标签:区别 说明 输出 机制 为什么 思路 存在 很多 内存布局
- 在类的定义中,前面有
virtual关键字的成员函数称为虚函数;virtual关键字只用在类定义里的函数声明中,写函数体时不用。
class Base
{
virtual int Fun() ; // 虚函数
};
int Base::Fun() // virtual 字段不用在函数体时定义
{ }
- 「派生类的指针」可以赋给「基类指针」;
- 通过基类指针调用基类和派生类中的同名「虚函数」时:
- 若该指针指向一个基类的对象,那么被调用是 基类的虚函数;
- 若该指针指向一个派生类的对象,那么被调用 的是派生类的虚函数。
这种机制就叫做“多态”,说白点就是调用哪个虚函数,取决于指针对象指向哪种类型的对象。
// 基类
class CFather
{
public:
virtual void Fun() { } // 虚函数
};
// 派生类
class CSon : public CFather
{
public :
virtual void Fun() { }
};
int main()
{
CSon son;
CFather *p = &son;
p->Fun(); //调用哪个虚函数取决于 p 指向哪种类型的对象
return 0;
}
上例子中的p 指针对象指向的是 CSon 类对象,所以 p->Fun() 调用的是 CSon 类里的 Fun 成员函数。
- 派生类的对象可以赋给基类「引用」;
- 通过基类引用调用基类和派生类中的同名「虚函数」时:
- 若该引用是一个基类的对象,那么被调用是基类的虚函数;
- 若该引用是一个派生类的对象,那么被调用 的是派生类的虚函数。
这种机制就叫做“多态”,说白点就是调用哪个虚函数,取决于引用的对象是哪种类型的对象。
// 基类
class CFather
{
public:
virtual void Fun() { } // 虚函数
};
// 派生类
class CSon : public CFather
{
public :
virtual void Fun() { }
};
int main()
{
CSon son;
CFather &r = son;
r.Fun(); //调用哪个虚函数取决于 r 引用哪种类型的对象
return 0;
}
}
上例子中的 r引用的对象是 CSon 类对象,所以 r.Fun() 调用的是 CSon 类里的 Fun 成员函数。
class A
{
public :
virtual void Print() { cout << "A::Print"<<endl ; }
};
// 继承A类
class B: public A
{
public :
virtual void Print() { cout << "B::Print" <<endl; }
};
// 继承A类
class D: public A
{
public:
virtual void Print() { cout << "D::Print" << endl ; }
};
// 继承B类
class E: public B
{
virtual void Print() { cout << "E::Print" << endl ; }
};
A类、B类、E类、D类的关系如下图:
int main()
{
A a; B b; E e; D d;
A * pa = &a;
B * pb = &b;
D * pd = &d;
E * pe = &e;
pa->Print(); // a.Print()被调用,输出:A::Print
pa = pb;
pa -> Print(); // b.Print()被调用,输出:B::Print
pa = pd;
pa -> Print(); // d.Print()被调用,输出:D::Print
pa = pe;
pa -> Print(); // e.Print()被调用,输出:E::Print
return 0;
}
在面向对象的程序设计中使用「多态」,能够增强程序的可扩充性,即程序需要修改或增加功能的时候,需要改动和增加的代码较少。
下面我们用设计 LOL 英雄联盟游戏的英雄的例子,说明多态为什么可以在修改或增加功能的时候,可以较少的改动代码。
LOL 英雄联盟是 5v5 竞技游戏,游戏中有很多英雄,每种英雄都有一个「类」与之对应,每个英雄就是一个「对象」。
英雄之间能够互相攻击,攻击敌人和被攻击时都有相应的动作,动作是通过对象的成员函数实现的。
下面挑了五个英雄:
基本思路:
为每个英雄类编写 Attack、FightBack 和 Hurted 成员函数。
Attack 函数表示攻击动作;
FightBack 函数表示反击动作;
Hurted 函数表示减少自身生命值,并表现受伤动作。
设置基类CHero,每个英雄类都继承此基类
// 基类
class CHero
{
protected:
int m_nPower ; //代表攻击力
int m_nLifeValue ; //代表生命值
};
// 无极剑圣类
class CYi : public CHero
{
public:
// 攻击盖伦的攻击函数
void Attack(CGaren * pGaren)
{
.... // 表现攻击动作的代码
pGaren->Hurted(m_nPower);
pGaren->FightBack(this);
}
// 攻击瑞兹的攻击函数
void Attack(CRyze * pRyze)
{
.... // 表现攻击动作的代码
pRyze->Hurted(m_nPower);
pRyze->FightBack( this);
}
// 减少自身生命值
void Hurted(int nPower)
{
... // 表现受伤动作的代码
m_nLifeValue -= nPower;
}
// 反击盖伦的反击函数
void FightBack(CGaren * pGaren)
{
....// 表现反击动作的代码
pGaren->Hurted(m_nPower/2);
}
// 反击瑞兹的反击函数
void FightBack(CRyze * pRyze)
{
....// 表现反击动作的代码
pRyze->Hurted(m_nPower/2);
}
};
有 n 种英雄, CYi 类中就会有 n 个 Attack 成员函数,以及 n 个 FightBack
成员函数。对于其他类也如此。
如果游戏版本升级,增加了新的英雄寒冰艾希 CAshe,则程序改动较大。所有的类都需要增加两个成员函数:
void Attack(CAshe * pAshe);
void FightBack(CAshe * pAshe);
复制代码这样工作量是非常大的!!非常的不人性,所以这种设计方式是非常的不好!
用多态的方式去实现,就能得知多态的优势了,那么上面的栗子改成多态的方式如下:
// 基类
class CHero
{
public:
virtual void Attack(CHero *pHero){}
virtual voidFightBack(CHero *pHero){}
virtual void Hurted(int nPower){}
protected:
int m_nPower ; //代表攻击力
int m_nLifeValue ; //代表生命值
};
// 派生类 CYi:
class CYi : public CHero {
public:
// 攻击函数
void Attack(CHero * pHero)
{
.... // 表现攻击动作的代码
pHero->Hurted(m_nPower); // 多态
pHero->FightBack(this); // 多态
}
// 减少自身生命值
void Hurted(int nPower)
{
... // 表现受伤动作的代码
m_nLifeValue -= nPower;
}
// 反击函数
void FightBack(CHero * pHero)
{
....// 表现反击动作的代码
pHero->Hurted(m_nPower/2); // 多态
}
};
如果增加了新的英雄寒冰艾希 Ashe,只需要编写新类CAshe,不再需要在已有的类里专门为新英雄增加:
void Attack( CAshe * pAshe) ;
void FightBack(CAshe * pAshe) ;
复制代码所以已有的类可以原封不动,那么使用多态的特性新增英雄的时候,可见改动量是非常少的。
多态使用方式:
void CYi::Attack(CHero * pHero)
{
pHero->Hurted(m_nPower); // 多态
pHero->FightBack(this); // 多态
}
CYi yi;
CGaren garen;
CLeesin leesin;
CEzreal ezreal;
yi.Attack( &garen ); //(1)
yi.Attack( &leesin ); //(2)
yi.Attack( &ezreal ); //(3)
根据多态的规则,上面的(1),(2),(3)进入到 CYi::Attack 函数后 ,分别调用:
CGaren::Hurted
CLeesin::Hurted
CEzreal::Hurted
「多态」的关键在于通过基类指针或引用调用一个虚函数时,编译时不能确定到底调用的是基类还是派生类的函数,运行时才能确定。
我们用 sizeof来运算有有虚函数的类和没虚函数的类的大小,会是什么结果呢?
class A
{
public:
int i;
virtual void Print() { } // 虚函数
};
class B
{
public:
int n;
void Print() { }
};
int main()
{
cout << sizeof(A) << ","<< sizeof(B);
return 0;
}
在32位机子,执行的结果:
8,4
从上面的结果,可以发现有虚函数的类,多出了 4 个字节,在 32 位机子上指针类型大小正好是 4 个字节,这多出 4 个字节的指针有什么作用呢?
每一个有「虚函数」的类(或有虚函数的类的派生类)都有一个「虚函数表」,该类的任何对象中都放着虚函数表的指针。「虚函数表」中列出了该类的「虚函数」地址。
多出来的 8 个字节就是用来放「虚函数表」的地址。
简单地说,每一个含有虚函数(无论是其本身的,还是继承而来的)的类都至少有一个与之对应的虚函数表,其中存放着该类所有的虚函数对应的函数指针。例:
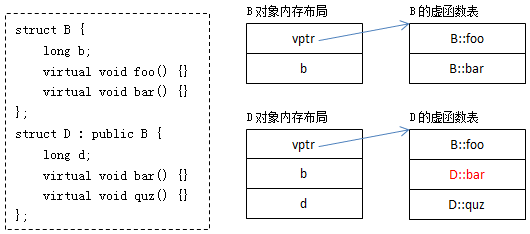
其中:
B的虚函数表中存放着B::foo和B::bar两个函数指针。
D的虚函数表中存放的既有继承自B的虚函数B::foo,又有重写(override)了基类虚函数B::bar的D::bar,还有新增的虚函数D::quz。
从编译器的角度来说,B的虚函数表很好构造,D的虚函数表构造过程相对复杂。下面给出了构造D的虚函数表的一种方式(仅供参考):
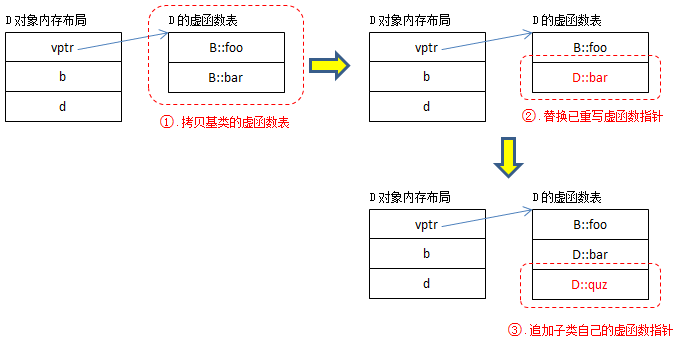
提示:该过程是由编译器完成的,因此也可以说:虚函数替换过程发生在编译时。
以下面的程序为例:
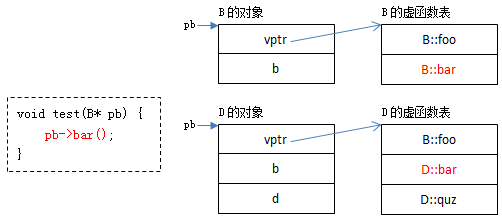
编译器只知道b是B*类型的指针,并不知道它指向的具体对象类型 :pb可能指向的是B的对象,也可能指向的是D的对象。
但对于“pb->bar()”,编译时能够确定的是:此处operator->的另一个参数是B::bar(因为pb是B*类型的,编译器认为bar是B::bar),而B::bar和D::bar在各自虚函数表中的偏移位置是相等的。
无论pb指向哪种类型的对象,只要能够确定被调函数在虚函数中的偏移值,待运行时,能够确定具体类型,并能找到相应vptr了,就能找出真正应该调用的函数。
提示:虚函数指针中的ptr部分为虚函数表中的偏移值(以字节为单位)加1。
B::bar是一个虚函数指针, 它的ptr部分内容为9,它在B的虚函数表中的偏移值为8(8+1=9)。
当程序执行到“pb->bar()”时,已经能够判断pb指向的具体类型了:
如果pb指向B的对象,可以获取到B对象的vptr,加上偏移值8((char*)vptr + 8),可以找到B::bar。
如果pb指向D的对象,可以获取到D对象的vptr,加上偏移值8((char*)vptr + 8) ,可以找到D::bar。
如果pb指向其它类型对象...同理...
当一个类继承多个类,且多个基类都有虚函数时,子类对象中将包含多个虚函数表的指针(即多个vptr),例:
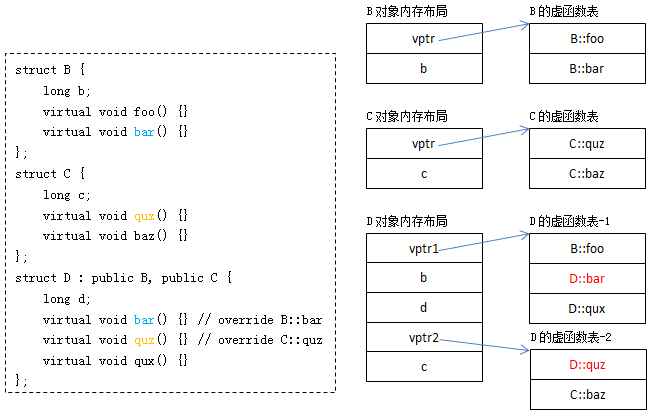
其中:D自身的虚函数与B基类共用了同一个虚函数表,因此也称B为D的主基类(primary base class)。
虚函数替换过程与前面描述类似,只是多了一个虚函数表,多了一次拷贝和替换的过程。
虚函数的调用过程,与前面描述基本类似,区别在于基类指针指向的位置可能不是派生类对象的起始位置,以如下面的程序为例:
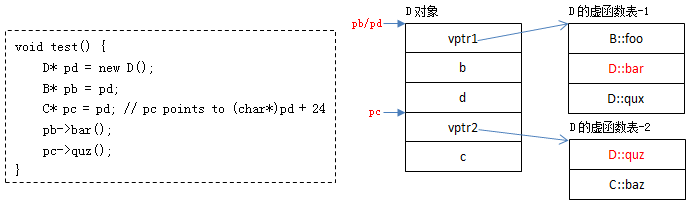
析构函数是在删除对象或退出程序的时候,自动调用的函数,其目的是做一些资源释放。
那么在多态的情景下,通过基类的指针删除派生类对象时,通常情况下只调用基类的析构函数,这就会存在派生类对象的析构函数没有调用到,存在资源泄露的情况。
看如下的例子:
// 基类
class A
{
public:
A() // 构造函数
{
cout << "construct A" << endl;
}
~A() // 析构函数
{
cout << "Destructor A" << endl;
}
};
// 派生类
class B : public A
{
public:
B() // 构造函数
{
cout << "construct B" << endl;
}
~B()// 析构函数
{
cout << "Destructor B" << endl;
}
};
int main()
{
A *pa = new B();
delete pa;
return 0;
}
输出结果:
construct A
construct B
Destructor A
从上面的输出结果可以看到,在删除 pa指针对象时,B 类的析构函数没有被调用。
解决办法:把基类的析构函数声明为virtual
可以这样解释它:如果基类当中定义了虚析构函数,那么基类的虚函数表当中就会有一个基类的虚析构函数的入口指针,指向的是基类的虚析构函数,派生类的虚函数表当中也会产生一个派生类的虚析构函数的入口指针,指向的是派生类的虚析构函数,这个时候使用基类的指针指向派生类的对象,delete掉基类指针,就会通过指向的基类的对象找到基类的虚函数表指针,从而找到虚函数表,在虚函数表中找到派生类的虚析构函数,从而使得派生类的析构函数得以执行,派生类的析构函数执行之后系统会自动执行父类的虚析构函数。即整个执行过程是:
基类的构造函数;
派生类的构造函数;
virtual 不进行声明;// 基类
class A
{
public:
A()
{
cout << "construct A" << endl;
}
virtual ~A() // 虚析构函数
{
cout << "Destructor A" << endl;
}
};
输出结果:
construct A
construct B
Destructor B
Destructor A
所以要养成好习惯:
纯虚函数: 没有函数体的虚函数
class A
{
public:
virtual void Print( ) = 0 ; //纯虚函数
private:
int a;
};
包含纯虚函数的类叫抽象类
- 抽象类只能作为基类来派生新类使用,不能创建抽象类的对象
- 抽象类的指针和引用可以指向由抽象类派生出来的类的对象
A a; // 错,A 是抽象类,不能创建对象
A * pa ; // ok,可以定义抽象类的指针和引用
pa = new A ; // 错误, A 是抽象类,不能创建对象
标签:区别 说明 输出 机制 为什么 思路 存在 很多 内存布局
原文地址:https://www.cnblogs.com/lsyy2020/p/14826538.html