标签:流编辑器 grep 技术 tool 表达 ima 添加 lan $2
linux 常用命令:文件、网络、性能
ls
cd
pwd
mkdir
cp
rm
mv
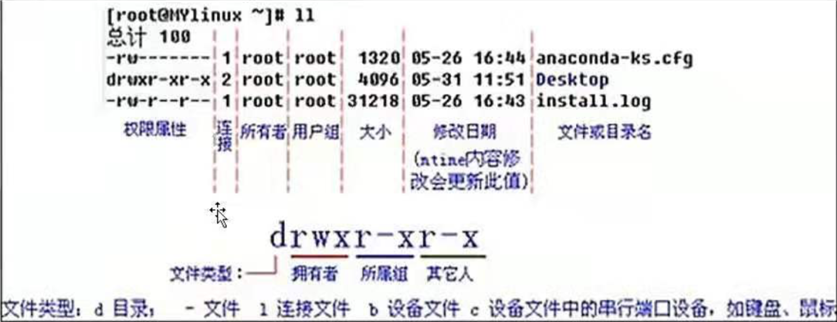
# 授权
r: 读权限 4;
w: 写权限 2;
x: 操作权限 ;
r+w+x=7,是最高权限
chomd 777 文件名
ping # 测试网络连接情况
ping -c 5 www.baidu.com # ping 5次百度
ping -l 2 www.baidu.com # 每间隔2秒ping一次?
netstat # 打印linux网络系统的状态信息
-t # 列出所有tcp
-u # 列出所有udp
-l # 只显示监听端口
-n # 以数字形式显示地址和端口号
-p # 显示进程的pid和名字
netstat -ntlp
top #持续监视系统性能
ps #查看进程信息
ps -aux # 显示所有进程,包括用户,分组情况
top是实时监控,ps是快照,不能实时监控
管道、三剑客(grep,sed,awk)是linux命令,正则不是linux命令
正则训练网址: https://tool.oschina.net/regex/
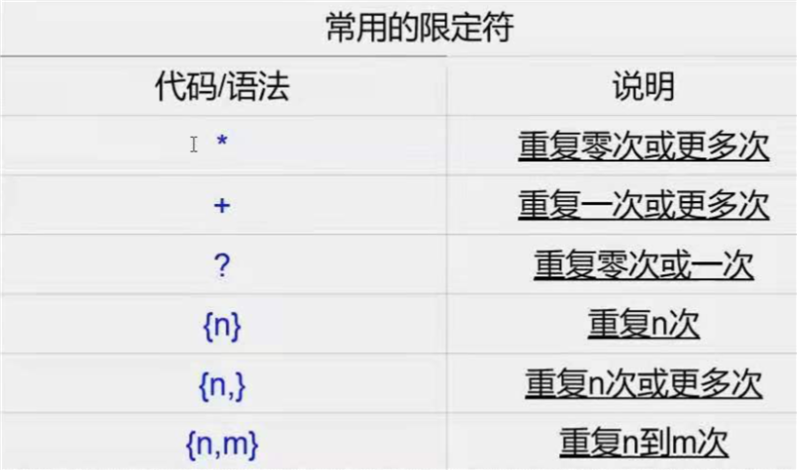
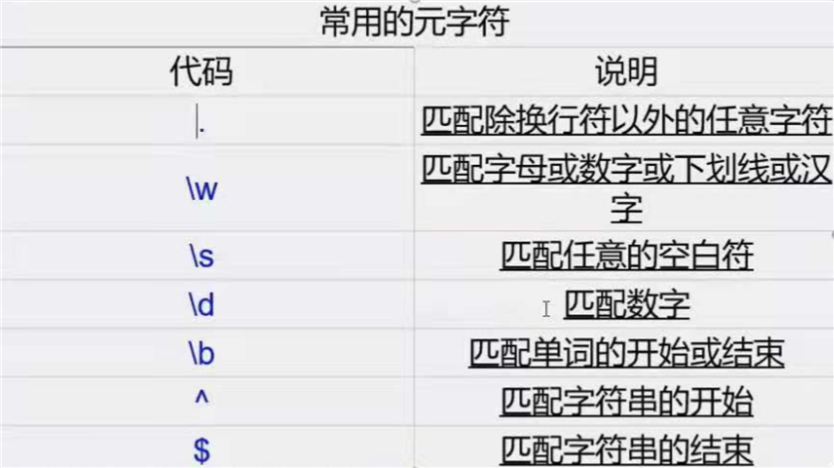
\bhi\b0\d{2}-\d{8}\ba\w*\b\b\w{6}\b\d+\d{5,12}备注: 单词必须以 前后\b来包裹,并且是空格隔开的
定义: 根据用户指定的模式(pattern)对目标文本进行过滤,显示被模式匹配到的行
语法: grep [OPTIONS] PATTERN [FILE]
意思:OPTIONS是参数 PATTERN可以理解为正则,FILE表示对那个文件或文本进行匹配
grep OPTIONS参数:
-v #显示不被pattern匹配到的行
-i #忽略字符大小写
-n #显示匹配的行号
-c #统计匹配的行数
-o #仅显示匹配到的字符串
-E #使用ERE,相当于egrep
hello world root
i am mamingchen
i am ROOT
swap abc
i am root
grep -ni root test.txt
grep -nv root test.txt
# 正则加不加引号都行
grep -n ‘^s‘ test.txt
grep -n ^s test.txt
# 正则加不加引号都行
grep -n ‘n$‘ test.txt
grep -n n$ test.txt
定义:sed是流编辑器,一次处理一行内容
问题:grep其实也是一次处理一行,那sed与grep有什么区别呢?
sed是每次读取文件的一行 -> 临时存储在模式空间->然后sed命令处理->处理完成后送入屏幕->最后清空模式空间;
sed按照上面的流程每次读取一行处理一行,知道全部行都处理完
命令解析:
# 1. 常用参数
sed [-hn..][-e<script>][-f<script文件>][输入的文本文件]
-h #显示帮助
-n #仅显示script处理后的结果
-e<script> # 以选项中指定的script来处理输入的文本文件,-e参数可以省略
-f<script> # 以选项中指定的script文件来处理输入的文本文件
-i<script> # 直接修改源文件
# 2. sed常见动作
1. a # 新增
sed -e ‘4 a newline‘ test.txt # ‘4 a newline‘就是-e指定的脚本内容,意思是:在test.txt文件的第4行的`后面`新增一条文本,文本内容是newline
2. c # 取代
sed -e ‘2,5c No 2-5 number‘ test.txt # ‘2,5c No 2-5 number‘就是-e指定的脚本内容,意思是:用c后面的内容 `No 2-5 number` 去取代test.txt的第2行到第5行的内容
3. d # 删除
sed -e ‘2,5d‘ test.txt # 意思是要删除test.txt文件的第2到5行
4. i # 插入
sed -e ‘2i newline‘ test.txt #意思是在test.txt文件的第2行`前面`插入一条记录,记录的文本内容是newline
5. p # 打印
sed -n ‘/root/p‘ # 意思是匹配到 两个斜杠/中间的内容root后,打印
6. s # 取代
sed -e ‘s/old/new/g‘ test.txt # g是全局的意思。用后面的内容取代前面的内容,意思是在全局用 new去取代匹配到的old,
问题: sed 命令中的a 和 i什么区别?
a是在指定行的后面新增内容; i是在指定行的前面插入内容
# 查看帮助
man sed
sed -h
# 翻页:j向下,k向上
# 注意,-e参数可以省略;这个添加是指输出到屏幕上,并没有真正的改变输入的文本文件test.txt
sed ‘4 a i love taoche‘ test.txt
sed ‘2 i i love taoche‘ test.txt
# s后面不能有空格
sed ‘s/root/i love taoche/g‘ test.txt
sed -i ‘s/root/i love taoche/g‘ test.txt
sed -i ‘4a 一个好汉三个帮‘ test.txt
定义: 把文件按行逐行读入,以空格为默认分隔符将每行切片,切开的部分在进行后续处理
工作流程:
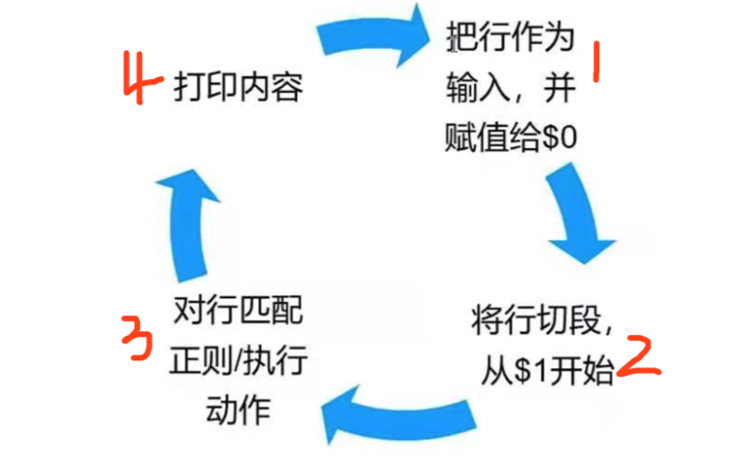
命令形式:
# pattern表示正则表达式,
# action表示对匹配到的内容执行命令(默认为输出每行内容)
# FILENAME表示要处理的输入的文本
# 意思:对FILE进行awk切片,然后再根据脚本‘pattern + action‘处理并打印到屏幕上
awk ‘pattern + action‘ [FILENAME]
常用参数:
FILENAME # awk流量的文件名
BEGIN # 处理文本之前要执行的操作
END # 处理文本之后要执行的操作
FS # 设置输入域分隔符,等价于命令行 -F 选项, 默认分隔符就是空格,可以通过这个参数指定其他分隔符
NF # 浏览记录的域的个数 (列数)
NR # 已读的记录数 (行数)
OFS # 输出域分隔符
ORS # 输出记录分隔符
RS # 控制记录分隔符
$0 # 整条记录
$1 # 表示当前行的第一个域 $2表示当前行的第二个域.....以此类推
# -F : 意思是把/etc/passwd文件按照:分割
# ‘/root/ {print $7}‘: 意思是正则匹配root,打印第7列
# 其中//中间的内容表示正则表达式, {}里面的内容表示执行的动作
awk -F : ‘/root/ {print $7}‘ /etc/passwd
# NR==2 就表示正在读第二行
# 读到第二行的时候,按照:分割,然后打印出整条内容
awk -F: ‘NR==2{print $0}‘ /etc/passwd
# 读到第二行的时候,不用分割,直接打印出整条内容
awk ‘NR==2 {print $0}‘ /etc/passwd
# ‘BEGIN {print "第一列,第二列"} {print $1,$2}‘ 是一个脚本,意思是:在开始执行之前,先做第一个动作{print "第一列,第二列"},在屏幕上打印出第一列,第二列两个标题文字,然后再根据:分割后,执行第二个动作{print $1,$2},在屏幕上打印出分割后的第一列和第二列
awk -F : ‘BEGIN {print "第一列 第二列"} {print $1,$2}‘ /etc/passwd
# echo "111|222|333 444|555 666":表示输出内容
# | awk : 表示把echo "111|222|333 444|555 666" 通过 管道符 给 awk 去处理
# awk ‘BEGIN {RS="|"} {print $0}‘: 表示awk拿到待处理文件后,首先指定控制记录分隔符RS为竖线,等awk处理完成后,打印出第一列内容
echo "111|222|333 444|555 666" | awk ‘BEGIN {RS="|"} {print $0}‘
3. linux常用命令及三剑客 grep sed awk 用法
标签:流编辑器 grep 技术 tool 表达 ima 添加 lan $2
原文地址:https://www.cnblogs.com/victorm/p/14141477.html