标签:ocr 实例化 部分 element strong res 等于 ken 源码
String是代表字符串的类,本身是一个最终类,使用final修饰,不能被继承。
方式一:直接赋值法
String str1 = "hello";
方式二:创建法
String str2 = new String("hello");
方式三:创建一个字符数组ch,new String ( ch )
char chs[] = {‘h‘,‘e‘,‘l‘,‘l‘,‘l‘,‘o‘}; String str3 = new String(chs);
字符串在内存中是以字符数组的形式来存储的。
在此之前我们要先引入一个概念 常量是在编译期存放在常量池中的。
我们常说的常量池,就是指方法区中的运行时常量池。
运行时常量池在jvm内存结构的方法区中。
因为常量是编译期可以得知的,在编译期会执行全是常量的计算式(编译器优化),把常量以及计算结果值(也是常量)存放在常量池中,减轻运行期的负担。
方法调用和new是编译期无法得知的,不会放在常量池,而是在运行期放在堆内存中。
接下来我们通过一系列的练习来熟悉 字符串常量池以及 字符串类型数据在内存中的存放。
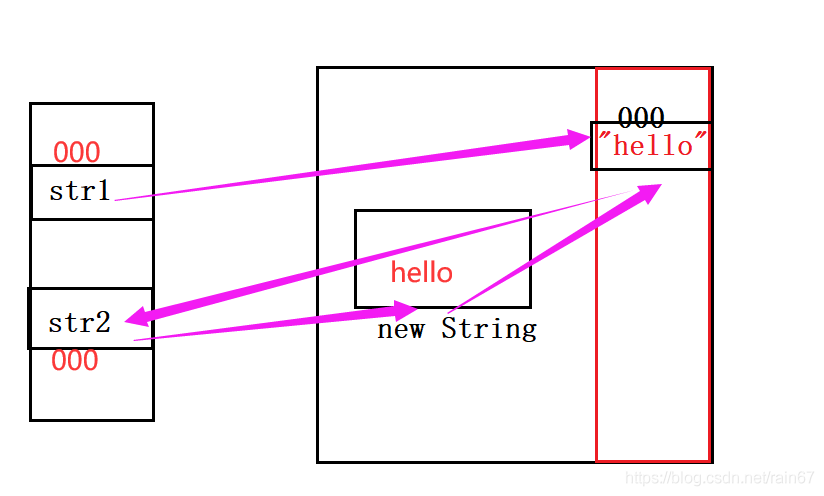
public static void main(String[] args) { String str1 = "hello"; String str2 = new String("hello"); System.out.println(str1 == str2); String str3 = "hello"; System.out.println(str1 == str3); }
以上代码得运行结果是什么呢?
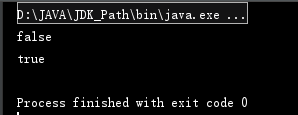
这个时候大家会不会疑惑 这不都是hello吗?怎么会不相同呢? 不要着急,接下来我来给画图讲解一下
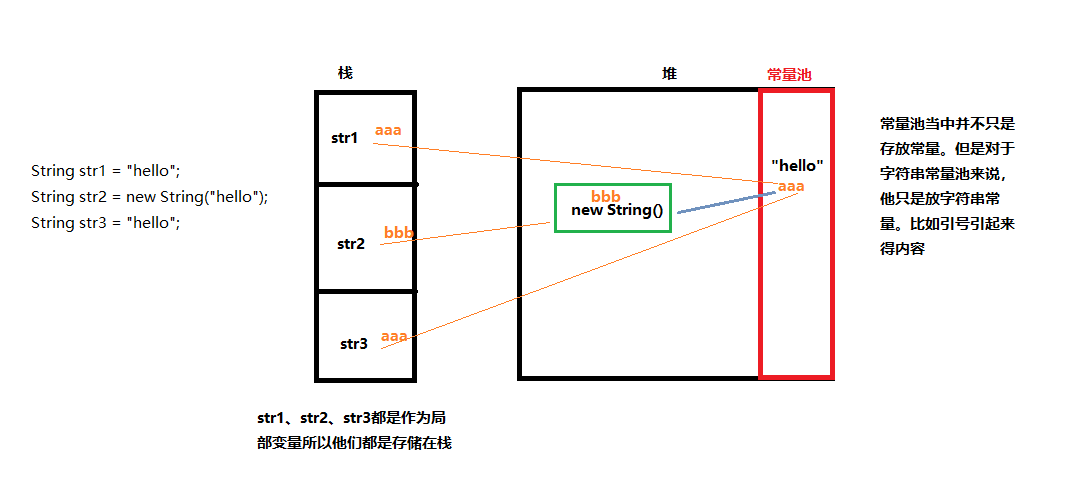
注:此为String得源码
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; /** Cache the hash code for the string */ private int hash; // Default to 0 /** use serialVersionUID from JDK 1.0.2 for interoperability */ private static final long serialVersionUID = -6849794470754667710L; /** * Class String is special cased within the Serialization Stream Protocol. * * A String instance is written into an ObjectOutputStream according to * <a href="{@docRoot}/../platform/serialization/spec/output.html"> * Object Serialization Specification, Section 6.2, "Stream Elements"</a> */ private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0]; /** * Initializes a newly created {@code String} object so that it represents * an empty character sequence. Note that use of this constructor is * unnecessary since Strings are immutable. */ public String() { this.value = "".value; } /** * Initializes a newly created {@code String} object so that it represents * the same sequence of characters as the argument; in other words, the * newly created string is a copy of the argument string. Unless an * explicit copy of {@code original} is needed, use of this constructor is * unnecessary since Strings are immutable. * * @param original * A {@code String} */ public String(String original) { this.value = original.value; this.hash = original.hash; } }
再看另一组练习
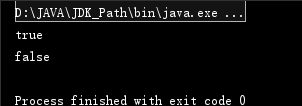
public static void main(String[] args) { String str1 = "hello"; String str2 = "hel"+"lo"; System.out.println(str1==str2); String str3 = new String("hel")+"lo"; System.out.println(str1==str3); }
请判断两次打印结果是什么?
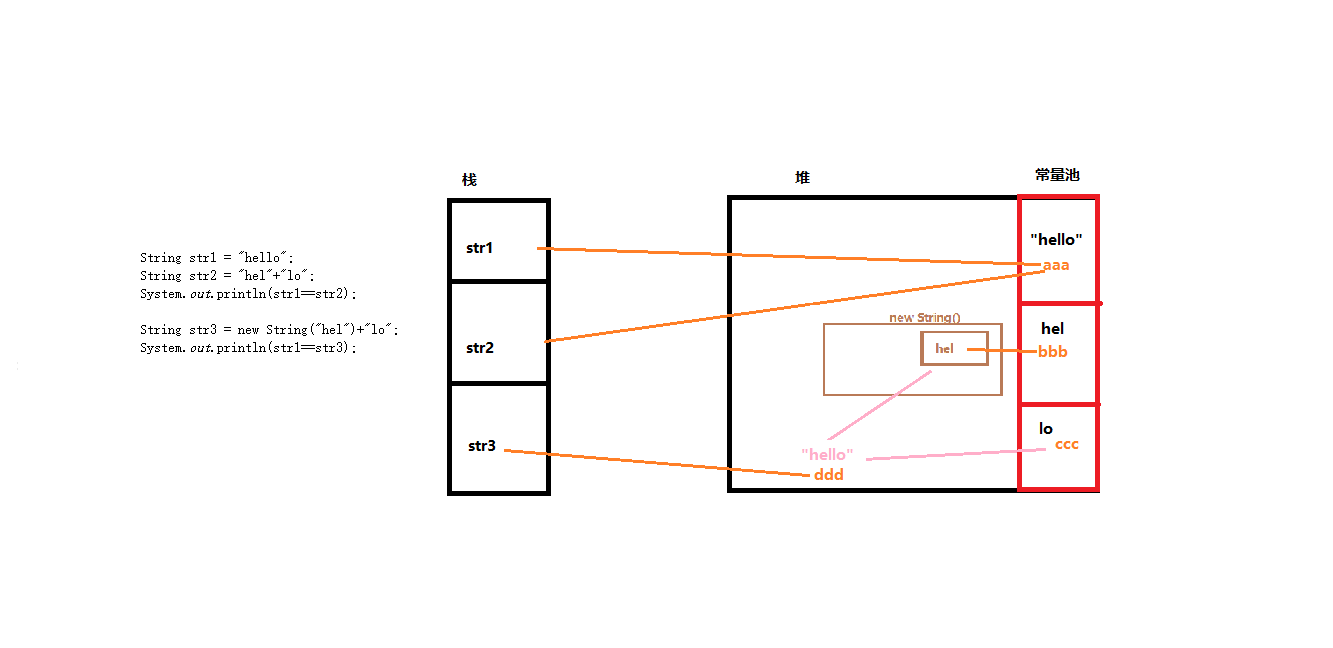
?str3 首先new 了一个String(“hel”)对象,在堆中开辟一块空间,这个对象中的"hel"同时存放在常量池中,之后又在常量池中开辟一块空间存放 “lo”。两块部分之间的"+",将 String 的对象 与常量池中的 "lo"结合在堆中再次开辟一块新的空间,这块内存中的val ==“hello”,str3指向的是合并之后的对象 ,地址为ddd.
??在上面的例子中, String类的两种实例化操作, 直接赋值和 new 一个新的 String.
String类的设计使用了共享设计模式
在JVM底层实际上会自动维护一个对象池(字符串常量池)
? ?如果现在采用了直接赋值的模式进行String类的对象实例化操作,那么该实例化对象(字符串内容)将自动保存到这个对象池之中.
?? 如果下次继续使用直接赋值的模式声明String类对象,此时对象池之中如若有指定内容,将直接进行引用
?? 如若没有,则开辟新的字符串对象而后将其保存在对象池之中以供下次使用
理解 “池” (pool)
?? “池” 是编程中的一种常见的, 重要的提升效率的方式, 我们会在未来的学习中遇到各种 “内存池”, “线程池”, “数据库连接池” …然而池这样的概念不是计算机独有, 也是来自于生活中.
String str = new String("hello");
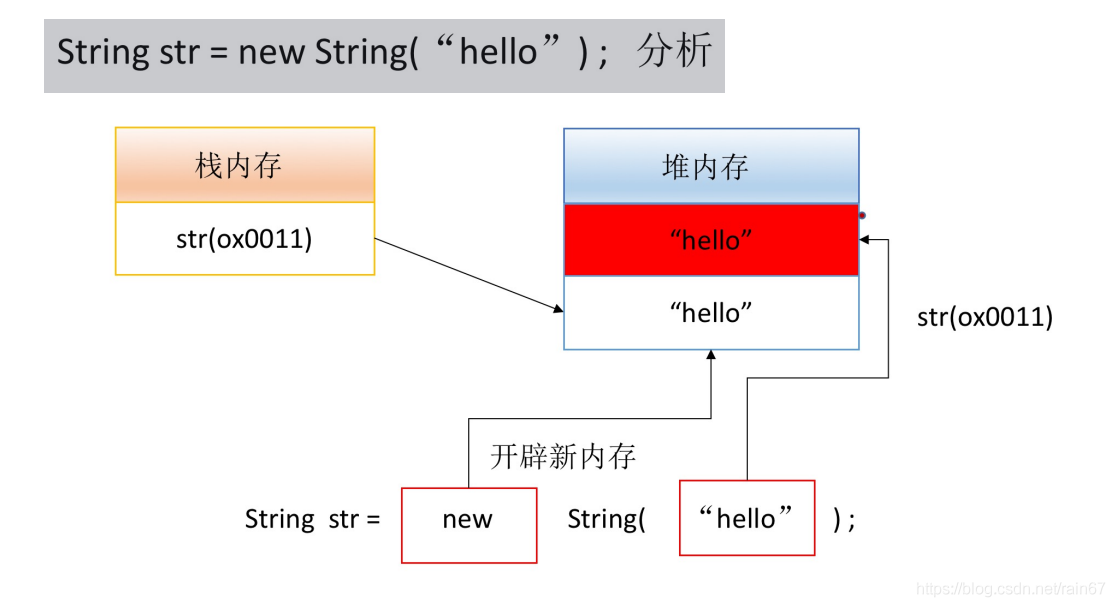
这样的做法有两个缺点:
1.??如果使用String构造方法就会开辟两块堆内存空间,并且其中一块堆内存将成为垃圾空间(字符串常量 “hello” 也是一个匿名对象, 用了一次之后就不再使用了, 就成为垃圾空间, 会被 JVM 自动回收掉).
2.??字符串共享问题. 同一个字符串可能会被存储多次, 比较浪费空间.
String str1 = "hello"; String str2 = new String("hello").intren();
传入构造方法的字符串在字符串常量池中是否存在,如果有的话,就把常量池中的引用传给当前的引用类型变量。
public static void main(String[] args) { String str = "hello" ; str = str + " world" ; str += "!!!" ; System.out.println(str); }
?对于这种代码,乍一看我们以为成功的将str 每次与其他的字符串拼接,但是这样是不可以的, str 原来指向的是"hello",但是 在与" world"拼接之后,又会产生一个新的对象"helll world",再次拼接一个"!!!",那么又会产生一个新的对象"hello world!!!",在内存中就会产生多个对象。
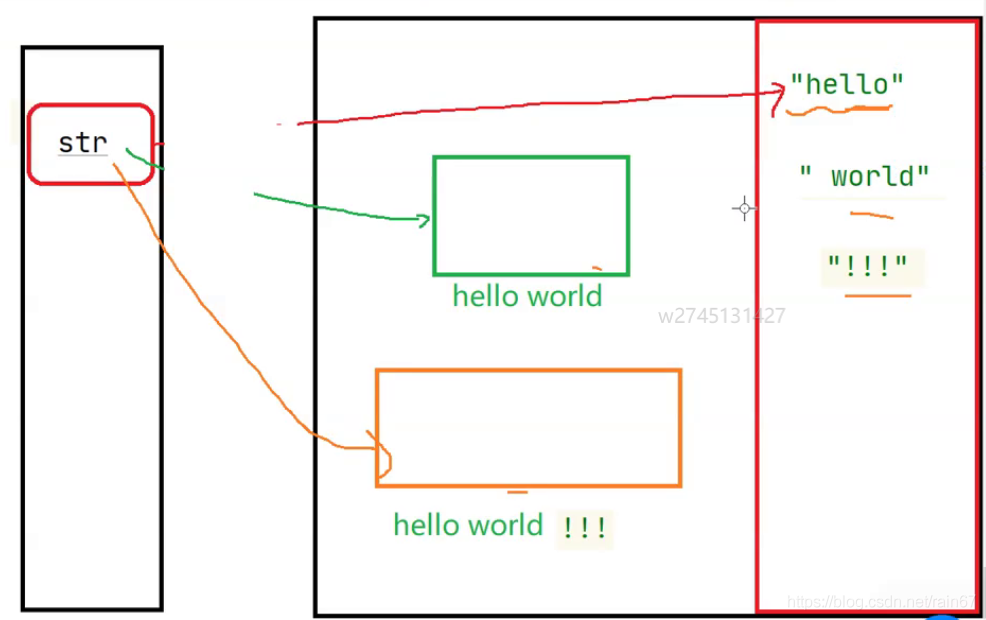
我们最后需要的是"hello world!!!",但是却开辟了5块内存空间。
如果在一个循环中拼接,那么会开辟更多的内存空间!!
所以这样的代码是极为不可取的!!!
那么如何拼接呢,具体在之后的StringBuff、StringBuilder中介绍。
?StringBuffer 和 StringBuilder 又是一种新的字符串类型。
??通常来讲String的操作比较简单,但是由于String的不可更改特性,为了方便字符串的修改,提供 StringBuffer 和 StringBuilder 类。
??StringBuffer 和 StringBuilder 在功能上大部分是相同的,在这里我们着重介绍 StringBuffer.
(1)append 方法
??在String中使用"+"来进行字符串连接,但是这个操作在StringBuffer类中需要更改为append()方法。
??String和StringBuffer最大的区别在于:String的内容无法修改,而StringBuffer的内容可以修改。频繁修改字符串的情况考虑使用 StingBuffer。
public static void main(String[] args) { StringBuffer sb = new StringBuffer(); sb.append("a"); sb.append("b"); sb.append("c"); System.out.println(sb); }

最后返回的是 this,在字符串本身拼接字符串。同时StringBuffer 有自己重写的 toString 方法,可以直接进行打印。
//我们将此代码进行反编译
public static void main(String[] args) { String str1 = "abc"; String str2 = "def"; String str3 = str1+str2; System.out.println(str3); }
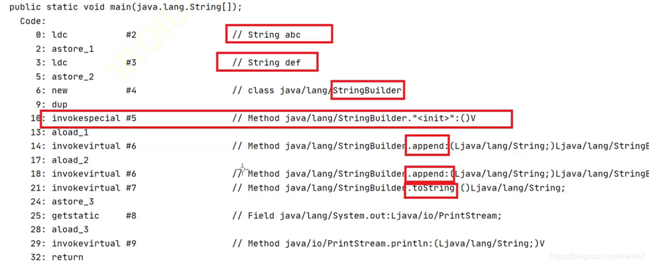
在编译的过程中,我们发现StringBuilder.append 方法的出现;说明:String 的“+” 拼接,会被底层优化为一个 StringBuilder ,拼接的时候会用到 append 方法,也就是说String得“+”拼接就是StringBuilder。
String 和 StringBuilder 及 StringBuffer 的区别
String 进行拼接时,底层会被优化为StringBuilder
String的拼接会产生临时对象,但是后两者每次都只是返回当前对象的引用。
String的内容不可修改,StringBuffer与StringBuilder的内容可以修改.
StringBuffer采用同步处理,属于线程安全操作;而StringBuilder未采用同步处理,属于线程不安全操作 synchronized
StringBuilder得源码:
@Override public StringBuilder append(String str) { super.append(str); return this; }
StringBuffer得源码:
@Override public synchronized StringBuffer append(String str) { toStringCache = null; super.append(str); return this; }
Java 基本类型的包装类的大部分都实现了常量池技术,即Byte,Short,Integer,Long,Character,Boolean;这5种包装类默认创建了数值[-128,127]的相应类型的缓存数据,但是超出此范围仍然会去创建新的对象。?两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。
/** *此方法将始终缓存-128到127(包括端点)范围内的值,并可以缓存此范围之外的其他值。 */ public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }
public static Double valueOf(double d) { return new Double(d); }
Integer i1 = 33; Integer i2 = 33; System.out.println(i1 == i2);// 输出true Integer i11 = 333; Integer i22 = 333; System.out.println(i11 == i22);// 输出false 因为333 不在-128到127之间,所以他不再常量池当中, 每次都是进行得new 在堆当中创建对象得操作,==相当于比较他们得引用地址,所以为false Double i3 = 1.2; Double i4 = 1.2; System.out.println(i3 == i4);// 输出false double没有常量池 所以都是在内存中开辟一块空间。所以他们得应用地址不同
Integer i1 = 40; Integer i2 = 40; Integer i3 = 0; Integer i4 = new Integer(40); Integer i5 = new Integer(40); Integer i6 = new Integer(0); System.out.println("i1=i2 " + (i1 == i2)); //true System.out.println("i1=i2+i3 " + (i1 == i2 + i3)); //true System.out.println("i1=i4 " + (i1 == i4)); //false System.out.println("i4=i5 " + (i4 == i5)); //fasle System.out.println("i4=i5+i6 " + (i4 == i5 + i6)); //true 语句i4 == i5 + i6,因为+这个操作符不适用于Integer对象,首先i5和i6进行自动拆箱操作,进行数值相加,即i4 == 40。然后Integer对象无法与数值进行直接比较,所以i4自动拆箱转为int值40,最终这条语句转为40 == 40进行数值比较。 System.out.println("40=i5+i6 " + (40 == i5 + i6)); //true
JAVA String介绍、常量池及String、StringBuilder和StringBuffer得区别. 以及8种基本类型的包装类和常量池得简单介绍
标签:ocr 实例化 部分 element strong res 等于 ken 源码
原文地址:https://www.cnblogs.com/it1042290135/p/14867886.html