标签:数据库中间件 har 执行sql 大数据 针对 会同 cond cobar 运维
为什么要分库分表?
将承受并发的能力提升3倍
将大数据了拆成多份 提升sql效率
用过哪些分库分表中间件/不同中间件的优缺点
cobar
TDDL 只支持基本的crud操作
atlas 社区不咋维护了
sharding-jdbc(集成client) 运维成本低 缺点是耦合系统版本
mycat(proxy) 需要一些运维成本
如何对数据库进行水平拆分/垂直拆分
可以将数据拆分成多个库,多个表,先根据id取模求出库 再根据表取模求出表 优点:可以平摊每个库的数据量和请求压力,缺点:扩容比较麻烦
可以根据时间范围或者其他范围来分库分表 优点:扩容很容易 缺点:大部分数据都会请求新数据,热点数据问题
如何设计让系统转换为分库分表 数据如何迁移
1. 停机迁移方案
拉取旧数据依次放入新的数据库中 迁移完之后后来的数据发到数据库中间件中
2. 不停机双写方案
写请求即写老库又写分库分表中间件
后台数据迁移临时程序 从老库读取出数据让分库分表中间件进行数据分发 注意要新数据覆盖老数据
迁移完一轮对比两个库数据是否一模一样 不一样的话就再跑一轮 跑几天之后
如何设计一个动态扩容缩容的分库分表方案?
1.停机扩容
依次进行数据迁移
2. 第一次分库分表的时候就上32个库32个表
每个数据库服务器最多能支撑2000个并发请求
在每个数据库服务器上创建8个数据库 每个库32张表 创建4个数据库服务器
当支撑不了并发或者磁盘空间不足时
再创建四个数据库服务器,在原先的数据库服务器上迁移一半的数据库到新的数据库服务器中
可以扩展到32个数据库服务器 每个服务器1个库 一个库32张表
如何设计可以动态扩容缩容的分库分表方案
id%32 = 库
(id/32)%32 = 表
分库分表之后id主键如何处理
1. 用一个生成主键的表 从哪里获取id 适用于并发不高的情况
2. 业务字段值+当前时间拼接
3. 雪花算法 首位0 + 时间戳转2进制 + 机房 + 机器
当同一个机房同一个机器在同已毫秒请求一次 末尾值二进制+1 最多只能在同一毫秒中生成4096个id 最多只能部署32个机房 每个机房32台机器
mysql读写分离 主从同步延迟怎么解决?
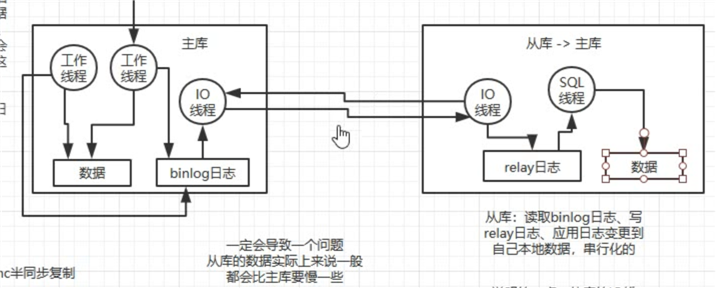
主从复制的原理:
binlog日志
从库是多线程的从主库读取出binlog写到relay日志中,但是是单线程的从relay读取日志并执行sql创建数据
产生所谓的主从延迟 主库的写并发达到1000/s的时候 从库会有几毫秒的延迟 2000会慢几十毫秒
semi-sync半同步复制
主库宕机时 还未同步数据到从库 导致数据丢失 semi-sync半同步复制 数据写入主库会同步的写入从库,从库写入relay日志之后返回ack才成功
并行复制
开多个sql线程去执行relay日志中一个库的日志进行重放
show status seconds_behind_master
针对插入立刻需要查询的逻辑可以使用:
1. 拆分主库降低写并发
2. 打开并行复制
3. 在主库插入之后从主库查询
4. 重写代码慎重一些,插入之后直接更新从主库
标签:数据库中间件 har 执行sql 大数据 针对 会同 cond cobar 运维
原文地址:https://www.cnblogs.com/isnotnull/p/14912808.html