标签:odi 服务端 follow 怎么 失败 href weixin 类型 解析
在爬取某网站时,我们习惯于直接在浏览器里复制headers和请求参数,粘贴到自己的代码里进行调试
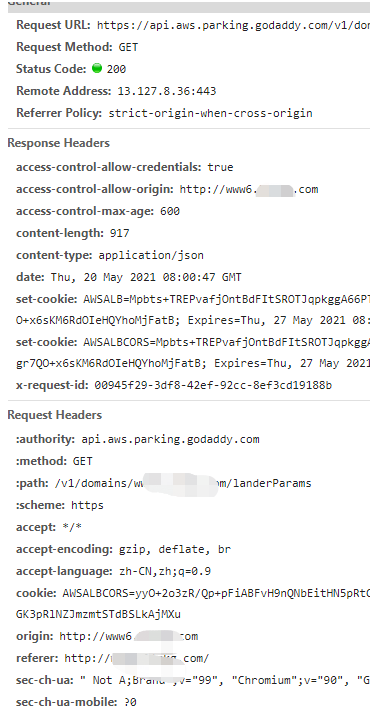
对了这个也是用的httpx处理的,因为这个网站跟上一篇 python爬虫 - 爬虫之针对http2.0的某网站爬取 - 修复版 是同一个网站
但是,在爬取某网站时网站时,发现了一个问题:
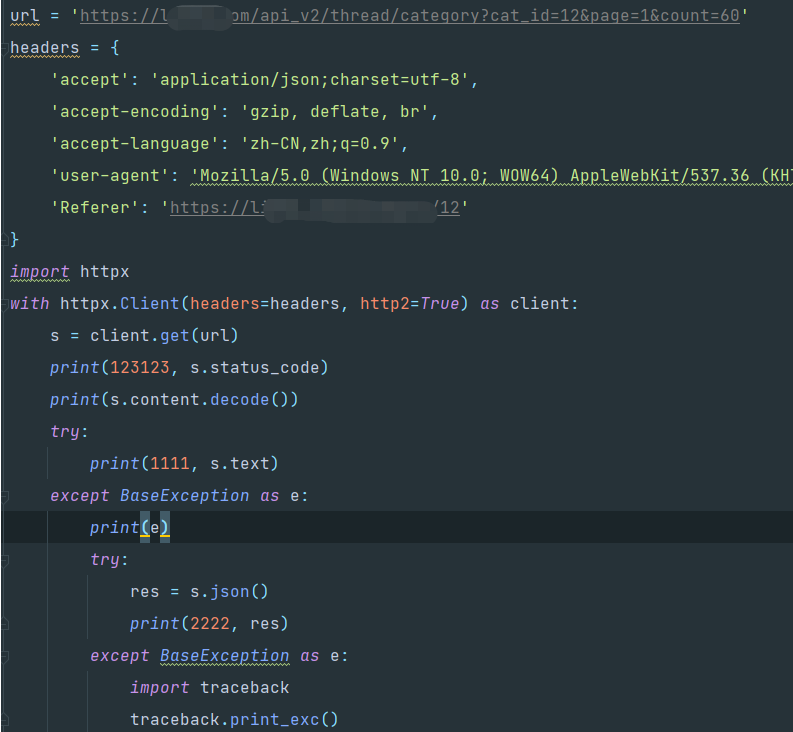
运行:

无论怎么调试,就是说解码失败
后面发现是请求头里的‘accept-encoding‘: ‘gzip, deflate, br‘
把其中的br删除掉就可以正常拿到数据:
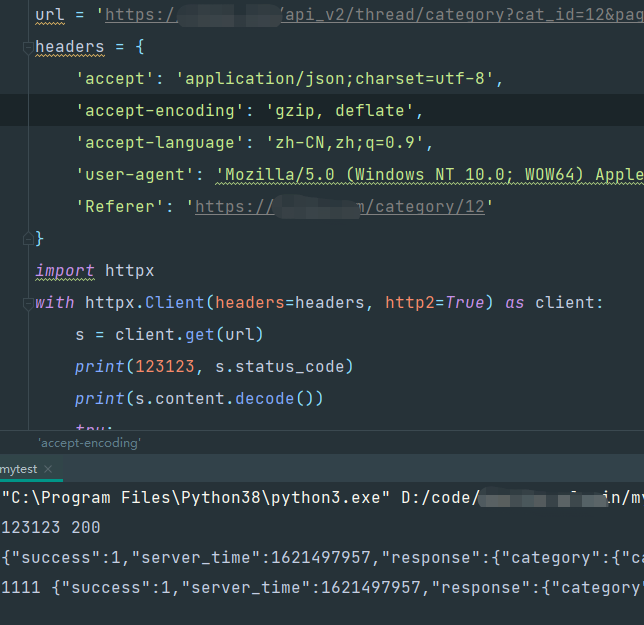
有关accpt-encoding的,可以看这篇博客:
https://blog.csdn.net/weixin_40414337/article/details/88561066
精简的意思就是,accpet-encoding的作用是以客户端的身份告诉服务端,我支持那些数据压缩类型的,如果指定的话,服务端就会按指定好的格式返回,如果不指定的话就会不压缩,而以源数据返回
其中gzip和deflare两种类型的压缩,requests和httpx等主流的爬虫库都是可以自己解压缩数据的,而就是br不行,因为br是目前来说比较新的一种数据压缩格式,无损压缩,压缩比极高,比前两个都好,进而减少传输数据的大小,节省时间,所以目前的都支持br,浏览器也自然支持的,这就是问题所在
这也就是我上面把br删了就可以正常解析的原因
另外,针对br的,假如有的网站就支持br呢?咋办? 所以在代码层面也是要解决的,而不是逃避问题的把br删除掉
解决办法就是需要用brotli库(第三方库,需要安装)来解压,上面的博客里的案例
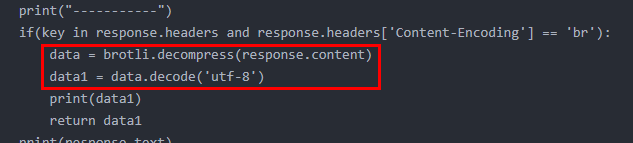
安装完brotli后执行:
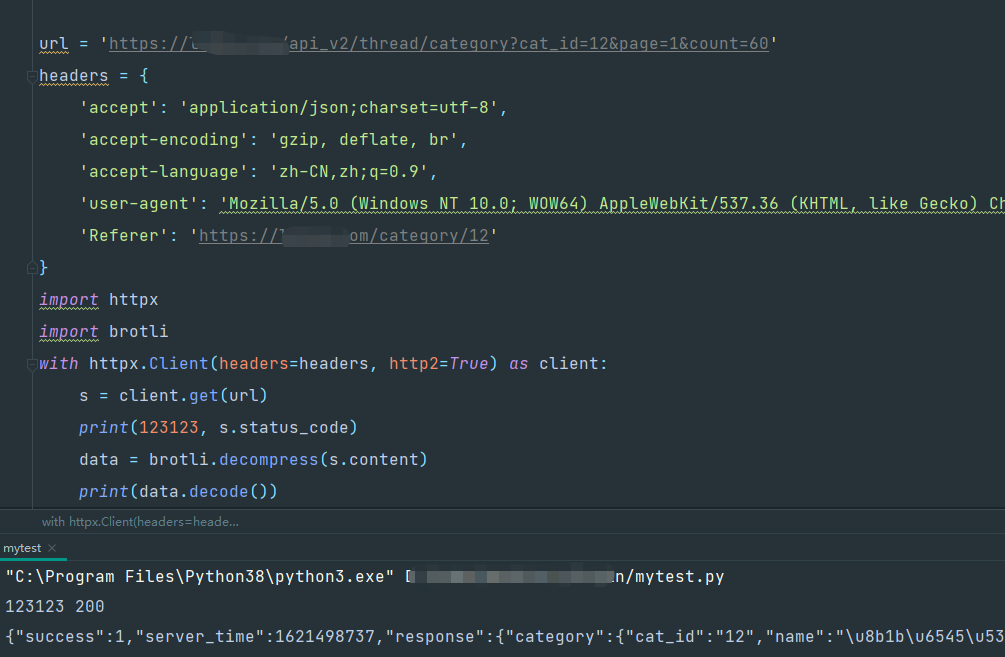
那么,用这种brotli压缩还可以一定程度上达到反爬的效果,反正如果不知道这个的话,拿到返回的数据后你用各种编码方式(utf-8,gbk,gb18030,bt5)啥啥的,怎么解码都解不了,是不是可以防止一些初级的爬虫了啊
python爬虫 - 反爬之关于headers头的accept-encoding的问题
标签:odi 服务端 follow 怎么 失败 href weixin 类型 解析
原文地址:https://www.cnblogs.com/Eeyhan/p/14790322.html