标签:back 性能 read -o package head main list span
编译器和CPU会尝试重排指令使得代码更快地运行
发生情况:
代码间没有直接联系,没有依赖
这样就会发生指令重排a
拿到指令,进行编译,放入寄存器--->fetch
解码指令,从寄存器中拿值,从主存拷贝到工作内存--->copy
执行选项--->excutor operation
将结果同步到主存当中--->write back
步骤如图:

以上是我们的高级语言在汇编层面的展示
第二条是求和指令,第三条是赋值指令。有可能求和比赋值慢此时CPU查看到赋值指令比较快且和本次求和指令无关联就会把下面的赋值指令提前到求和指令这里。此时求和指令的计算结果还没有写回到寄存器当中有可能后面条件为isDone的指令就已经运行了。
在多线程环境下有可能我们在操作total,那么此时的值可能就不是我们需要的total了。所以在多线程环境下指令重排会对线程操作结果有影响。
执行代码的顺序可能与编写代码不一致--->虚拟机优化代码顺序,则为指令重排happen-before
编译器或运行时环境为了优化程序性能而采取的对指令进行重新排序执行的一种手段
指令重排在虚拟机层面的表现:
目的:
尽可能减少内存操作速度远慢于CPU运行速度所带来地CPU空置的影响
前提:
后面的指令先于前面执行不会产生错误(产生什么错误?)
过程:
写在前面的代码先执行,当效率较慢时,后面的代码先于前面的代码开始执行,并且先于前面的代码执行结束。写在后面的代码存在一些情况下先于前面的结束。
指令重排在硬件层面的表现:
CPU会接收到一批指令按照其规则重排序,基于CPU速度比缓存速度快的原因,只是硬件处理,每次能接收到有限指令范围内重排序,虚拟机可以在更大层面、更多指令范围内重排序。
数据之间没有依赖:
什么是数据依赖?
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖。
分类:
| 名称 | 代码示例 | 说明 |
|---|---|---|
| 写后读 | a = 1;b = a; | 写一个变量之后再读这个变量(变量之间的赋值不是写而是读--->一个区域拷贝到另一个区域) |
| 写后写 | a = 1;a = 2; | 写一个变量之后再写这个变量(两次赋值操作) |
| 读后写 | a = b;b = 1; | 读一个变量之后再写这个变量(赋值--->写) |
以上三种情况,如果指令重排,程序的执行结果将会被改变。所以编译器何处理器不会改变存在数据依赖关系的两个操作的执行顺序。
package thread.rearrangement;
?
/**
* 指令重排:代码的执行顺序与预期的不一致
* 目的:提高性能
* @since JDK 1.8
* @date 2021/6/22
* @author Lucifer
*/
public class HappenBeforeNo1 {
?
/*添加两个无关联的变量*/
private static int a = 0;
?
private static boolean flag = false;
?
public static void main(String[] args) throws InterruptedException {
?
/*
创建两个线程:
1、一个对int进行修改
2、另一个对int进行读取
*/
?
for (int i=0; i<10; i++){
?
/*每次都要初始化*/
a = 0;
flag = false;
?
//线程一:更改数据--->使用Lambda表达式
Thread t = new Thread(() ->{
a = 1;
flag = true;
});
?
//线程二:读取数据
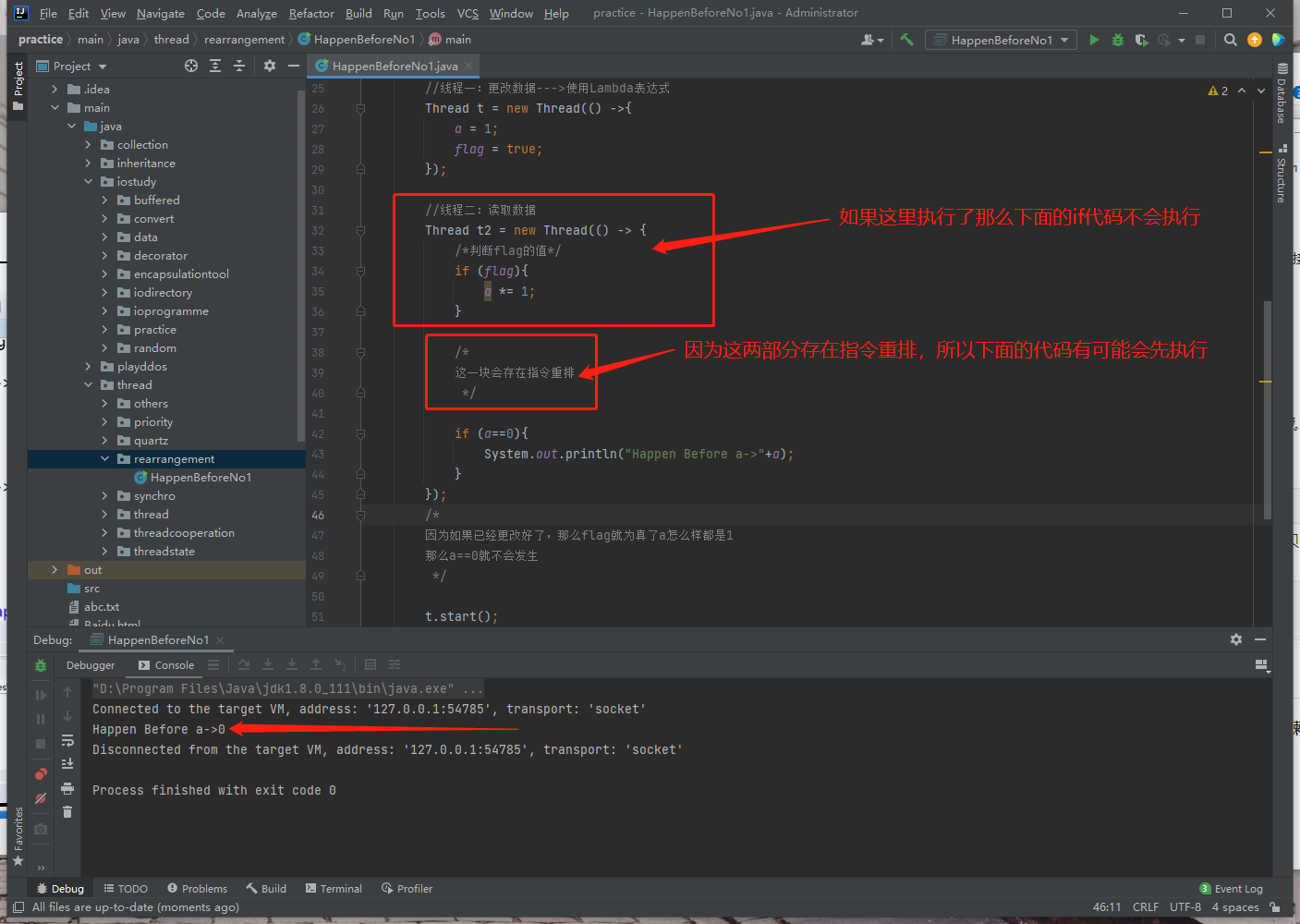
Thread t2 = new Thread(() -> {
/*判断flag的值*/
if (flag){
a *= 1;
}
?
/*
这一块会存在指令重排
a的值没有写入主存当中,所以执行了下面if(a==0)的结果
*/
?
if (a==0){
System.out.println("Happen Before a->"+a);
}
});
/*
因为如果已经更改好了,那么flag就为真了a怎么样都是1
那么a==0就不会发生
*/
?
t.start();
t2.start();
?
//线程插队--->合并线程
t.join();
t2.join();
?
}
}
}
*解析图:
标签:back 性能 read -o package head main list span
原文地址:https://www.cnblogs.com/JunkingBoy/p/14921541.html