标签:ima 训练 作用 gen 深度学习 environ 影响 推荐系统 方式
在一定的抽象程度上,进化方法可被视为这样一个过程:从个体构成的群体中采样并让其中成功的个体引导未来后代的分布。但是,其数学细节在生物进化方法的基础上实现了很大的抽象,我们最好将进化策略看作是一类黑箱的随机优化技术。
策略作用方式以交叉熵CEM(一种进化算法)为例:算法先随机初始化参数和确定根据参数生成解的规则,根据参数生成N组解并评价每组解的好坏,选出评估结果在前百分之ρ的解并根据这些精英解采取重要性采样方法更新参数,新参数被用作下一轮生成N组解,如此循环直到收敛~
特别的几点包括:进化策略的实现更加简单(不需要反向传播),更容易在分布式环境中扩展,不会受到奖励稀疏的影响,有更少的超参数。这个结果令人吃惊,因为进化策略就好像是在一个高维空间中简单地爬山,每一步都沿着一些随机的方向实现一些有限的差异。
进化算法的目标与强化学习优化的目标都是预期奖励。但是,强化学习是将噪声注入动作空间并使用反向传播来计算参数更新,而进化策略则是直接向参数空间注入噪声。换个说话,强化学习是在「猜测然后检验」动作,而进化策略则是在「猜测然后检验」参数。因为我们是在向参数注入噪声,所以就有可能使用确定性的策略(而且我们在实验中也确实是这么做的)。也有可能同时将噪声注入到动作和参数中,这样就有可能实现两种方法的结合。
进化策略和强化学习区别:
强化学习一般在动作空间(Action Space)进行探索(Exploration)。而相应的Credit或者奖励,必须在动作空间起作用,因此,存在梯度回传(back propagation)。进化算法直接在参数空间探索,不关心动作空间多大,以及对动作空间造成多大影响。
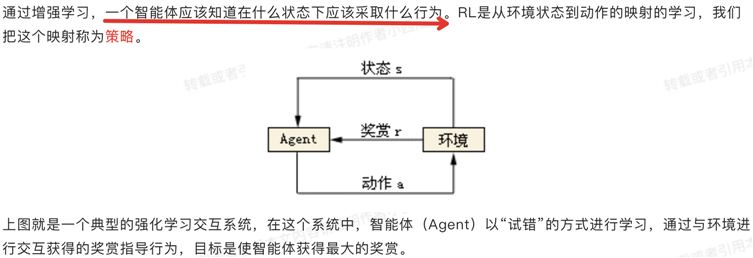
本质是:基于环境而行动,以取得最大化的预期收益。
强化学习具有高分导向性,和监督学习中的标签有些类似。但是又有些区别,区别就在于数据和标签一开始都不存在,需要模型自己来不断摸索。通过不断尝试,找到那些能带来高分的行为。
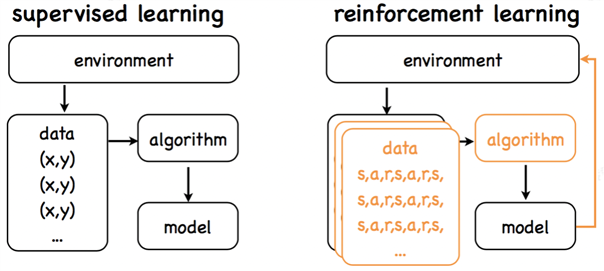
强化学习与有监督学习区别:
监督学习:
强化学习:
参考文献:
标签:ima 训练 作用 gen 深度学习 environ 影响 推荐系统 方式
原文地址:https://www.cnblogs.com/eilearn/p/14824174.html