标签:字段 ram pat ase 转化 冲突 ati path port
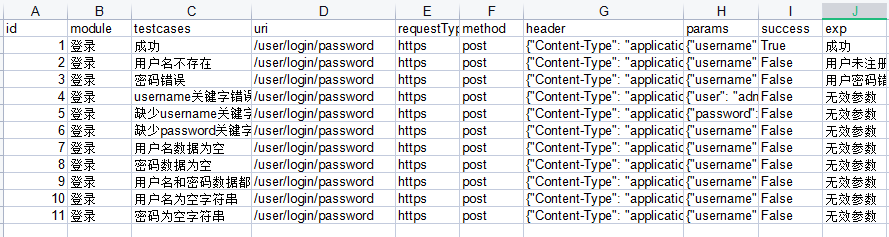
在自动化测试中,一个测试用例对应一个测试点,通常一组测试数据无法完全覆盖测试范围,所以,需要参数化来传递多组数据。
将每个用例及对应需要输入的参数都保存在excel表的每一行里,执行用例时循环取出每组数据就可以了。
测试用例如下:
operation_excel.py
import xlrd from xlwt import * import json import os from xlutils.copy import copy import openpyxl import re class ReadExcel(object): def __init__(self, filepath, sheetname): self.filepath = filepath self.sheetname = sheetname # 打开excel并创建对象存储 self.data = xlrd.open_workbook(self.filepath) # 根据工作表的名称获取工作表中的内容 self.table = self.data.sheet_by_name(self.sheetname) # 获取工作表第一行的所有字段列表 self.keys = self.table.row_values(0) # 获取工作表的有效行数 self.rownum = self.table.nrows # 获取工作表的有效列数 self.colnum = self.table.ncols def read(self, module): liens = [] colData = self.table.col_values(2, 1, self.rownum) # 取一列 数据 for row in range(1, self.rownum): if module == colData[row - 1]: liens.append(row) datas = [] for i in range(0, len(liens)): sheet_data = {} for j in range(self.colnum): c_type = self.table.cell(liens[i], j).ctype c_cell = self.table.cell_value(liens[i], j) # 单元格的值 if c_type == 2 and c_cell % 1 == 0: c_cell = int(c_cell) sheet_data[self.keys[j]] = c_cell datas.append(sheet_data) return datas
test_login.py
class Test_Login(object): rdexcel = ReadExcel(r"D:\Python37\Workspace\IndustryApi_Test\test_data\test_data.xlsx", "login") dic_data_login = rdexcel.read("登录") def setup_class(self): self.com = Comm() self.gh = GetHeader()
@pytest.mark.parametrize(‘data‘, dic_data_login)
def test_login(self, data): currentRow = data[‘id‘] br = BaseRequest(data["requestType"], data[‘uri‘]) dict_header = json.loads(data[‘header‘]) header = self.gh.get_header(data[‘method‘], data[‘params‘], "", br.key) dict_header.update(header) result = br.sureMethod(data[‘method‘], dict_header, data[‘params‘]) assert data[‘success‘] == str(result.json()[‘success‘]) assert data[‘exp‘] == result.json()[‘msg‘]
运行:

至此,登录部分11条测试用例全部执行结束。特别注意的是,excel中的header和params已经写成了json格式,但实际从excel中取出数据时字符串格式,需要用json.loads()转化一下才能使用。
以上实现了数据的自动读取功能,为了更方便的知道测试用例是否执行通过,可以加入写结果到excel的功能,执行用例执行后,直接将结果写入到对应的单元格:
class WriteExcel(object): def __init__(self, filepath, sheetname, newpath): self.filepath = filepath self.sheetname = sheetname self.newpath = newpath wb = xlrd.open_workbook(self.filepath) # 打开excel文件 self.rows = wb.sheet_by_name(self.sheetname).nrows # 获取已有的行数 self.excel = copy(wb) # 复制原文件 self.worksheet = self.excel.get_sheet(self.sheetname) # 获取要操作的sheet def write(self, row, col, result): self.worksheet.write(row, col, result) self.excel.save(self.newpath)
上述写数据方法与读数据方法一开始是分为两个类写的(不需要),所以出现了以下情况:
1.当WriteExcel类中的filepath与newpath相同时,会出现读写冲突,其他测试用例文件找不到test_data.xlsx;
2.当WriteExcel类中的filepath与newpath不同时,后面测试用例的数据会将前面测试用例的数据覆盖掉,最终只保存最后一个执行的用例文件的结果数据。
标签:字段 ram pat ase 转化 冲突 ati path port
原文地址:https://www.cnblogs.com/nailao/p/14902979.html