标签:个数 区域 开头 基本 因此 多个 技术 upper 插入
正则表达式是一种符号表示法,被用来识别文本模式。
grep
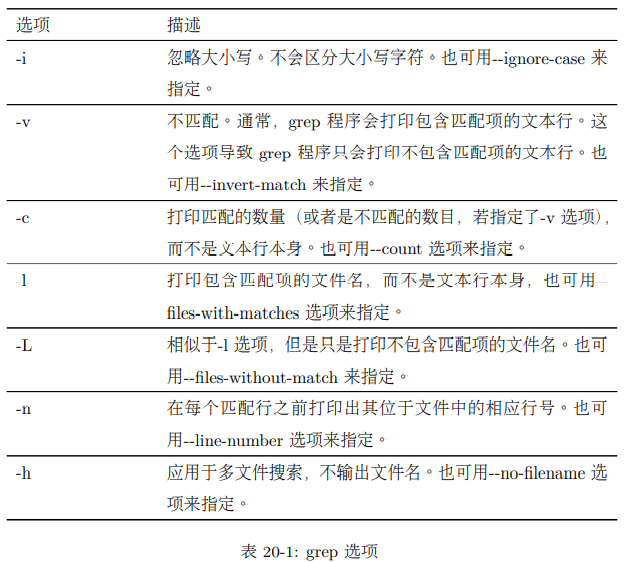
元字符和原义字符 (Metacharacters And Literals)
正则表达式元字符由以下字符组成:
任何字符
我们将要查看的第一个元字符是圆点字符,其被用来匹配任意字符。如果我们在正则表达式中包含它,它将会匹配在此位置的任意一个字符。
锚点
在正则表达式中,插入符号和美元符号被看作是锚点。这意味着正则表达式只有在文本行的开头或末尾被找到时,才算发生一次匹配。

中括号表达式和字符类
通过中括号表达式,我们能够指定一个待匹配字符集合(包含在不加中括号的情况下会被解释为元字符的字符)。

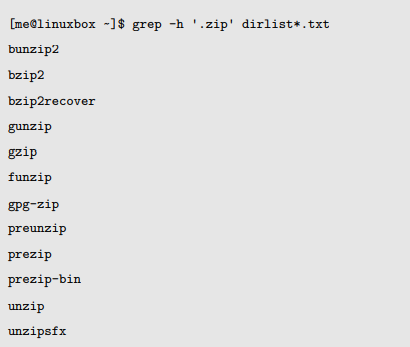
我们匹配包含字符串“bzip”或者“gzip”的任意行。
且元字符被放置到中括号里面后会失去了它们的特殊含义。第一个元字符是插入字符(?),其被用来表示否定;第二个是连字符字符(-),其被用来表示一个字符范围。
否定
如果在中括号表示式中的第一个字符是一个插入字符(?),则剩余的字符被看作是不会在给定的字符位置出现的字符集合。
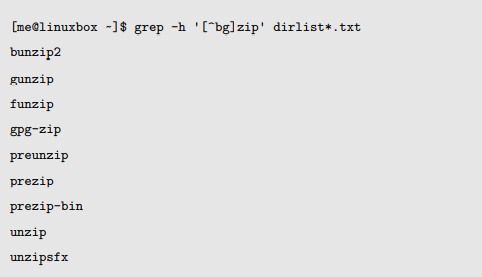
通过激活否定操作,我们得到一个文件列表,它们的文件名都包含字符串“zip”,并且“zip”的前一个字符是除了“b”和“g”之外的任意字符。
插入字符如果是中括号表达式中的第一个字符的时候,才会唤醒否定功能;否则,它会失去它的特殊含义,变成字符集中的一个普通字符。
传统的字符区域
如果我们想要构建一个正则表达式,它可以在我们的列表中找到每个以大写字母开头的文件,我们可以这样做:
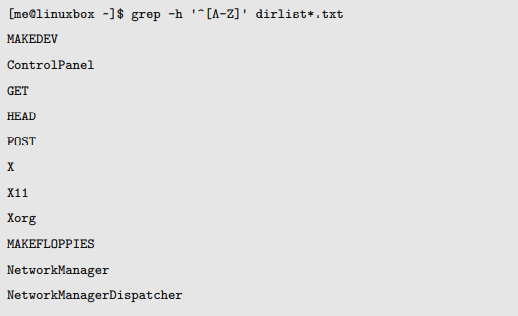
POSIX 字符集
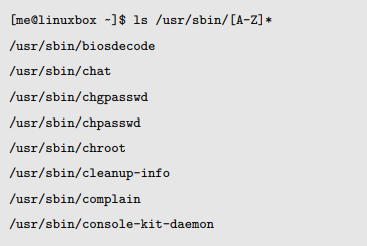
ASCII 的系统的排序规则

正常的字典顺序

为了支持这种功能,posix 标准引入了 “locale” 概念,它能针对不同地区选择合适的字符集。
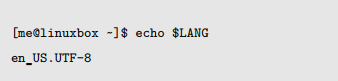
通过这个设置,POSIX 相容的应用程序将会使用字典排列顺序而不是 ASCII 顺序。这就解释了上述命令的行为。当 [A-Z] 字符区域按照字典顺序解释的时候,包含除了小写字母“a”之外的所有字母,因此得到这样的结果。
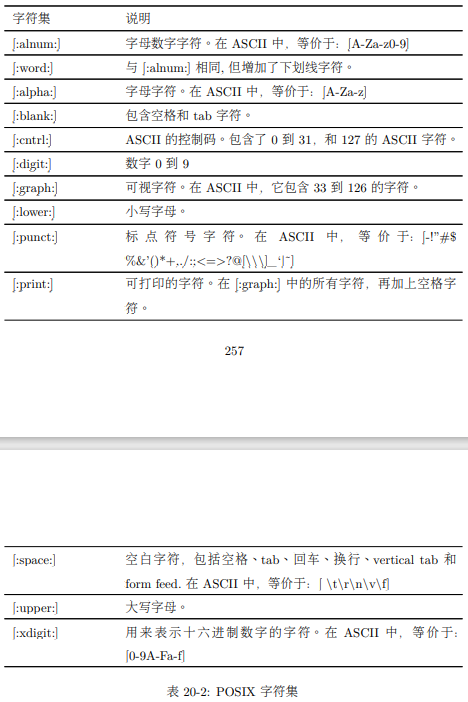
交替

这里我们看到正则表达式’AAA|BBB’,这意味着“匹配字符串 AAA 或者是字符串 BBB”。注意因为这是一个扩展的特性,我们给 grep 命令添加了-E选项,并且我们把这个正则表达式用单引号引起来,为的是阻止 shell 把竖杠线元字符解释为一个 pipe 操作符。
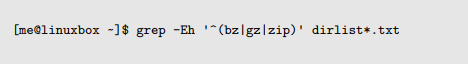
这个表达式将会在我们的列表中匹配以“bz”,或“gz”,或“zip”开头的文件名。
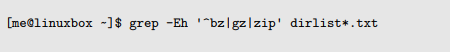
会变成匹配任意以“bz”开头,或包含“gz”,或包含“zip”的文件名。
限定符
? - 匹配零个或一个元素
说我们想要查看一个电话号码的真实性,如果它匹配下面两种格式的任意一种,我们就认为这个电话号码是真实的:
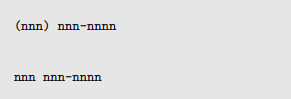
这里的“n”是一个数字。我们可以构建一个像这样的正则表达式:

在这个表达式中,我们在圆括号之后加上一个问号,来表示它们将被匹配零次或一次。再一次,因为通常圆括号都是元字符(在 ERE 中),所以我们在圆括号之前加上了反斜杠,使它们成为文本字符。
* - 匹配零个或多个元素

这个表达式由三个元素组成:一个包含 [:upper:] 字符集的中括号表达式,一个包含 [:upper:]和 [:lower:] 两个字符集以及一个空格的中括号表达式,和一个被反斜杠字符转义过的圆点。第二个元素末尾带有一个 * 元字符,所以在开头的大写字母之后,可能会跟随着任意数目的大写和小写字母和空格,并且匹配。
+ - 匹配一个或多个元素
这个正则表达式只匹配那些由一个或多个字母字符组构成的文本行,字母字符之间由单个空格分开:

我们看到这个正则表达式不匹配“a b 9”这一行,因为它包含了一个非字母的字符;它也不匹配“abc d”,因为在字符“c”和“d”之间不止一个空格。
{ } - 匹配特定个数的元素
{ 和 } 元字符都被用来表达要求匹配的最小和最大数目。它们可以通过四种方法来指定:

回到之前处理电话号码的例子,我们能够使用这种指定重复次数的方法来简化我们最初的正则表达式:


用 find 查找丑陋的文件名
这样一种扫描会发现包含空格和其它潜在不规范字符的路径名:

由于要精确地匹配整个路径名,所以我们在表达式的两端使用了.*,来匹配零个或多个字符。在表达式中间,我们使用了否定的中括号表达式,其包含了我们一系列可接受的路径名字符。
用 locate 查找文件
这个 locate 程序支持基本的(--regexp 选项)和扩展的(--regex 选项)正则表达式。通过 locate命令,我们能够执行许多与先前操作 dirlist 文件时相同的操作:
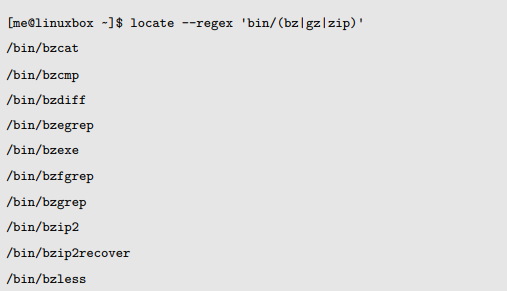
通过使用 alternation,我们搜索包含 bin/bz,bin/gz,或/bin/zip 字符串的路径名。
在 less 和 vim 中查找文本
less 和 vim 两者享有相同的文本查找方法。按下/按键,然后输入正则表达式,来执行搜索任务。如果我们使用 less 程序来浏览我们的 phonelist.txt 文件:

然后查找我们有效的表达式:

less 将会高亮匹配到的字符串,这样就很容易看到无效的电话号码。
The Linux Command Line——20. 正则表达式
标签:个数 区域 开头 基本 因此 多个 技术 upper 插入
原文地址:https://www.cnblogs.com/shizhe99/p/14758994.html