标签:重复 习惯 数据区 避免 字符串 引擎 返回 数字 info
主要总结了MySQL数据库在设计和书写时的一些规范和提高性能的操作
1.设计时
(1)没有特殊要求,所有表必须使用 Innodb 存储引擎
没有特殊要求(即没有 Innodb 无法满足的功能,如:列存储,存储空间数据等)的情况下,所有表必须使用 Innodb 存储引擎(MySQL5.5 之前默认使用 Myisam,5.6 以后默认的为 Innodb)。
Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
(2)数据库和表的字符集统一使用 UTF8
UTF8兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
(3)养成给表和字段添加注释的习惯
使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
(4)控制单表数据量的大小,建议数据量在 500 万以内。
虽然500 万不是 MySQL 数据库的限制,但是过大会造成修改表结构,备份,恢复都会有很大的问题。可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小
(5)使用 MySQL 分区表要注意
分区表在物理上表现为多个文件,在逻辑上表现为一个表;
谨慎选择分区键,跨分区查询效率可能更低;
建议采用物理分表的方式管理大数据。
(6)尽量避免在表中建立预留字段
因为预留字段的命名很难做到见名识义。而且预留字段无法确认存储的数据类型,所以无法选择合适的类型。对预留字段类型的修改,会对表进行锁定。
(7)尽量做到冷热数据分离,以减小表的宽度
MySQL 规定每个表最多存储 4096 列,并且每一行数据的大小不能超过 65535 字节。能够减少磁盘 IO,保证热数据的内存缓存命中率,表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的 IO。能更有效的利用缓存,避免读入无用的冷数据。根据经验预先将经常一起使用的列放到一个表中以避免更多的关联操作。
2.书写时
(1)查询时尽量不使用select *,而是select具体的字段。
![]()
原因:只取需要的字段,节省资源、减少网络开销;select * 进行查询时,很可能就不会使用到覆盖索引了,就会造成回表查询。
(2)如果预先知道查询结果只有一条或者只要最大、最小一条记录,可以用limit 1
![]()
原因:加上limit 1后,只要找到了对应的一条记录,就不会继续向下扫描了,效率将会大大提高。limit的存在主要就是为了防止全表扫描,从而提高性能。
(3)应尽量避免在where子句中使用or来连接条件

原因:使用or可能会使索引失效,从而全表扫描,效率降低。
(4)优化limit分页
原因:当偏移量最大的时候,查询效率就会越低,因为MySQL并非是跳过偏移量直接去取后面的数据,而是先把偏移量+要取的条数,然后再把前面偏移量这一段的数据抛弃掉再返回的。
(5)优化like语句
![]()
日常开发中,如果用到模糊关键字查询,很容易想到like,但是like很可能让你的索引失效,效率降低。
原因:把%放前面,并不走索引,如果把%放关键字后面,仍然会走索引。
(6)尽量避免在索引列上使用MySQL的内置函数
原因:索引列上使用MySQL的内置函数,索引会失效,效率降低。
(7)应尽量避免在 where 子句中对字段进行表达式操作,这将导致系统放弃使用索引而进行全表扫描
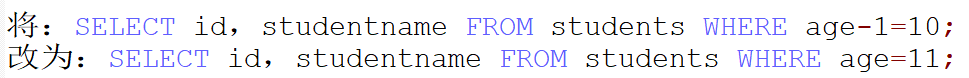
原因:虽然age加了索引,但是因为对它进行运算,而进行全表扫描了。
(8)Inner join 、left join、right join,优先使用Inner join,如果是left join,左边表结果尽量小
![]()
Inner join 内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集;left join 在两张表进行连接查询时,会返回左表所有的行;right join 在两张表进行连接查询时,会返回右表所有的行。
原因:如果inner join是等值连接,或许返回的行数比较少,所以性能相对会好一点。同理,使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少。
(9)应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。

(10)对查询进行优化,应考虑在 where 及 order by 涉及的列上建立索引,尽量避免全表扫描。
(11)如果插入、删除数据过多,考虑批量插入、删除。


(12)在适当的时候,使用覆盖索引
覆盖索引能够使得你的SQL语句不需要回表,仅仅访问索引就能够得到所有需要的数据,大大提高了查询效率。
(13)慎用distinct关键字

distinct 关键字一般用来过滤重复记录,以返回不重复的记录。在查询一个字段或者很少字段的情况下使用时,给查询带来优化效果。但是在字段很多的时候使用,却会大大降低查询效率。
原因:当查询很多字段时,如果使用distinct,数据库引擎就会对数据进行比较,过滤掉重复数据,然而这个比较,过滤的过程会占用系统资源,cpu时间。
(14)where子句中建议使用默认值代替null。

原因:如果把null值,换成默认值,让走索引的可能增加,同时,意思会更清晰。
(15)避免5个以上的表连接
原因:连表越多,编译的时间和开销也就越大;把连接表拆开成较小的几个执行,可读性更高;
(16)尽量用 union all 替换 union

如果检索结果中不会有重复的记录,推荐union all 替换 union。
原因:如果使用union,不管检索结果有没有重复,都会尝试进行合并,然后在输出最终结果前进行排序。如果已知检索结果没有重复记录,使用union all 代替union,这样会提高效率。
(17)避免超过5个索引
原因:索引并不是越多越好,索引虽然提高了查询的效率,但是也降低了插入和更新的效率;插入或更新操作时有可能会重建索引,所以建索引需要慎重考虑,视具体情况来定。
(18)尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型
原因:相对于数字型字段,字符型会降低查询和连接的性能,并增加存储成本。
(19)索引应建立在区分度高的字段上,不适合建在有大量重复数据的字段上
原因:索引应该是数据区别度高的属性数据,因为SQL优化器是根据表中数据量来进行查询优化的,如果索引列有大量重复数据,MySQL查询优化器推算发现不走索引的成本更低,很可能就放弃索引了。
(20)当在SQL语句中连接多个表时,请使用表的别名,并把别名前缀于每一列上,这样语义更加清晰。
(21)尽可能使用varchar/nvarchar 代替 char/nchar。
原因:因为首先变长字段存储空间小,可以节省存储空间。其次对于查询来说,在一个相对较小的字段内搜索,效率更高。
(22)为了提高group by 语句的效率,可以在执行到该语句前,把不需要的记录过滤掉。

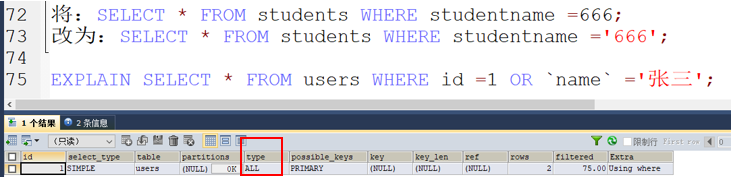
(23)如果字段类型是字符串,where时一定用引号括起来,否则索引失效

原因:不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的
类型转换,把它们转换为浮点数再做比较。
(24)建议养成使用explain 分析SQL的习惯
用explain分析一下自己设计的SQL,尤其是走不走索引
标签:重复 习惯 数据区 避免 字符串 引擎 返回 数字 info
原文地址:https://www.cnblogs.com/banyuanjunxiaoyuan/p/14824604.html