标签:下载 快速 神经网络 nbsp 没有 blog alt png 教师
课程:《Python程序设计》
班级:2013
姓名:陈鑫
学号:20201316
实验教师:王志强
实验日期:2021年6月15日
必修/选修: 公选课
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。 课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
个人对爬虫更感兴趣一些,所以这次就选择了爬虫作为大作业。
本次实验我爬取了一个视频网站的视频和一个图片网站的图片,之前一直在爬一些网站的文字,就按学长教的那样爬豆瓣的电影top250的名字,但是我发现以我的能力爬不来4399的游戏名字或者bilibili的视频标题,爬下来的要么是乱码要么啥都没有,我也搞不懂啥问题,后来就只成功爬下来起点中文网的小说名字,然后再看视频学习怎么爬视频和图片。而且爬取的都是一些反爬非常弱的网站。
目标网站:https://www.ku6.com/detail/69
工具:pycharm Firefox
导入requests 和 json 模块
很简单的一个步骤,按f12再刷新页面很容易就找到了,如图:

最好是伪装一下,图中数据一行输出了,看起来有点麻烦:
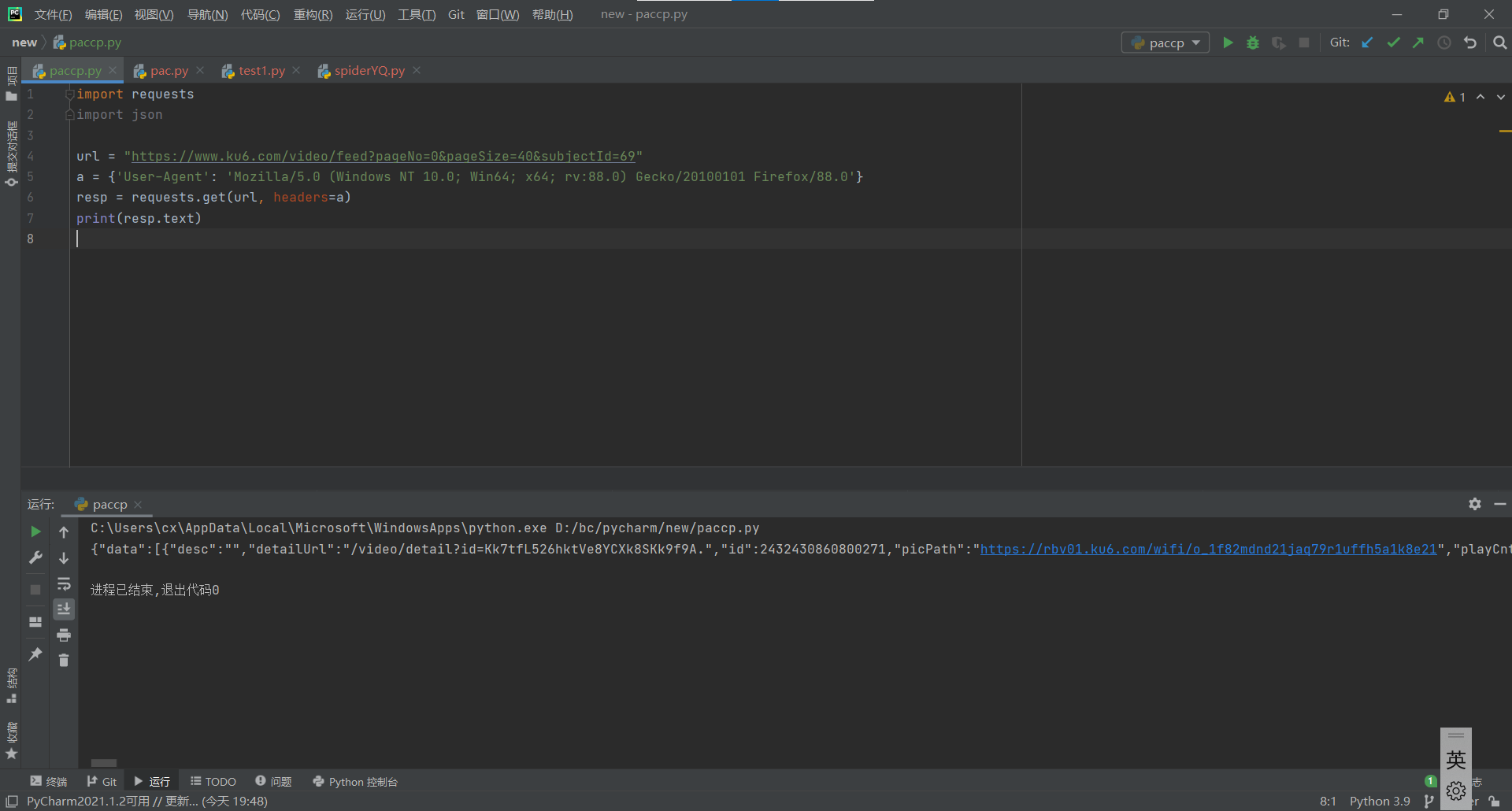
先使用json.loads将字符串类型数据转化成字典类型,这样查找起来非常方便快速
观察数据,然后使用for循环将数据中的视频标题和地址(点开就能播放的那种)提取出来,用于下载和保存。
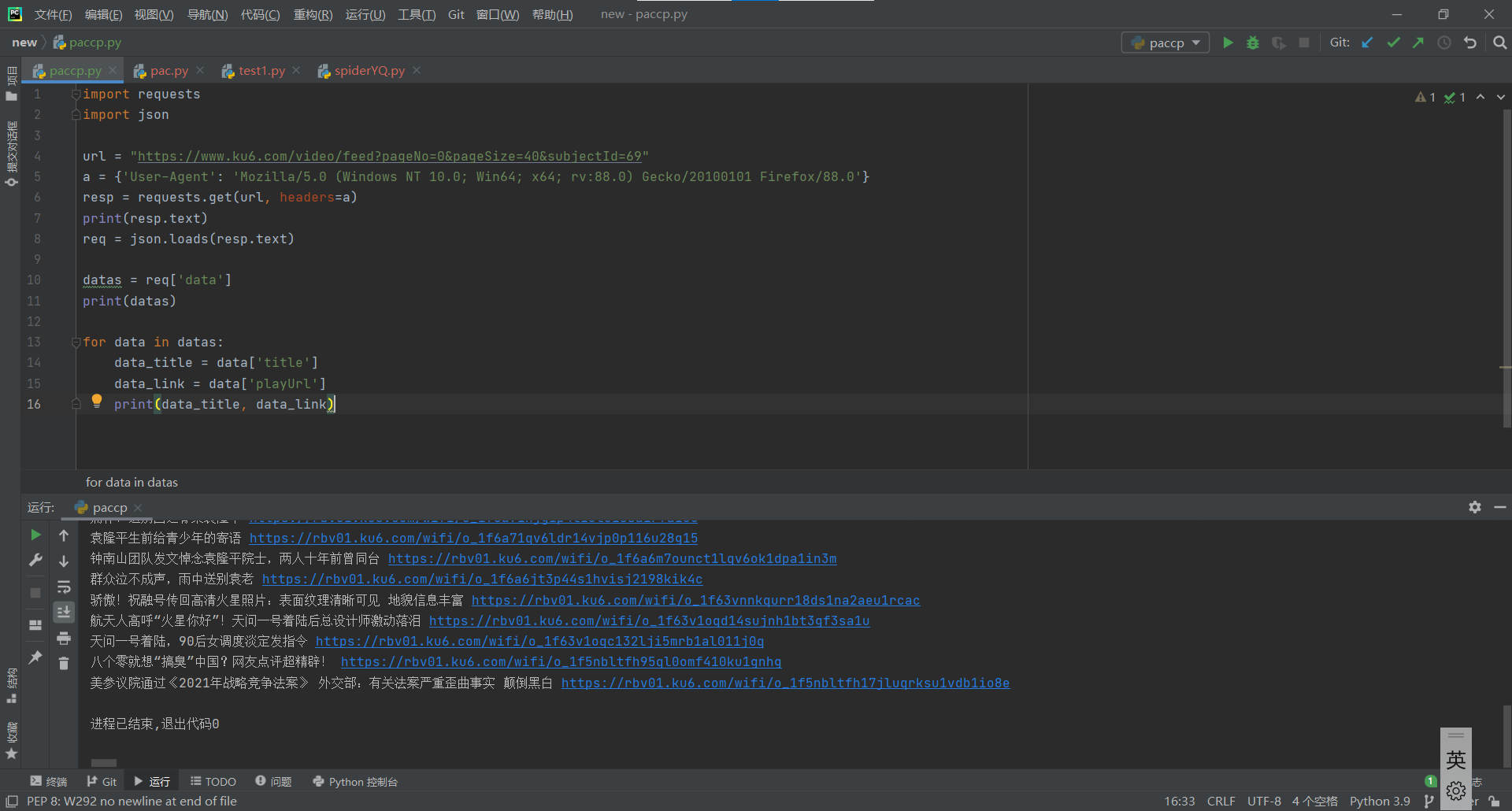
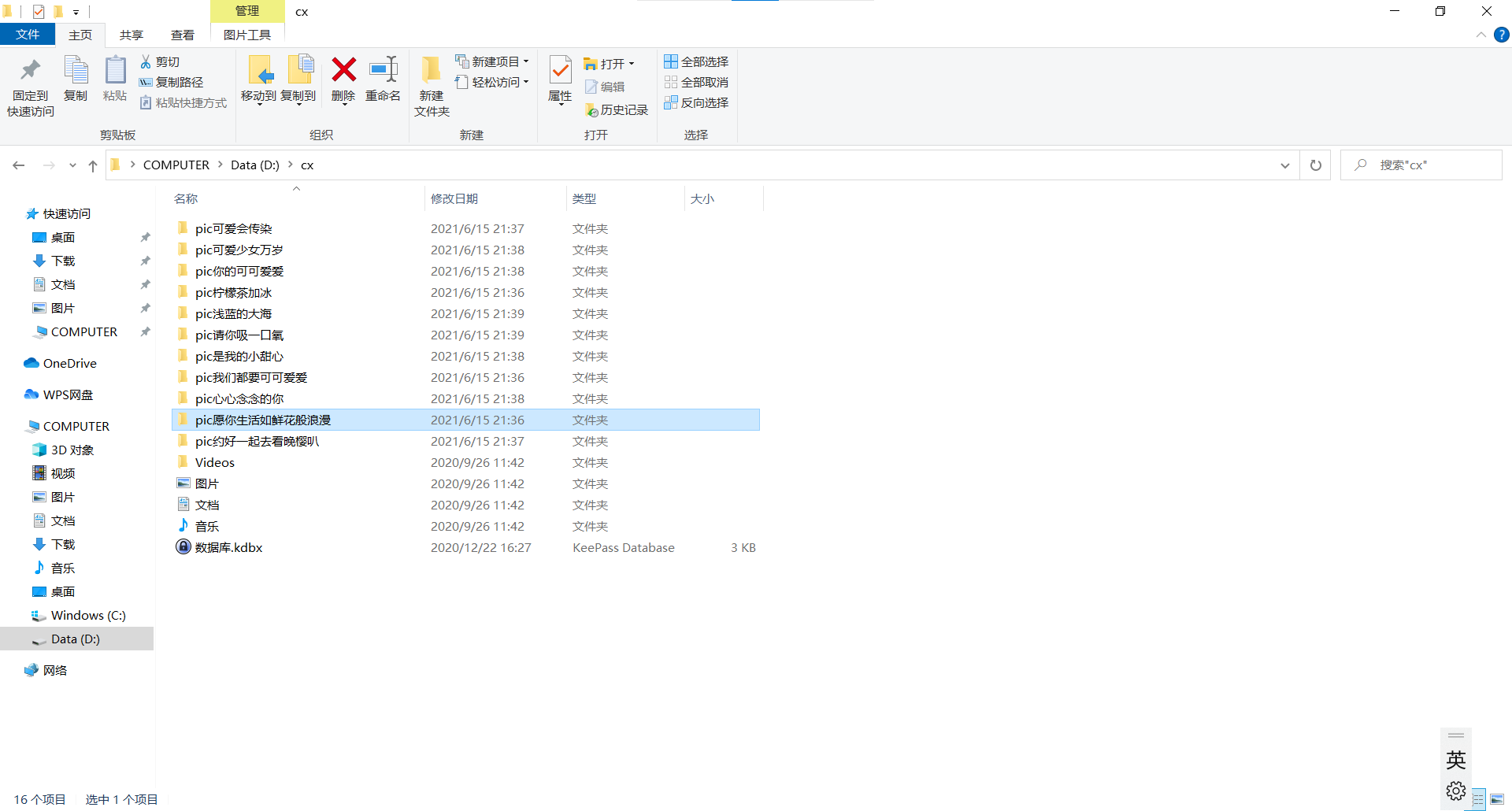
使用文件操作将刚刚提取的数据保存在本地,只要写清楚本地目录,应该是都能保存好的,我是直接在python文件所在目录下创建了一个video文件夹然后保存在里面:
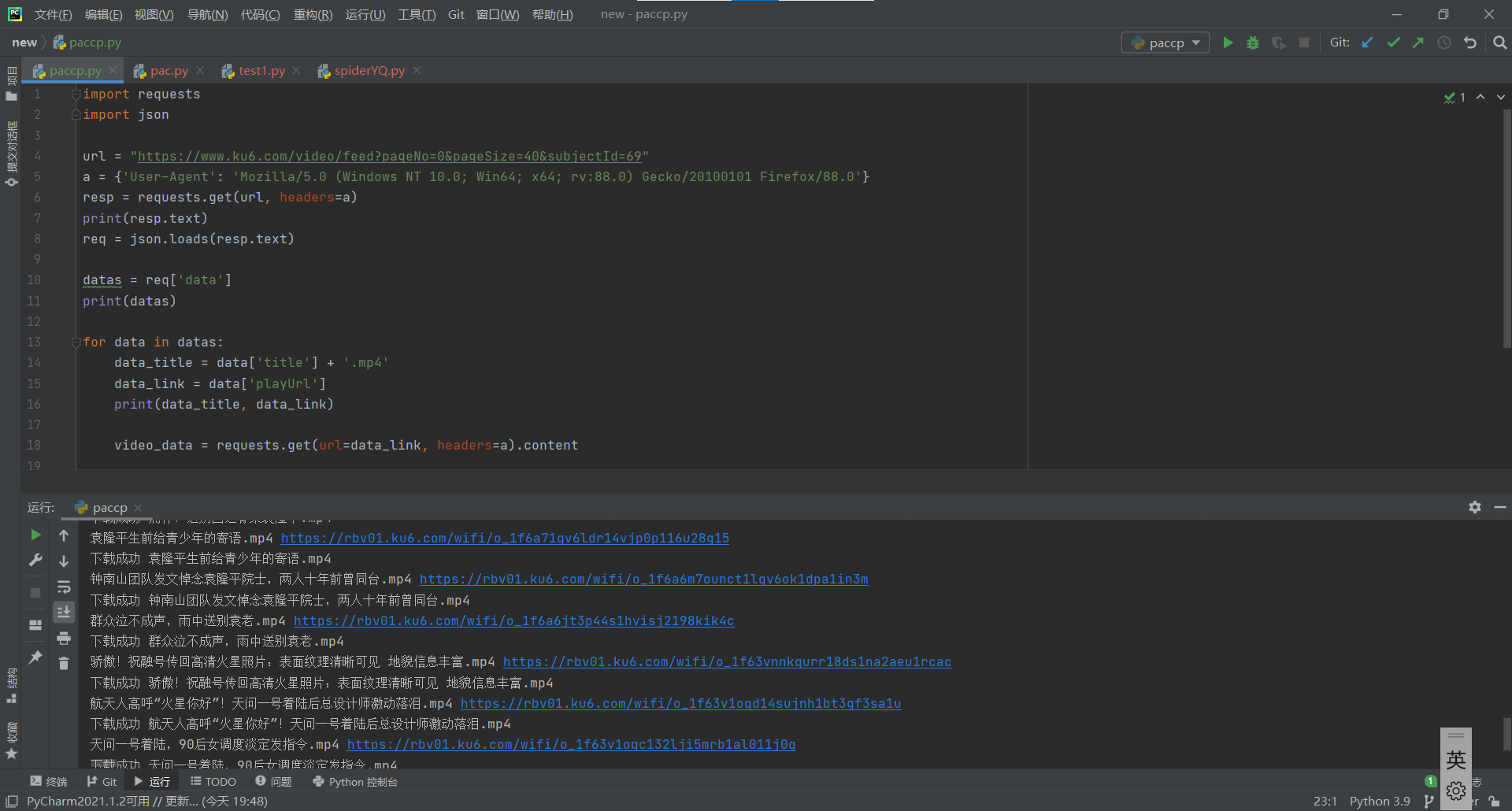
里面有三个视频播放不了,不知道是为啥。
对图片也比较感兴趣,就尝试爬了图片:
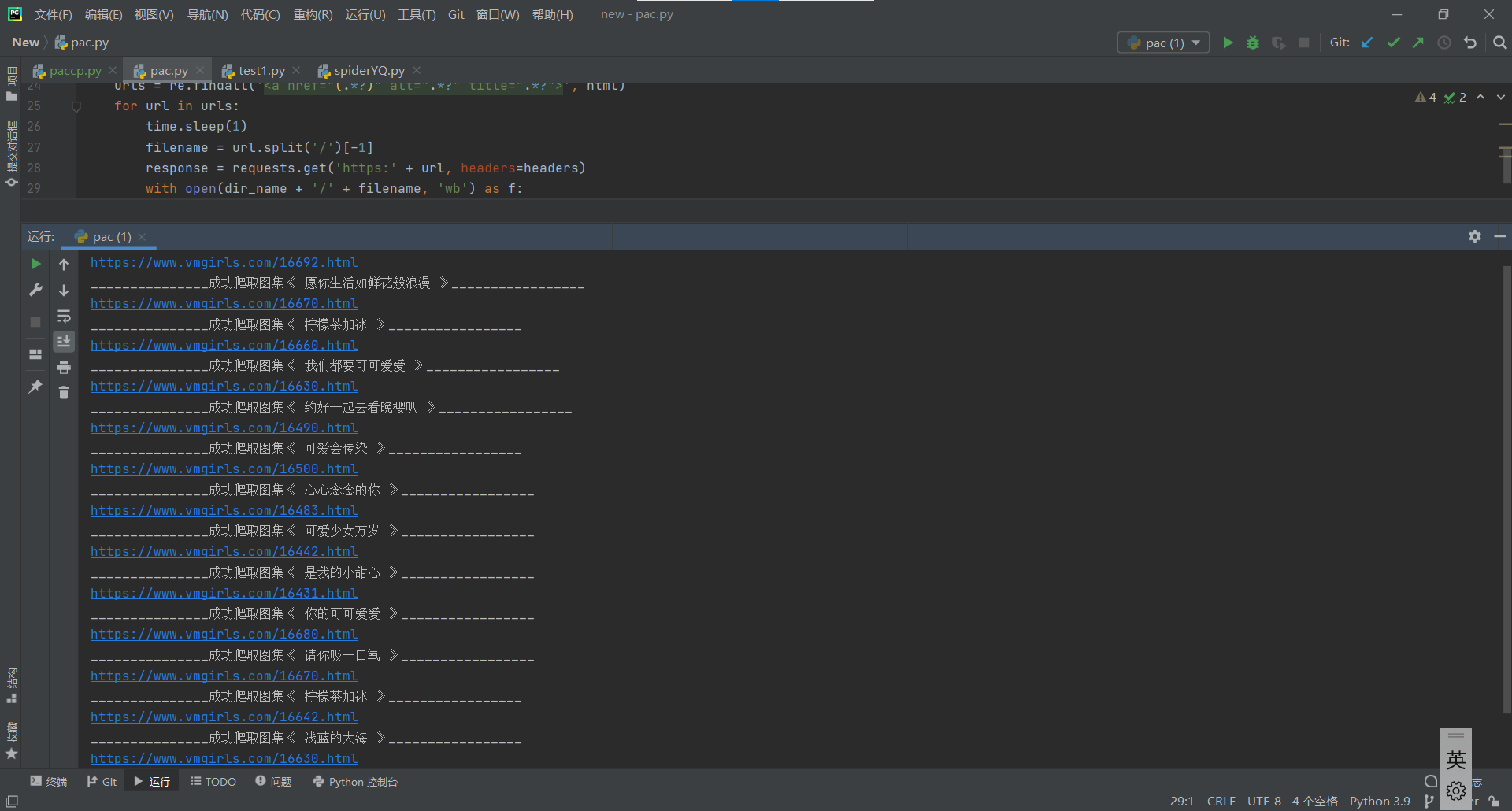
视频:https://gitee.com/cx20201316/pythonstart1/blob/master/paccp.py
图片:https://gitee.com/cx20201316/pythonstart1/blob/master/pac.py
问题1:在爬取视频的时候提示TypeError,如何解决
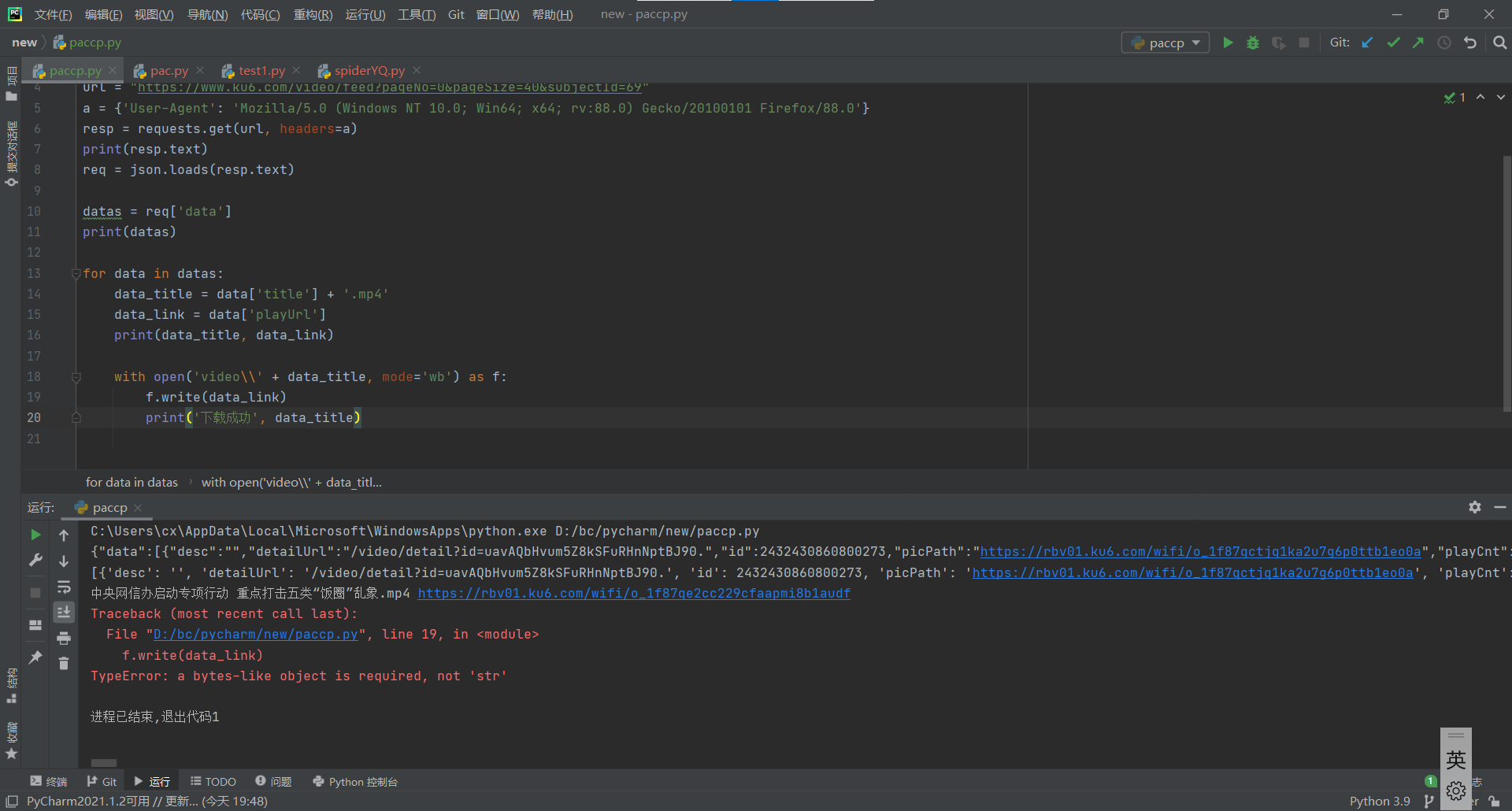
问题1解决方案:经查询得知视频数据属于二进制数据,要先转换数据类型才行,可以使用video_data = requests.get(url=data_link, headers=a).content进行转换。
问题2:在爬取12306的车票信息时候,使用json.loads()时总是报错。如图:
问题2解决方案:经查询得json数据格式问题。因为爬到的数据有些不是json格式,所以报错。解决方法是构造get请求参数param,把不合格数据筛掉。但是还是不太明白
本次python选修课总体上来感觉还是非常不错的,因为之前有一些python的基础,所以相比其他零基础的同学,学的还是比较轻松的,当然也因此一开始时没有认真听讲,说实话感觉错过了老师讲的很多细节。王老师讲课的方式感觉和c语言老师的非常不一样,王老师讲的更有趣,更生动一些,相比起来,我更喜欢王老师这种讲课方式。之后的课程感觉难度就上来了,之前没听到的细节可能就影响到了之后的听课,所以有时候会有点听不明白。但后面通过老师发在云班课和网上的资源还是能够弄懂的。四个实验感觉上来说,前两个还能理解很多,后面的就有些难理解,大部分都停留在知其然的层面,但是那些爬虫,GUI,游戏等编程技术还是让我非常感兴趣的,也让我感受到了python的功能强大与方便,希望以后还有更多时间来学习python。最后想给王老师提个小小的建议(如果能看到的话):在实验室上课的时候,没抢到前面的位置,坐后面就有点听不清了,希望那个话筒能大点声音。总之,非常感谢王老师这学期的悉心教导!
视频地址:https://www.bilibili.com/video/BV1go4y127TQ?t=565&p=4
20201316 2020-2021-2 《Python程序设计》实验四报告
标签:下载 快速 神经网络 nbsp 没有 blog alt png 教师
原文地址:https://www.cnblogs.com/cxzuishuai/p/14887612.html