在一个复制系统中,为了保持一致性,各个replicated server是串行执行,这样性能上就会比只有一台server的系统慢,因为只有一台server可以进行并行处理。如果在复制系统中各个server也能进行并行处理的话, 这将是很大的进步。
但是如果各个线程之间没有共享变量的话,在复制系统的每个server上进行并行处理也是可行的,实际上以前很多复制系统并行处理都是基于这一点去做的。
P-SMR也是要根据命令之间的依赖关系判断什么情况下可以并行,什么情况下是串行。
我们需要将服务程序抽象成一个状态机,一个Mealy状态机。要构建一个State-Machine Replication系统,其中必不可少的模块就是proxy,client的proxy和server的proxy。比如当请求到达server时,需要server proxy去评估是否能并行执行,以及如何去并行,而且也是通过proxy在replicas之间和client-server之间传递信息。如同RPC(远程过程调用)一样。再例如,对于一个命令,多个server会向client发送多个相同的response,但是经过server proxy,发给client的只会是一个response。
先来了解一下什么样的两个命令是相互依赖(dependent)的:他们访问(读或写)一个公共变量v,并且至少其中一个命令改变了v的值。如一个命令是读v,另一个是更新v。但这样的话不论是只有一个server的系统还是replication系统,都不能并行执行,只能按照total order来依次处理命令。所以如果命令间是dependent的,replication只能采取串行执行。这样越说越不对劲了,这样的话replication系统要解决什么问题呢?是让independent的命令并行执行,还是让dependent的命令并行执行?下面来寻找答案。
答案是independent。你可能会问:这有什么难的?实际上我们忽略了一个问题,除了命令的执行可以并行化,如何也让命令并行的传递(delivery),此时多个命令还是串行的在传递,所以这应该是P-SMR要去挑战的地方,做到全部并行化,而非半并行化。
所以P-SMR意思是 parallel state-machine replication,能做到命令执行和传递都并行化的一个方法。对于一个replica除了能做到并行执行命令外,也在multicast这个环节做到并行化。到底multicast这个地方并行化的难度在哪里呢?
这里引入P-SMR里的一个概念C-Dep(command dependencies),一般来说如果两条命令的参数是同一个对象,而且是update操作,则可以预判这两条命令相互依赖。在client proxy里有个函数叫 Command-to-Group (C-G) ,它会在client的命令和该命令要去的地方建立起映射,告诉哪个命令该去哪个地方。下面是这个过程的算法:

让我们设想一下,在这个C-G函数中,需要做到:
假设这时有4个命令亟待执行。
1)C-G函数要能判断这4个命令之间的C-Dep
2)假如4个命令之间是independent的,C-G对这4个命令的目的地的映射要达到最大的并行化的目的
3)假如4个命令之间是dependent,C-G要让这4个命令实现串行处理。
如何做到 2) 呢?C-G要将这4个命令分配给不同的组groups。
这里再解释一下P-SMR里的groups。在replication系统中假设有5台server(A, B, C, D, E),每台server配置一样,一台server上拥有4个core,这时我们可以说这个系统的MPL(multiprogramming level)是4,我们可以为每台server定义4个worker thread(t1, t2, t3, t4),这4个thread运行在4个core上,这时我们可以说这个系统有4个groups,分别是:
g1: A(t1), B(t1), C(t1), D(t1), E(t1)
g2: A(t2), B(t2), C(t2), D(t2), E(t2)
g3: A(t3), B(t3), C(t3), D(t3), E(t3)
g4: A(t4), B(t4), C(t4), D(t4), E(t4)
g5: A(t5), B(t5), C(t5), D(t5), E(t5)
再来看一个C-G应用的场景。假设这时有两个命令:
set_state(v)
get_state(v)
对于get_state,虽然这是一个复制系统,但这个命令并不需要发给所有replicas,只需其中一个执行并返回结果即可,而对于set_state,则需要让每一个replica都去执行。
这里先记录下P-SMR的一个优点:
P-SMR offloads scheduling decisions from the replicas, avoiding a bottleneck-prone scheduler, which must deliver a single stream of commands and assign them to the worker threads for execution。
尝试解释一下:传统的并行执行,是让linux内核来做调度,将4个independent的命令分配在4个线程上。而在P-SMR中client proxy中的C-G起到了调度官(scheduler)的作用,即由C-G来制定线程分配的调度策略,这样的话就能指定某个命令分配到特定的线程上,而这在传统的linux内核调度上是做不到的,这也是P-SMR能做到并行执行的核心思想和方法所在。下面是我对P-SMR的理解:
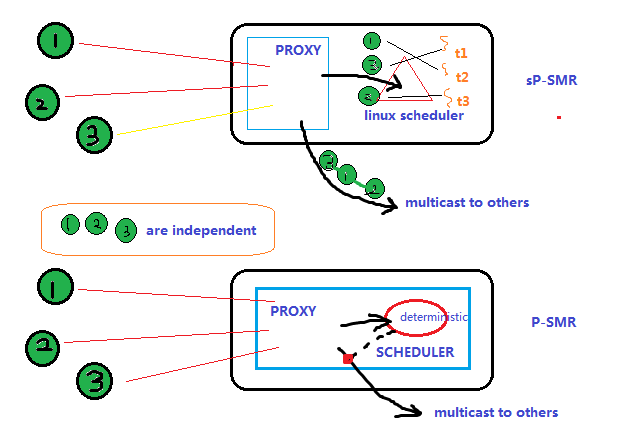
通过P-SMR看State Machine Replication
原文地址:http://blog.csdn.net/bluecloudmatrix/article/details/41290909