标签:持久化 error cache 查询 mysql 权限 配置优化 数据库 删除
首先我们要谈论什么是性能?
一般来说,DB/SQL操作的消耗在一次处理中占比最大。DB/SQL优化是业务系统的性能核心
什么是关系数据库?
1970年Codd提出关系模型,以关系代数理论为数学基础。建立在关系数据库模型基础上的数据库,称为关系数据库。
数据库设计范式
名词解释:
函数依赖:一张表中,属性X的值确定的情况下,必定能确定属性Y的值,那么就说Y函数依赖于X。写作X->Y
完全函数依赖:
设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X
部分函数依赖:
设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。
传递函数依赖:Z函数依赖于Y,且Y函数依赖于X,那么称Z传递函数依赖于X。
码:设K为某表中的一个属性或属性组,除K外的所有属性都完全函数依赖于K,那么称K为候选码,简称码。
非主属性:除去主属性的就是非主属性
举例说明:
下面表是否符合第二范式?
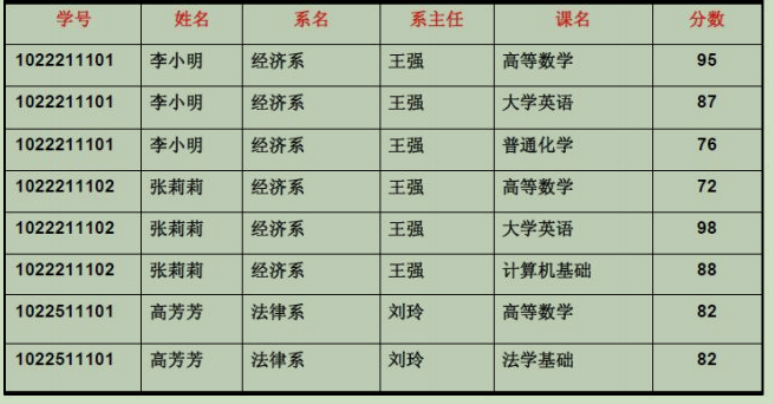
(学号、课名)可以作为码。
有 (学号,课名)->姓名,但是学号->姓名,存在非主属性“姓名”对码的部分函数依赖。
有 (学号,课名)->系名,但是学号->系名,存在非主属性“系名”对码的部分函数依赖。
所以不符合第二范式。
下面表是否符合第三范式?

主属性是学号,有学号->系名,系名->系主任。所以系主任传递函数依赖于学号,所以不符合第三范式。
常见数据库
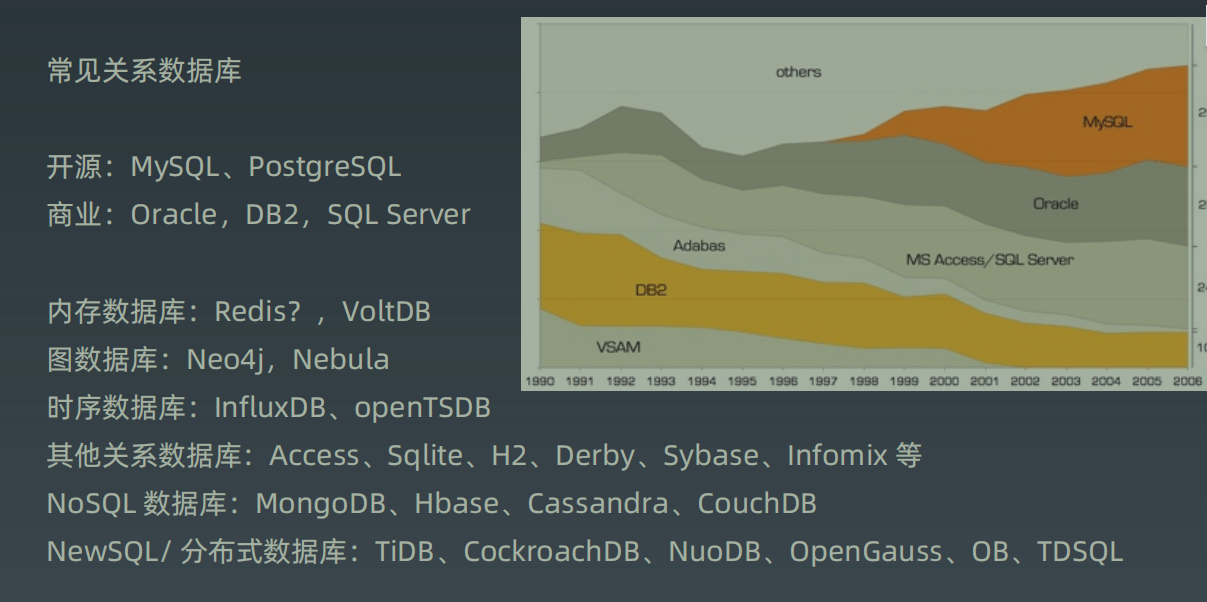
结构化查询语言包含6个部分:
MySQL数据库的版本
MySQL简化的执行流程:
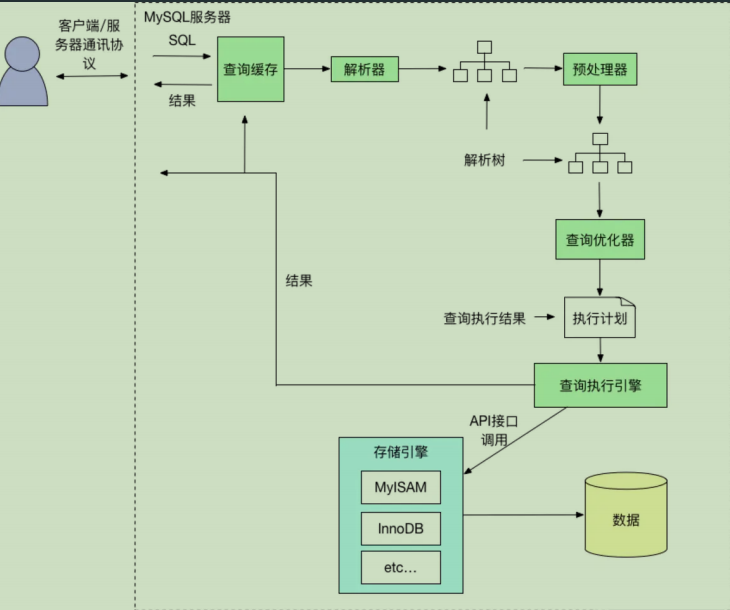
MySQL详细执行流程
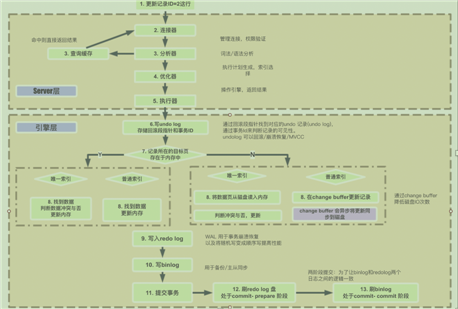
MySQL执行引擎:
| 存储引擎 | myisam | innodb | memory | archive |
|---|---|---|---|---|
| 存储限制 | 256TB | 64TB | 有 | 无 |
| 事务 | - | 支持 | - | - |
| 索引 | 支持 | 支持 | 支持 | - |
| 锁的粒度 | 表锁 | 行锁 | 表锁 | 行锁 |
| 数据压缩 | 支持 | - | - | 支持 |
| 外键 | - | 支持 | - | - |
数据是按页分块的,当一个数据被用到时,其附近的数据也通常会马上被使用
MySQL索引结构:
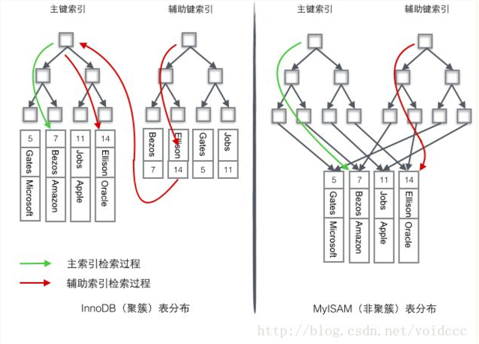
Mysql innodb的索引结构是B+树。
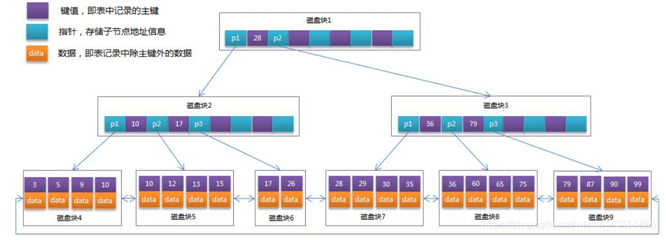
B+树简单的说是一种平衡查找树,所有的记录节点都是按大小顺序存放在同一层的叶子节点上,由各叶子节点的指针开始连接。页之间是双向链表连接,页里面的数据是单向链表。
B+树索引又分为聚集索引和辅助索引
聚集索引:
按照每张表的主键构造一颗B+树,同时叶子节点存放的为整张表的行记录数据,也叫聚集索引的叶子节点称为数据页。由于实际的数据页只能按照一颗B+树进行排序,因此每个表只能拥有一个聚集索引。
很多文档说:聚集索引按照顺序物理的存储数据,其实不是,它的存储不是物理上连续的,而是逻辑上连续的。
非聚集索引
也叫辅助索引,叶子节点除了包含键值外,还包含找到与索引对应的行数据的指针。
如果需要在一颗高度为3的辅助索引中查找数据,需要遍历3次找到指定主键,如果聚集索引树高度也为3,那么还需要对聚集索引树进行3次查找,最终找到一个完整的行数据所在页。
为什么一般单表的数据不能超过2000万?
答:首先一个页16K。
可以算出2层的B+树放1170x16=18724条数据。如果3层的B+树1170x1170x16=21,902,400条数据。
所以如果超过这么多数据,那么B+树就会变为4层,那么查询就慢了。
连接请求的变量
缓冲区变量
4. key_buffer_size
5. query_cache_size(查询缓存简称 QC)
6. max_connect_errors:
7. sort_buffer_size
8. max_allowed_packet=32M
9. join_buffer_size=2M
10. thread_cache_size=300
配置 Innodb 的几个变量
11. innodb_buffer_pool_size
12. innodb_flush_log_at_trx_commit
13. innodb_thread_concurrency=0
14. innodb_log_buffer_size
15. innodb_log_file_size=50M
16. innodb_log_files_in_group=3
17. read_buffer_size=1M
18. read_rnd_buffer_size=16M
19. bulk_insert_buffer_size=64M
20. binary log
标签:持久化 error cache 查询 mysql 权限 配置优化 数据库 删除
原文地址:https://www.cnblogs.com/javammc/p/15008398.html