标签:src 创建 loading and 内存地址 详解 通过 数据类型 none
Python中关于变量有三个概念需要明确,分别是变量,引用,对象。
因此每个变量所需要的存储空间大小一致,与所指向的对象类型无关,因为每个变量都只是保存了指向对象的内存地址。
变量都没有类型(都是对象的引用),这意味着变量可以指向任何对象。
变量是分配在栈上,用来指向某一个对象。
变量分为可变变量和不可变变量;
对象是分配在内存空间上,用来存放真正的数据。对象有类型,不同对象有不同的类型,如str,int等。不同对象根据存储的数据大小不同,所占用的内存空间也不同。
python中一切皆对象,一个列表,值,函数,类等都可以成为对象。
因为变量是无类型的,它可以指向任何对象。同一个对象可能被多个变量引用(指向),因此会涉及一个对象引用计数,回收机制,以及引用同一个对象的不同变量之间的操作影响关系。
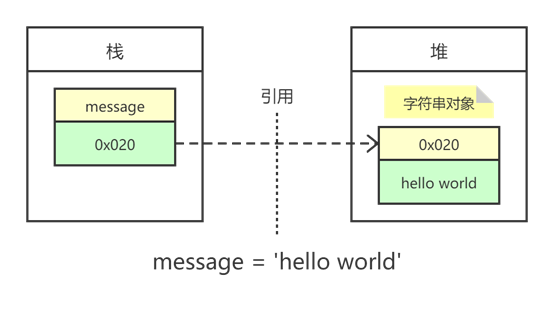
在代码message=‘hello world’中,python解释器完成了三件事:
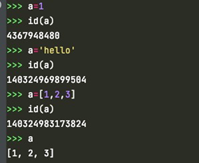
可以看到,上述的行为总是正确的,不会报错。因为变量a是无类型的,不同的赋值只是建立了不同的引用,a中存放的地址不同,指向的对象不同。而在强类型语言如c语言中,创建一个变量就是开辟一块存储空间,并且给该空间命名,这个名字就是变量。因此在强类型语言中,定义变量时都需要指定变量类型。而python中变量本质是一个指针,没有类型也不需要指定类型,它可以指向任意类型的变量。这也是叫python的动态类型机制,任何时候根据需要,变量都可以重新绑定在另一个不同类型的对象上,当一个对象不存在任何引用时,就通过垃圾回收机制被回收。
(4) 对象的垃圾回收:
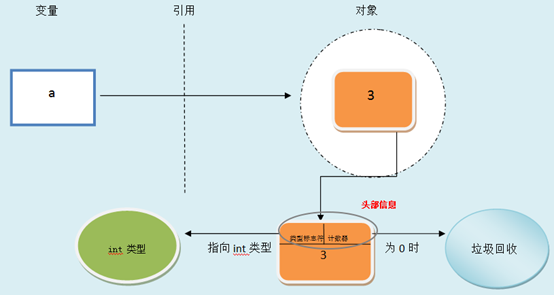
一个对象包含地址id,type类型,存放的value;其中每个对象包含了两个头部信息,一个是类型标志符(即对象的类型type),一个是计数器。计数器反应的是该对象被引用的次数,一旦这个计数器为0,代表没有变量引用该对象,该对象的内存空间就会自动回收。这样的一个好处是在python编程时可以任意使用对象而不用考虑释放内存空间,一旦该对象没有变量引用后,会自动清理和释放。
eg:
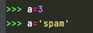
a指向了新的对象,上一个对象3的引用计数为0,立马就被回收了。
eg:
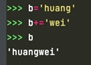
变量b首先指向对象‘huang’,然后b+=’wei’并非修改了原对象,而是建立了一个新对象’huangwei’,b重新指向新的对象,原对象‘huang’因为没有变量引用,被回收。
对可变对象的编辑,等于在变量本身上进行编辑,并没有生成新对象;
对不可变对象的编辑,等于新建对象。
eg:
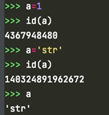
因为int是不可变对象,当重新赋值a=’str’时,等于创建了新的对象’str’,a重新指向了新对象(a的地址也随之改变),之前的对象1被回收。
eg:
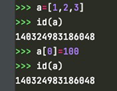
改变列表中某个值,并未新建对象,还是同一个对象,只是修改了对象内部的某个值。
理解:

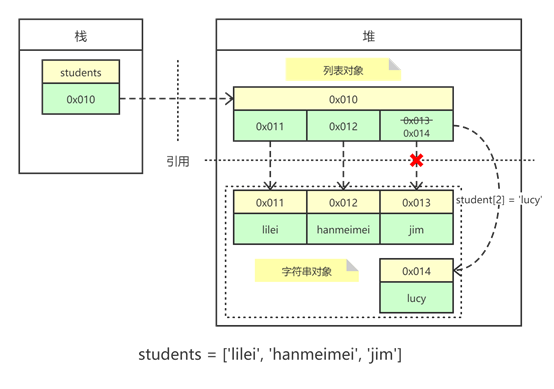
可以看到,对于可变对象,在对象内部第一层存储的对象id和值,而值同样是地址,继续引用外部对象。因此判定是否是可变对象,主要看在对象内部是否独立,还是引用了外部对象。
在本例子中,变量students存放了列表对象的地址0x010;列表对象内部的value仍是地址,指向外部对象。当students[2]=’lucy’执行后,改变了列表对象的第二个地址(引用),对象本身的地址是没变的。因此students还是指向同一个对象。
(1) 赋值
对于变量赋值,如a=b这种,可以理解为别名,本质上是创建了新的引用,,a和b两个变量存放的地址相同,指向同一个对象。对变量a进行操作(对其指向的对象进行操作),反过来可能会影响变量b。
赋值操作本身不会创建任何新的对象和内存空间,产生的都是原对象的引用。
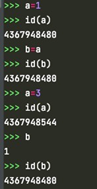
可以看到,一开始b=a后,二者存放的地址相同,都指向1;a=3后,相当于a指向了新的对象3,a中存放新的地址。而原来的b地址不变,还是指向1。这种情况下对a的操作不会影响b。
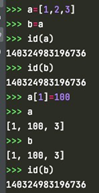
对a中的元素进行编辑后,本质上修改对象中value里存放的引用地址,而列表对象的地址没变。因此a和b中地址指向该对象,经过a的操作后对象值改变,b指向的对象值跟着改变,因为指向的都是一个对象。
因此,对于变量赋值,要很小心,尤其是在可变对象的情况下。为了防止这样的危险影响产生,因此有了浅拷贝和深拷贝(主要针对可变对象而言,对不可变对象没有必要进行拷贝操作)。
(2) 浅拷贝
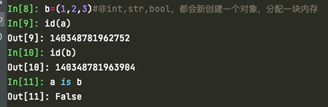
浅拷贝会创建新的对象,原对象的一个拷贝(只拷贝最外面一层),分配一个新的内存空间来存储该新对象;因此该新对象存储的值或者引用和原对象相同,类型相同,但是id不同。
切片操作、工厂函数、对象的copy()方法、copy模块中的copy函数.
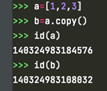
可以看到,a和b的id已经不同了,a和b的value都是一样的。
注意,浅拷贝只拷贝了对象最外面一层,对内部引用的对象是没有拷贝的。如下图:
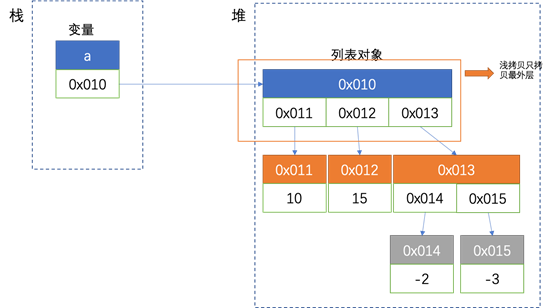


图解过程:
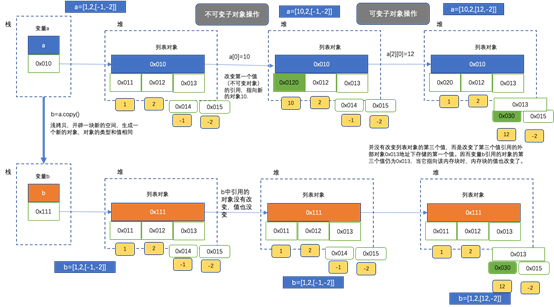
对于dataframe等也一样,只要里面子对象不是可变对象,那么可以通过浅拷贝将二者分隔开互不影响。但若子对象是可变对象,对子对象的更改也会影响拷贝的对象。
注意对于np.array不同,浅拷贝后,就算对内部可变数组进行操作,不会影响拷贝对象,类似于深拷贝(具体原因待探究)
(3) 深拷贝
对每一层都会完全拷贝为新对象,相互之间完全不影响。
可见浅拷贝相对深拷贝:
因为只拷贝顶层数据,速度更快,占用内存更低。但是要注意对可变子对象操作的影响。
(1) Python中,=操作赋值操作,是建立一个引用(c语言中=是创建一个对象)。Python中赋值操作=总是创建对象的引用。
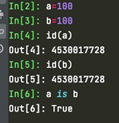
(2) is和==是比较操作,a==b 比较的是两个对象内存储的值是否相同,准确的说,是两个变量指向(或引用)对象中的值是否相等。Is是比较a和b的内存地址是否相同(或者叫是否引用的同一个对象)。
参考浅拷贝中的图来举例子:

但是要注意对于int,str,bool类型,同一个值对应同一个id,新创建的引用并不像其他类型如list一样,会创建一个新的id地址保存数据。
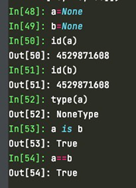
(1) None是一种特殊的数据类型,可以认为是一种特殊的常数类型。既然是特殊的常数类型,a=None,b=None,a和b地址以及值都相同,即a==b和a is b都会返回True。None经常用在代码中用于条件的判断比如if a is None或者if a==None.
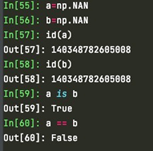
(2) NAN是numpy下面一种特殊的float类型。是“not a number”的缩写。一方面可以认为是空值,比如在读取csv文件时,如果里面某个值没有,读进来就会为NAN;另一方面是在数学中必入无穷大-无穷大,无穷大*0,这样的直接计算本身有问题,就会返回NAN。虽然是float类型,a=NAN,b=NAN,a和b的id相同,但是a==b会返回False,这是和一般的float的规则不一样的。可以理解为不同的NAN代表的含义(value)可能不一样,有的代表为空,有的代表是无穷大-无穷大,有的代表无穷大*0。Pandas中的nan也是这个NAN,即np.float类型。
(3) Null在python中啥都不是,没有这个数据类型。只是我们一般说空值会说它是null(c语言里面沿用过来的),而空值的范围比None,NAN更广,‘’,[],{}都代表空值。
标签:src 创建 loading and 内存地址 详解 通过 数据类型 none
原文地址:https://www.cnblogs.com/qianfanwaer/p/14783204.html