标签:spatial 执行 who space 特征提取 中心 复杂 ali tar
https://arxiv.org/pdf/2103.11744.pdf
问题:
当视频包含大量运动时,传统方法很容易带来不连贯的结果或伪影。和抖动 和大的运动。
解决:
1)
named U-shaped residual dense network with 3D convolution (U3D-RDN) for fine implicit motion estimation and motion compensation (MEMC) as well as coarse spatial feature extraction
U 形残差密集网络的新模块,带有 3D 卷积(U3D-RDN),用于精细的隐式运动估计和运动补偿(MEMC)以及粗略的空间特征提取。
2)
we present a new Multi-Stage Communicated Upsampling (MSCU) module to make full use of the intermediate results of upsampling for guiding the VSR.
我们提出了一个新的多级通信上采样 (MSCU) 模块,以充分利用上采样的中间结果来指导 VSR。
a novel dual subnet is devised to aid the training of our DSMC, whose dual loss helps to reduce the solution space as well as enhance the generalization ability.
设计了一个新颖的双子网来帮助我们 DSMC 的训练,其双损失有助于减少解决方案空间并增强泛化能力。
运动补偿(MEMC)
我们提出了一种具有双子网和多级通信上采样 (DSMC) 的新型视频超分辨率网络,以最大限度地传输具有大运动的视频的各种决定性信息。DSMC 为每个 SR 接收一个中心 LR 帧及其相邻帧。在对输入帧进行从粗到细的空间特征提取后,为 DSMC 设计了具有 3D 卷积的 U 形残差密集网络(U3D-RDN)。它可以对输入特征进行编码,在编码空间上实现精细的隐式 MEMC 和粗略的空间特征提取,并降低计算复杂度。然后 U3D-RDN 通过子像素卷积上采样层解码特征。再经过精细的空间特征提取,提出了多阶段通信上采样(MSCU)模块来将上采样分解为多个子任务。它借助每个子任务的 VSR 结果进行特征校正,从而充分利用上采样的中间结果进行 VSR 指导。最后,提出了一个双子网,用于模拟自然图像的退化,并计算退化的 VSR 结果与原始 LR 帧之间的双损失,以辅助 DSMC 的训练。
我们提出了一种具有双子网和多级通信上采样 (DSMC) 的新型视频超分辨率网络,以最大限度地传输具有大运动的视频的各种决定性信息。
DSMC 为每个 SR 接收一个中心 LR 帧及其相邻帧。
在对输入帧进行从粗到细的空间特征提取后,为 DSMC 设计了具有 3D 卷积的 U 形残差密集网络(U3D-RDN)。
它可以对输入特征进行编码,在编码空间上实现精细的隐式 MEMC 和粗略的空间特征提取,并降低计算复杂度。
然后 U3D-RDN 通过子像素卷积上采样层解码特征。
再经过精细的空间特征提取,提出了多阶段通信上采样(MSCU)模块来将上采样分解为多个子任务。
它借助每个子任务的 VSR 结果进行特征校正,从而充分利用上采样的中间结果进行 VSR 指导。
最后,提出了一个双子网,用于模拟自然图像的退化,并计算退化的 VSR 结果与原始 LR 帧之间的双损失,以辅助 DSMC 的训练。
1)我们提出了一种用于大运动视频的超分辨率 DSMC 网络,该网络旨在最大化 VSR 过程中各种决定性信息的交流并隐式捕获运动信息。
我们的 DSMC 可以通过建议的 MSCU 模型以比其他最先进的先验知识更充分的先验知识来指导上采样过程。
同时,所提出的 U3D-RDN 模块可以从输入的视频帧中学习从粗到细的时空特征,从而有效地指导大运动的 VSR 过程。
2)我们为我们的 DSMC 提出了一个双子网,它可以模拟自然图像退化以减少解决方案空间,增强泛化能力并帮助 DSMC 更好地训练。
3)已经进行了广泛的实验来评估所提出的 DSMC。我们将它与几种最先进的方法进行比较,包括基于光流和基于 C3D 的方法。实验结果证实,DSMC 对有大运动的视频以及没有大运动的通用视频都是有效的。
4)已经对每个单独的设计进行了消融研究,以调查我们 DSMC 的有效性。我们可以发现 MSCU 对性能的影响最大,因为它可以通过多级通信恢复更多细节。U3D-RDN 对于提取运动信息也很有效。消融研究还表明,当原始损失函数在 Cb 和感知损失的不同组合下时,双子网中的损失函数会影响 DSMC 的训练。
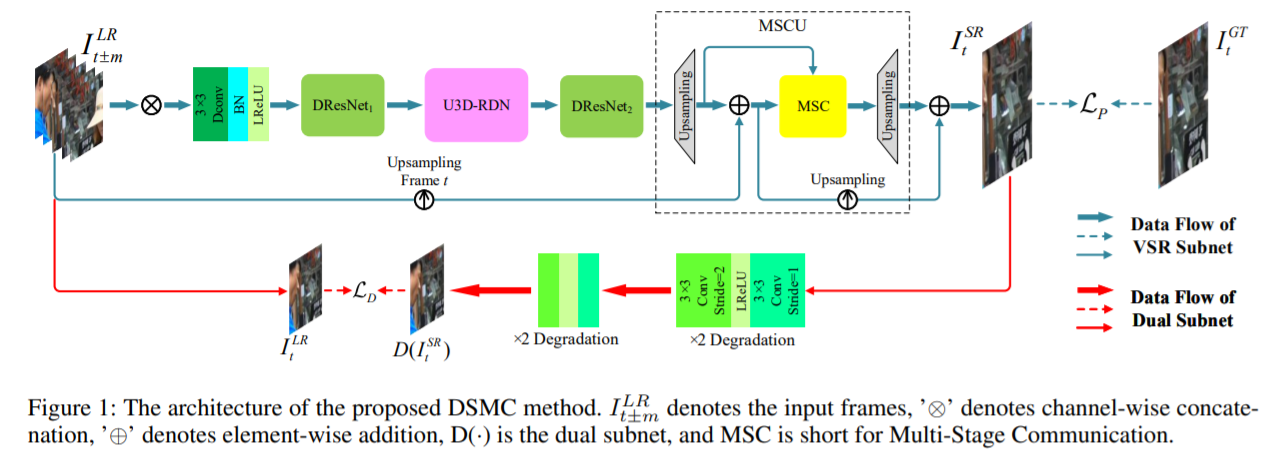
以VSR 任务为例,我们的模型首先对输入的连续帧进行可变形卷积以进行粗略的特征提取。
然后由可变形残差网络 (DResNet) [■] 处理输出特征图在考虑时间特征之前提取精细的空间信息。
接下来,特征图被输入到带有 3D 卷积(U3D-RDN)的 U 形残差密集网络,用于时空特征的降维和相关分析。
紧接着另一个 DResNet 模块,将特征图发送到多级通信上采样 (MSCU) 模块。
最后,借助用于训练的双子网,DSMC 生成超分辨率 HR 帧。需要注意的是,只有双子网的输出和 VSR 结果用于 DSMC 的损失计算。
带有 3D 卷积的 U 形残差密集网络
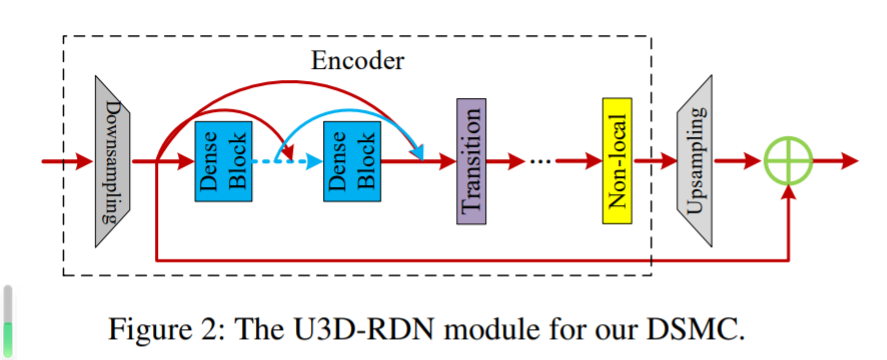
U3D-RDN 能够在没有高计算复杂度的情况下执行隐式 MEMC。
它通过2的下采样 对输入特征进行编码(33) 2D卷积,
然后在编码空间上进行残差学习后,通过亚像素卷积上采样层解码残差图。
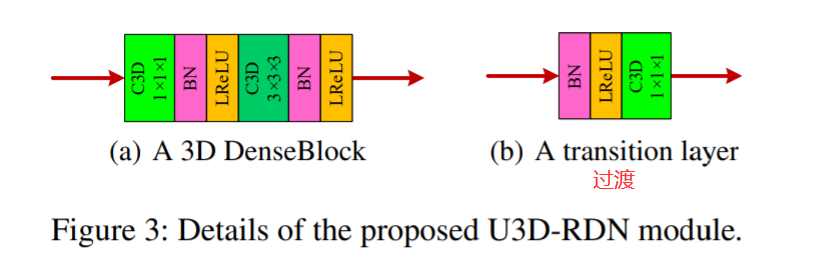
包括了:
1)m groups of dense blocks with 3D convolution (3D DenseBlock), as shown in Figure 3 (a), 3D卷积是为了大运动 该方法在输入特征的空间和时间域中运行。
在 3D DenseBlock 中,1×1×1 C3D 负责输入的特征分解,而 3×3×3 C3D 用于高维空间中的时空特征提取。
这些组块可以一起建立长距离依赖并避免梯度消失问题。
2)transition layers in Figure 3 (b) among the groups,
在 U3D-RDN 中,除了最后一个之外,每个 3D DenseBlock 之后都部署了一个过渡层。
它可以将前一组级联输出的时间维度减半,以增强模块的学习能力,帮助实现更深层次的网络。
众所周知,当 3D DenseBlock 的数量增加时,相邻块输入的维度也会增加。那么随着网络的深入,U3D-RDN的学习能力也可以得到增强。然而,深度的增加也给硬件成本带来了负担。过渡层可以维持网络深度的增加,减轻计算成本的负担。
3)and a 3D non-local (Wang et al. 2018b) layer
C3D 由于其同步的时空过程可能会突出 CNN 中长距离依赖的不足。
因此,在对 3D DenseBlock 的输出 进行上采样之前 ,采用非局部模块来处理特征图。这个非本地模块可以建立对全局信息的更相关的依赖。
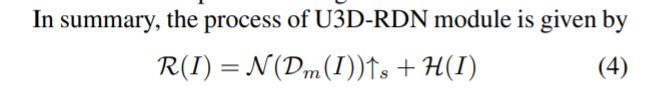
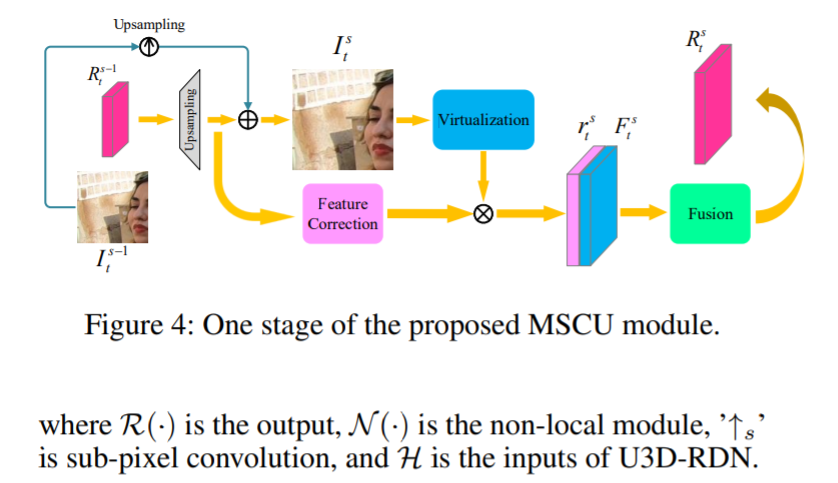
以充分利用上采样阶段的先验知识来恢复 HR 帧。
维数灾难被认为是限制超分辨率的主要因素。
建立从LR空间到HR空间的映射,需要足够的先验信息。
在我们的 MSCU 中,为了充分利用先验信息,我们将 VSR 的上采样过程分解为更小的过程。
我们建议每个sub scale factor子比例因子 都应该是素数,以最大化结构的通信能力。
例如,一个a4的上采样任务可以分解为两个连续的2的上采样任务。
通过子输出,网络将能够捕获每个阶段的相应不确定性并尝试修复它们。
上采样后的残差图进行到两个分支。
一种是通过 ResNet 进行特征校正以生成,而另一种是通过 11卷积 和 元素级加法与双三次上采样中心帧 进行通道减少以生成固定帧。
然后将被另一个11卷积虚拟化。
虚拟结果接下来按通道连接到 ResNet的结果上 。
连接的特征图最终通过1*1卷积融合以生成下一阶段的残差图。
双重学习机制 起作用的原因是协作操作的多任务连接。multi-task connectivity of collaborative operations.
它可以将训练约束扩展到输出和输入,这有助于进一步减少解空间,从而使网络更容易收敛。
双重问题是尽可能接近LR目标帧恢复VSR输出的退化结果。
在我们提出的双子网中,我们模拟了真实的图像退化过程,包括模糊、下采样和噪声添加。在数学上,SR 图像和 LR 图像通过以下退化模型 [■] 相关联 :
具体来说,模糊和下采样过程分别由两个2D 卷积(C2D)完成,而噪声通过下采样 C2D 的偏差添加到退化帧中。

读后:Large Motion Video Super-Resolution with Dual Subnet and Multi-Stage Communicated Upsampling
标签:spatial 执行 who space 特征提取 中心 复杂 ali tar
原文地址:https://www.cnblogs.com/ming-michelle/p/14897675.html