标签:style blog http ar color sp strong 数据 on
BP算法推算过程
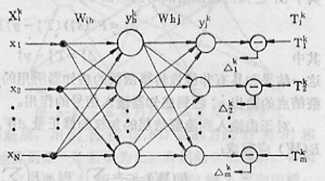
当加入第$k$个输入时,隐蔽层$h$结点的输入加权和为:
\[s_h^k = \sum\limits_i {w_{ih} x_i^k }\]
相应点的输出:
\[y_h^k = F(s_h^k ) = F(\sum\limits_i {w_{ih} x_i^k } )\]
同样,输出层$j$结点的输入加权和为:
\[s_j^k = \sum\limits_h {w_{hj} y_h^k } = \sum\limits_h {w_{hj} F(\sum\limits_i {w_{ih} x_i^k } )}\]
相应点的输出:
\[y_j^k = F(s_j^k ) = F(\sum\limits_h {w_{hj} y_h^k } ) = F[\sum\limits_h {w_{hj} F(\sum\limits_i {w_{ih} x_i^k } )} ]\]
这里,各结点的阈值等效为一个连接的加权$\theta=w_{oh}\text{or} w_{oj}$,这些连接由各结点连到具有固定值-1的偏置结点,其连接加权也是可调的,同其它加权一样参与调节过程。
误差函数为:
\[E(W) = \frac{1}{2}\sum\limits_{k,j} {(T_j^k - y_j^k )^2 } = \frac{1}{2}\sum\limits_{k,j} {\{ T_j^k - F[\sum\limits_h {w_{hj} F(\sum\limits_i {w_{ih} x_i^k } )} ]\} ^2 }\]
为了使误差函数最小,用梯度下降法求得最优的加权,权值先从输出层开始修正,然后依次修正前层权值,因此含有反传的含义。
根据梯度下降法,由隐蔽层到输出层的连接的加权调节量为:
\[\Delta w_{hj} = - \eta \frac{{\partial E}}{{\partial w_{hj} }} = \eta \sum\limits_k {(T_j^k - y_j^k )F‘(s_j^k )y_h^k = } \eta \sum\limits_k {\delta _j^k y_h^k }\]
其中$\delta_j^k$为输出结点的误差信号:
\[\delta _j^k = F‘(s_j^k )(T_j^k - y_j^k ) = F‘(s_j^k )\Delta _j^k \quad\quad (1)\]
\[\Delta _j^k = T_j^k - y_j^k\]
对于输入层到隐蔽层结点连接的加权修正量$\Delta w_{ij}$,必须考虑将$E(W)$对$w_{ih}$求导,因此利用分层链路法,有:
\[\begin{array}{l}\Delta w_{ih} = - \eta \frac{{\partial E}}{{\partial w_{ih} }} = - \eta \sum\limits_k {\frac{{\partial E}}{{\partial y_h^k }}} \cdot \frac{{\partial y_h^k }}{{\partial w_{ih} }} = \eta \sum\limits_{k,j} {\{ (T_j^k - y_j^k )F‘(s_j^k )w_{hj} \cdot F‘(s_h^k )x_i^k } \} \\ \quad \quad = \eta \sum\limits_{k,j} {\delta _j^k w_{hj} F‘(s_h^k )x_i^k } = \eta \sum\limits_k {\delta _h^k x_i^k } \\ \end{array}\]
其中:
\[\delta _h^k = F‘(s_h^k )\sum\limits_j {w_{hj} \delta _j^k } = F‘(s_h^k )\Delta _h^k \quad\quad (2)\]
\[\Delta _h^k = \sum\limits_j {w_{hj} \delta _j^k }\]
可以看出,式(1)和(2)具有相同的形式,所不同的是其误差值的定义,所以可定义BP算法对任意层的加权修正量的一般形式:
\[\Delta w_{pq} = \eta \sum\limits_{vector\_no\_P} {\delta _o y_{in} }\]
若每加入一个训练对所有加权调节一次,则可写成:
\[\Delta w_{pq} = \eta \delta _o y_{in}\]
其中,下标o和in指相关连接的输出端点和输入端点,$y_{in}$代表输入端点的实际输入,$\delta_o$表示输出端点的误差,具体的含义由具体层决定,对于输出层由式(1)给出,对隐蔽层则由式(2)给出。
输出层$\Delta _j^k = T_j^k - y_j^k $可直接计算,于是误差值$\delta_j^k$很容易得到。对前一隐蔽层没有直接给出目标值,不能直接计算$\Delta _h^k $,而需利用输出层的$ \delta _j^k $来计算:
\[\Delta _h^k = \sum\limits_j {w_{hj} \delta _j^k }\]
因此,算出$\Delta _h^k $后,$ \delta _h^k $也就求出了。
如果前面还有隐蔽层,用$ \delta _h^k $再按上述方法计算$\Delta _1^k $和$\delta _1^k $,以此类推,一直将输出误差$\delta$一层一层推算到第一隐蔽层为止。各层的$\delta$求得后,各层的加权调节量即可按上述公式求得。由于误差$ \delta _j^k $相当于由输出向输入反向传播,所以这种训练算法成为误差反传算法(BP算法)。
BP训练算法实现步骤
准备:训练数据组。设网络有$m$层,$y_j^m$表示第$m$中第$j$个节点的输出,$y_^0$(零层输出)等于$x_j$,即第$j$个输入。$w_{ij}^m$表示从$y_i^{m-1}$到$y_j^m$的连接加权。这里,$m$代表层号,而不是向量的类号。
1.将各加权随机置为小的随机数。可用均匀分布的随机数,以保证网络不被大的加权值所饱和。
2. 从训练数据组中选一数据对$x^k,T^k$, 将输入向量加到输入层$(m=0)$,使得对所有端点$i$: $y_i^0=x_i^k$, $k$表示向量类号
3. 信号通过网络向前传播,即利用关系式:
\[y_j^m=F(s_j^m)=F(\sum_iw_{ij}^my_i^{m-1})\]
计算从第一层开始的各层内每个节点$i$的输出$y_j^m$,直到输出层的每个节点的输出计算完为止。
4. 计算输出层每个结点的误差值(利用公式(1))
\[\delta_j^m=F‘(s_j^m)(T_j^k-y_i^m)=y_j^m(1-y_j^m)(T_j^k-y_j^m),(\text{对Sigmod函数})\]
它是由实际输出和要求目标值之差获得。
5. 计算前面各层结点的误差值(利用公式(2))
\[\delta_j^{m-1}=F‘(s_j^{m-1}\sum_iw_{ji}\delta_i^m)\]
这里逐层计算反传误差,直到将每层类每个结点的误差值算出为止。
6. 利用加权修正公式
\[
\Delta w_{ij}^m = \eta \delta _j^m y_i^{m - 1}
\]
和关系
\[
w_{ij}^{new} = w_{ij}^{old} + \Delta w_{ij}
\]
修正所有连接权。一般$\eta=0.01--1$,称为训练速率系数。
7. 返回第2步,为下一个输入向量重复上述步骤,直至网络收敛。
标签:style blog http ar color sp strong 数据 on
原文地址:http://www.cnblogs.com/huadongw/p/4115155.html