r/R:非转义的原始字符串
与普通字符相比,其他相对特殊的字符,其中可能包含转义字符,即那些,反斜杠加上对应字母,表示对应的特殊含义的,比如最常见的”\n”表示换行,”\t”表示Tab等。而如果是以r开头,那么说明后面的字符,都是普通的字符了,即如果是“\n”那么表示一个反斜杠字符,一个字母n,而不是表示换行了。
以r开头的字符,常用于正则表达式,对应着re模块。
r‘input\n‘ # 非转义原生字符,经处理’\n’变成了’\‘和’n’。也就是\n表示的是两个字符,而不是换行。
输出:
‘input\\n‘b:bytes
python3.x里默认的str是(py2.x里的)unicode, bytes是(py2.x)的str, b”“前缀代表的就是bytes
python2.x里, b前缀没什么具体意义, 只是为了兼容python3.x的这种写法
b‘input\n‘ # bytes字节符,打印以b开头。
输出:
b‘input\n‘
u/U:表示unicode字符串
不是仅仅是针对中文, 可以针对任何的字符串,代表是对字符串进行unicode编码。
一般英文字符在使用各种编码下, 基本都可以正常解析, 所以一般不带u;但是中文, 必须表明所需编码, 否则一旦编码转换就会出现乱码。
建议所有编码方式采用utf8
u‘input\n‘ # unicode编码字符,python3默认字符串编码方式。
输出:
‘input\n‘
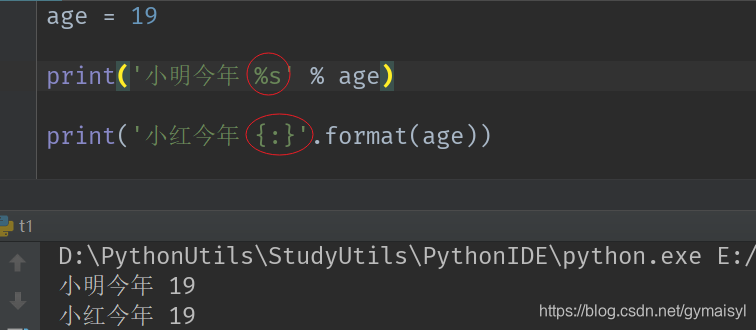
f/format():格式化操作
案例如下: