.html