标签:img read 问题 多个 get mil 资料 函数 ack
20193304 2020-2021-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1933
姓名: 白宁
学号:20193304
实验教师:王志强
实验日期:2021年6月14日
必修/选修: 公选课
1.实验内容:爬取并下载网页图片
2.实验过程及结果:
1)导入库:
#coding = utf-8
import urllib
import re
utf-8是为了支持中文。
urllib 用来进行 url 网络请求。
re 是一个正则表达式匹配的库。
要先对网站进行模拟请求,然后找到网站中的图片进行下载。
2)请求网站:
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
getHtml就是用来模拟浏览器访问网站的,参数 url 是要访问的网站链接,这里我们在下面的变量 html 处调用了这个方法,其访问的 url 是要下载图片的网站。
先用了 urllib 库的 urlopen 方法来打开网站,然后通过 read 方法来获取网站的源代码,最后返回了读取到的网站源代码。
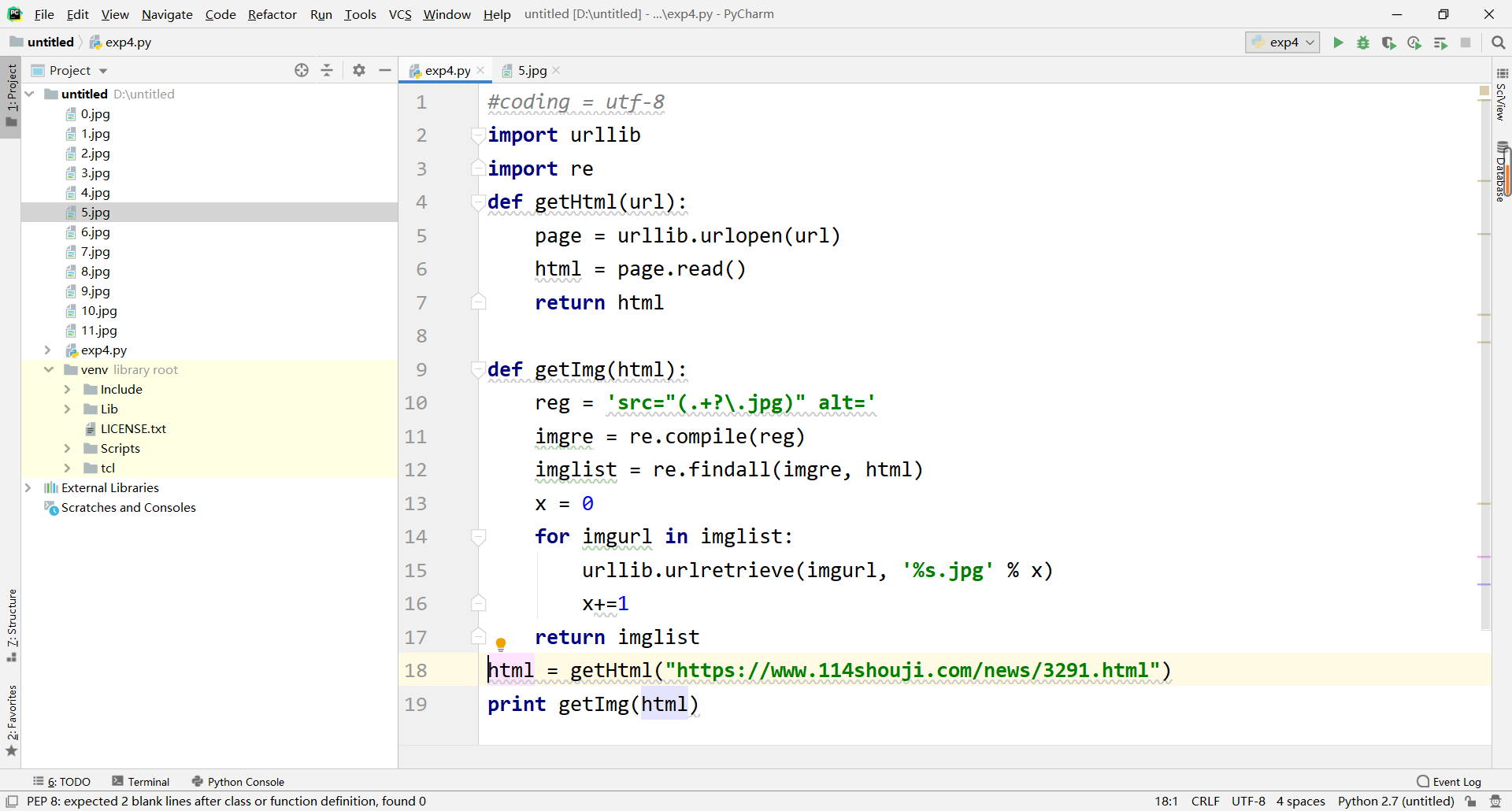
3)找到图片:
def getImg(html):
reg = ‘src="(.+?\.jpg)" alt=‘
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl, ‘%s.jpg‘ % x)
x+=1
return imglist
使用 getImg 方法。在这个方法中,我们设置了一个正则表达式,用来在网页源代码中找到图片的资源路径。
用 re 库的 compile 函数将正则表达式转换成正则表达式对象,然后使用 findall 函数寻找 html 网页源代码中包含的匹配 imgre 的所有内容,返回一个序列。我们可以输出这个序列,可以看到大量图片资源路径组成的一个序列,如果没爬取到,就是个空序列了。
4)下载图片
最后一步就是下载图片,这里我们用 for 循环,将图片资源路径中的每个图片,使用 urllib 库的 urlretrieve 函数来下载图片。
 3.实验过程中遇到的问题和解决过程
3.实验过程中遇到的问题和解决过程
- 问题1:多个网站没有成功爬下图片
- 原因:1)反爬虫2)每张图片的元素不固定
4.实验心得:
正则表达式学完以后没有怎么使用,这次使用了觉得很强大很方便。
这次实验查了很多资料,也发现了许多有意思的爬虫,像爬取在线小说、图片、数据……贴近生活又十分实用,因为我很喜欢看小说,而很多在线小说的广告很烦人,就想做一个爬取小说的实验,大约是版本较低的原因,总有一个地方报错,找问题也花了较长时间,就先放一下,假期有时间了下一个py3,再做一些感兴趣的尝试。
相比之前学习的C,python给我的感觉是:有强大的库、写起来方便实用,更贴近生活。
最后,感谢志强老师这学期的精彩课堂,每次的三节课的时间都过得很快并且收获满满。(鞠躬)
5.参考资料:https://blog.csdn.net/cloudox_/article/details/53465923
20193304 2020-2021-2 《Python程序设计》实验四报告
标签:img read 问题 多个 get mil 资料 函数 ack
原文地址:https://www.cnblogs.com/bbnn/p/14906362.html