标签:开始 tostring 文档 很多 get protobuf 目录 package 构建
日志服务(Cloud Log Service,CLS)是腾讯云提供的一站式日志服务平台,提供了从日志采集、日志存储到日志检索,图表分析、监控告警、日志投递等多项服务,协助用户通过日志来解决业务运维、服务监控、日志审计等场景问题。
简言之就是CLS提供了日志的云化存储,并提供了查询、分析、监控,告警等功能。所以今天就抱着好奇之心,来探索一下使用python如何将本机日志写入到CLS上。
官方文档提供了详细的使用步骤使用步骤,文档链接如下:https://cloud.tencent.com/document/product/614/34340
点击https://cloud.tencent.com/product/cls进入页面,可以点击立即使用开通服务;
当然也可以点击活动公告来查看免费的使用额度:
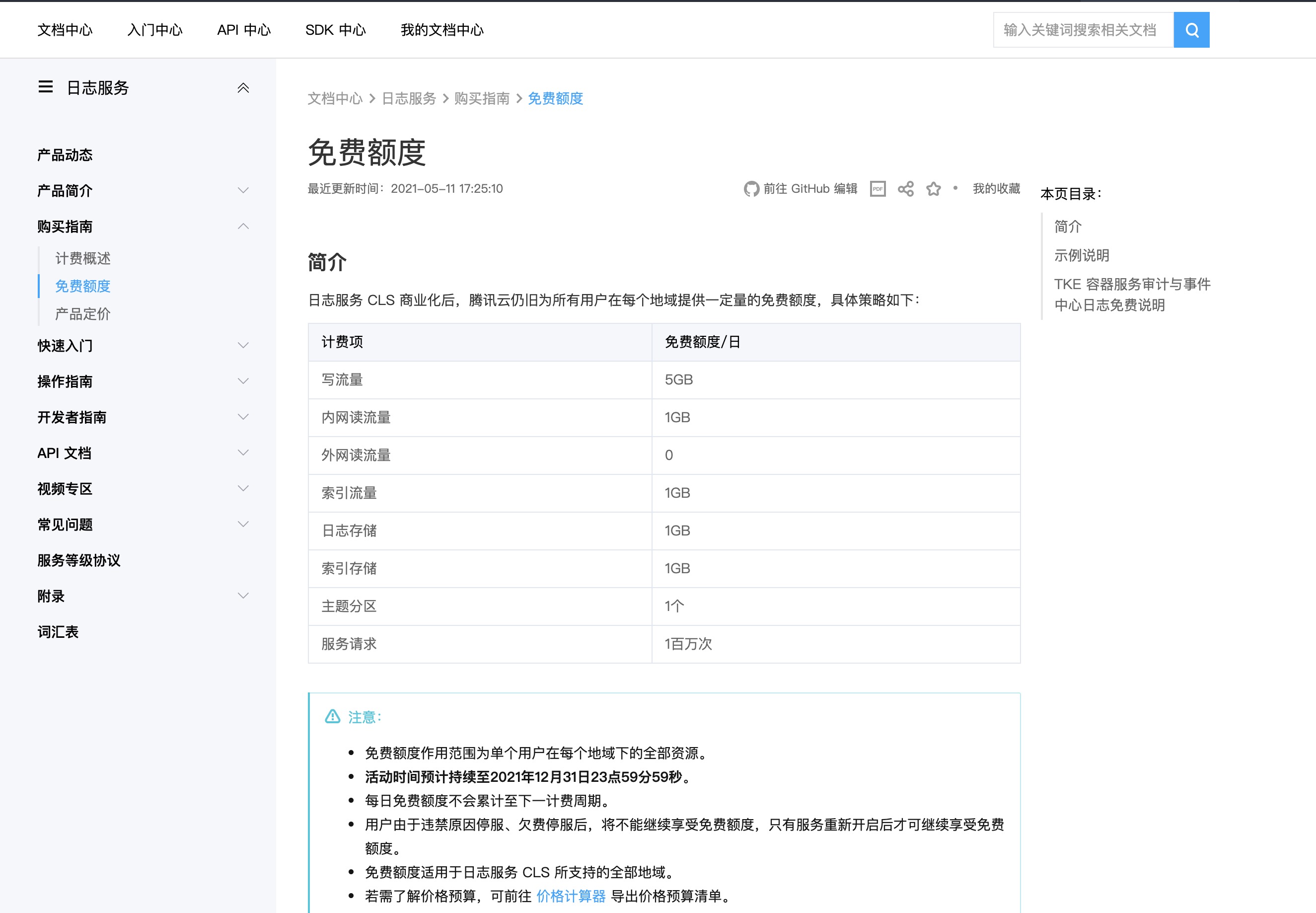
可以看出,免费额度流量额度是5GB/日,活动截止于2021年底。
开通服务后,进入clk服务页面。可以看到,提供了多种日志的接入方案。
日志集(Logset)是日志服务的项目管理单元,用于区分不同项目的日志。日志主题(Topic)是日志服务的基本管理单元,用来存储日志文件。一个日志集可以包含多个日志主题。
点击https://console.cloud.tencent.com/cls/overviewCLS配置页面。
点击侧栏日志主题 ,点击创建日志主题。
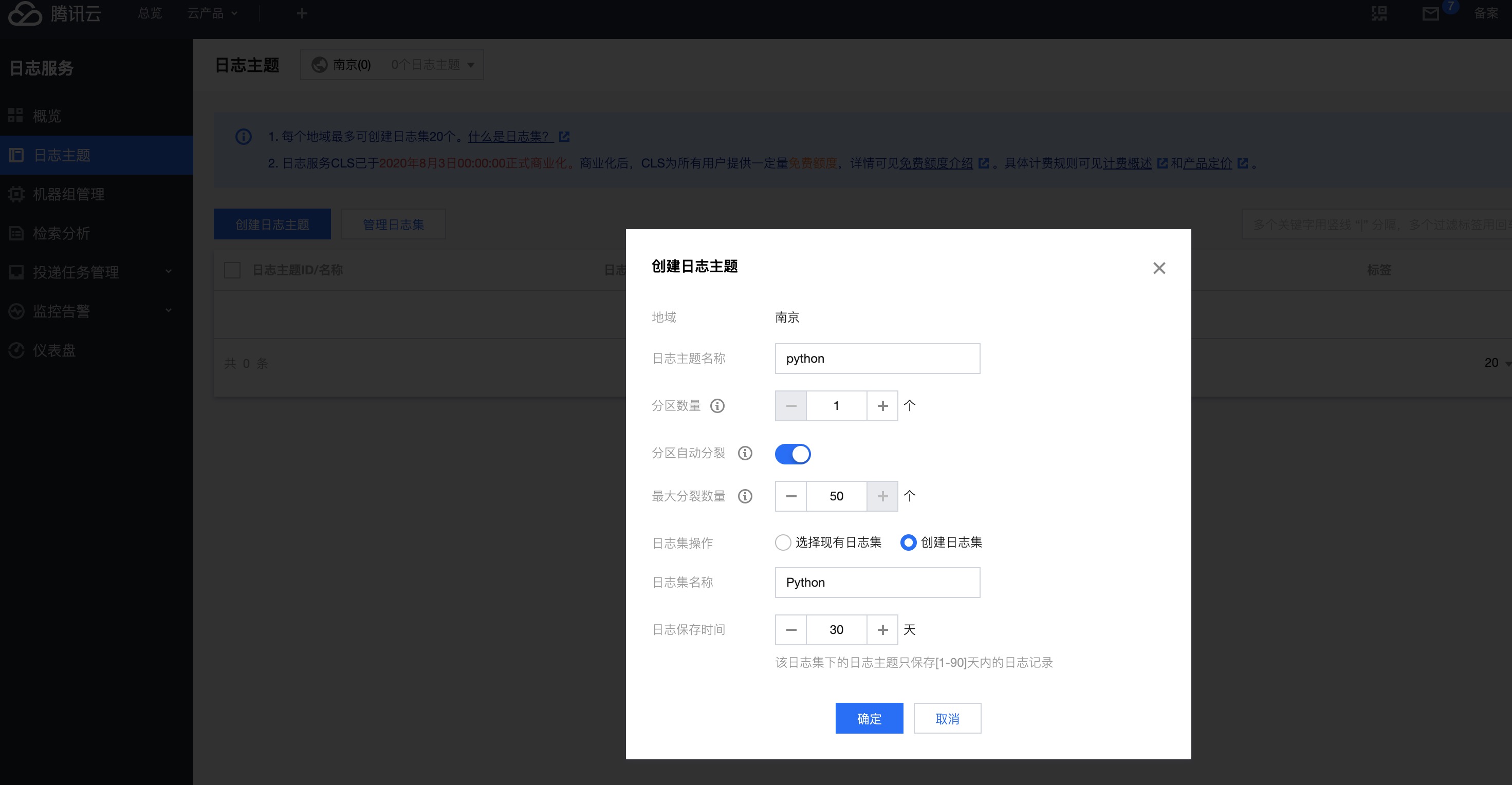
可能是文档过旧,官方文档写的是先要创建日志集,但是没找到这个按钮。其实在第一次创建时主题时输入一个日志集,就会自动创建。
创建好的日志主题如下,这里需要的是主题ID,以为写入时通过ID来将日志写到这个topic。

CLS使用机器组来统一管理一组日志源机器。。同时我也理解成白名单,只有这些机器能访问CLS服务。
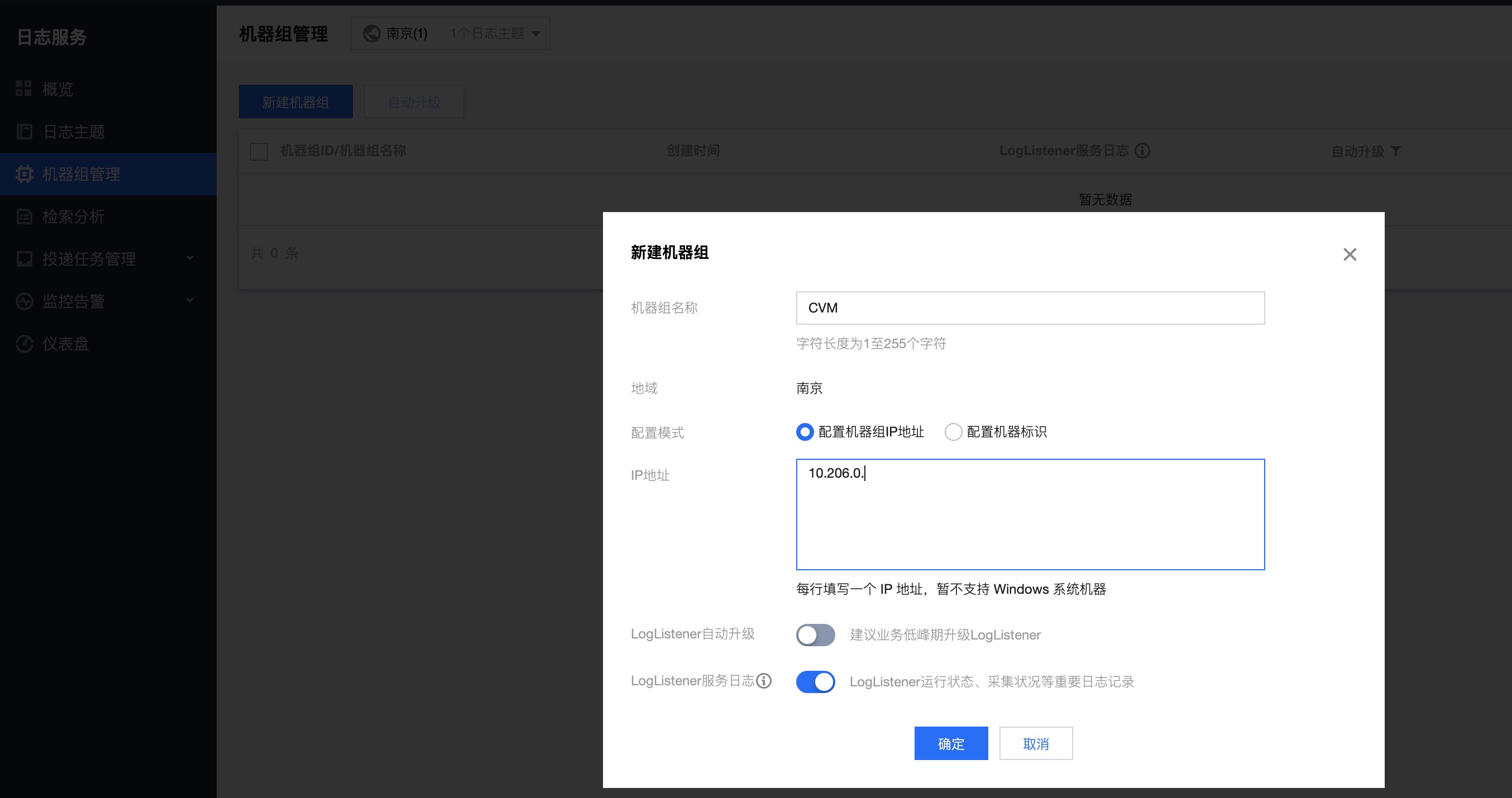
在刚开始CLS的概览页面,可以看到CLS提供了多种快速接入方案,很多需要安装Loglistener来采集日志,这里使用Python利用API写入接入方案来将日志写入,无需安装。
点击每种接入方案都会进入相应的开发文档,这里我点击API写入进入开发文档。
官方提供了API写入规范:
POST /structuredlog?topic_id=xxxxxxxx-xxxx-xxxx-xxxx HTTP/1.1
Host: <Region>.cls.tencentyun.com
Authorization: <AuthorizationString>
Content-Type: application/x-protobuf
x-cls-compress-type:lz4
<LogGroupList 的 PB 格式打包内容>
从上面可以看出有两个参数,一个是topic_id,即日志主题id;一个是LogGroupList,即日志传输协议内容。这里PB指的是使用protobuf进行序列化,所以必须先安装protobuf。
protobuf是一种二进制的序列化格式,相对于json来说体积更小,传输更快。安装protobuf的目的主要用来将proto文件编译成python、c、Java可调用的接口。
# 如果gcc版本较低,需要升级gcc
wget https://main.qcloudimg.com/raw/d7810aaf8b3073fbbc9d4049c21532aa/protobuf-2.6.1.tar.gz
tar -zxvf protobuf-2.6.1.tar.gz -C /usr/local/ && cd /usr/local/protobuf-2.6.1
./configure
make && make install
# 可以在/etc/profile或者~/.bash_profile末尾设置永久有效
export PATH=$PATH:/usr/local/protobuf-2.6.1/bin
使用下面命令查看是否安装成功。
protoc --version
创建cls.proto文件,定义序列化结构:
package cls;
message Log
{
message Content
{
required string key = 1; // 每组字段的 key
required string value = 2; // 每组字段的 value
}
required int64 time = 1; // 时间戳,UNIX时间格式
repeated Content contents = 2; // 一条日志里的多个kv组合
}
message LogTag
{
required string key = 1;
required string value = 2;
}
message LogGroup
{
repeated Log logs = 1; // 多条日志合成的日志数组
optional string contextFlow = 2; // 目前暂无效用
optional string filename = 3; // 日志文件名
optional string source = 4; // 日志来源,一般使用机器IP
repeated LogTag logTags = 5;
}
message LogGroupList
{
repeated LogGroup logGroupList = 1; // 日志组列表
}
只用下面命令将proto文件转换为python可调用的接口。
protoc cls.proto --python_out=./
执行完后,在此目录下生成cls_pb2.py。
代码的开发主要分为三个部分:Protobuf结构构造、Authorization加密构造和请求上传日志。前两个部分细节太多,尤其是Authorization构造涉及sha1加密、hmac-sha1签名以及四个加密参数的构造。:
import cls_pb2 as cls
import time
import requests
from hashlib import sha1
import hmac
# 构建protoBuf日志内容
LogLogGroupList = cls.LogGroupList()
LogGroup = LogLogGroupList.logGroupList.add()
LogGroup.contextFlow = "1"
LogGroup.filename = "python.log"
LogGroup.source = "localhost"
LogTag = LogGroup.logTags.add()
LogTag.key = "key"
LogTag.value = "value"
Log = LogGroup.logs.add()
Log.time = int(round(time.time() * 1000000))
Content = Log.contents.add()
Content.key = "Hello"
Content.value = "World"
print(LogLogGroupList)
# 序列化
LogLogGroupList = LogLogGroupList.SerializeToString()
查看文档:https://cloud.tencent.com/document/product/614/12445,里面有详细的参数生成步骤和样例。
这部分的代码开发绝对考验个人的耐心和细心,适合在夜深人静自己搞。
# 公共参数部分
secretId = ‘替换成你的secretId‘
secretKey = ‘替换成你的secretKey‘
region = ‘ap-nanjing‘
host = f‘{region}.cls.tencentyun.com‘
start = int(time.time())
end = start + 1000
uri = ‘structuredlog‘
method = ‘post‘
params = ‘topic‘
# 构建HttpRequestInfo
HttpRequestInfo = f‘{method}\n‘ + f‘/{uri}\n‘ + ‘\n\n‘
sha1_info = sha1()
sha1_info.update(HttpRequestInfo.encode(‘utf-8‘))
print(sha1_info.hexdigest())
# 根据HttpRequestInfo构建StringToSign
StringToSign = ‘sha1\n‘ + f‘{start};{end}\n‘ + sha1_info.hexdigest() + ‘\n‘
key = secretKey.encode(‘utf-8‘)
value = f‘{start};{end}‘.encode(‘utf-8‘)
SignKey = hmac.new(key, value, ‘sha1‘)
print(SignKey.hexdigest())
# 根据StringToSign构建Signature
key = SignKey.hexdigest().encode(‘utf-8‘)
value = StringToSign.encode(‘utf-8‘)
Signature = hmac.new(key, value, ‘sha1‘).hexdigest()
print(Signature)
# 构建Authorization
Authorization = f‘q-sign-algorithm=sha1&q-ak={secretId}&q-sign-time={start};{end}&q-key-time={start};{end}&q-header-list=&q-url-param-list=&q-signature={Signature}‘
这一块是让我感觉最难的,里面的坑太多,一个参数套一个参数,容易让人云里雾里,所以大部分时间都花在了测试参数生成这部分。

如图,一直提示我签名计算错误,原因总结如下:1.参数拼接不对;2.hmac的kv弄反。
本来我也在请求头里添加了lz4压缩格式,但是运行发现代码中未实现lz4的压缩,所以报了以下错误。

最后舍弃了lz4请求头,压缩功能也没有实现。有兴趣的可以搞一下。
其实就是构造一个post请求,将日志序列化成protobuf格式上传到服务器。
# 发起请求
url = f‘https://{host}/{uri}?topic_id=717eba7d-85bb-4cd5-9c68-dfaa9f672bc6‘
headers = {‘Authorization‘: Authorization, ‘Host‘: host, ‘Content-Type‘: ‘application/x-protobuf‘}
response = requests.post(url, headers=headers, data=LogLogGroupList)
print(response.status_code, response.text)
print(LogLogGroupList)
python3运行程序:

打印了日志的protobuf结构信息、二进制数据,以及加密参数和请求状态码。
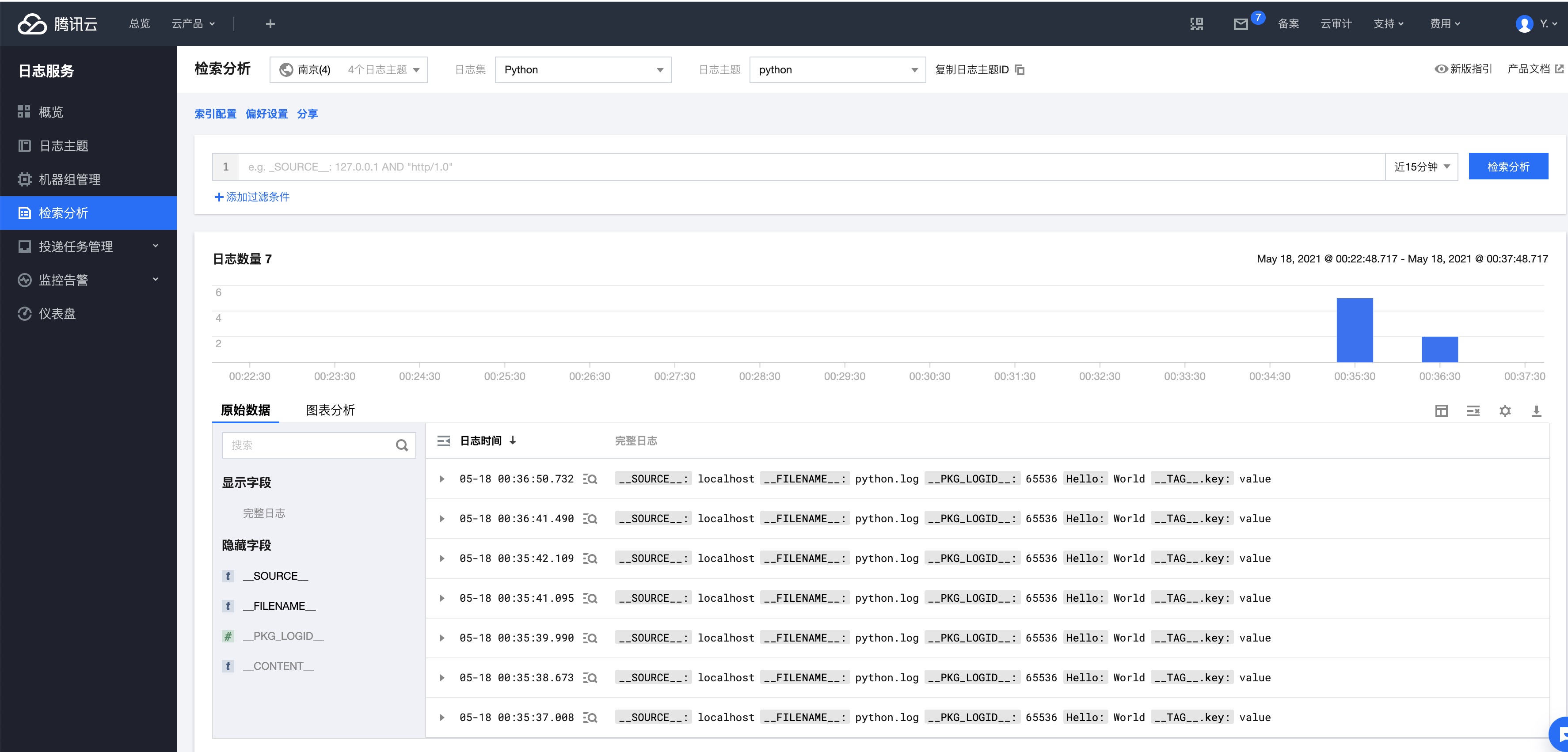
接着进入CLS页面查看,日志已经写入。
跟着文档从学习CLS、python开发到收集素材、整理成文章差不多用了五、六个小时,下班就在搞,写到这的时候已经凌晨一点了,本来还想用Java写一版,但是实在是肝不动了。

希望这篇文章能够帮助你了解CLS,期待下一次相遇。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。

标签:开始 tostring 文档 很多 get protobuf 目录 package 构建
原文地址:https://www.cnblogs.com/seven0007/p/cls.html