标签:style blog http io ar color 使用 sp for
目录:
1. 索引概述
1.1 为什么引入索引
1.2 什么是索引
1.3 索引的好处
1.4 索引的不足
1.5 索引分类
2. 索引设计原则
3. 索引建立和删除
3.1 索引创建
3.2 索引删除
4. 索引实验
问题:假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储100条记录。如果没有索引,查询将对整个表进行扫描,最坏的情况下,如果所有数据页都不在内存,需要读取10^4个页面,如果这10^4个页面在磁盘上随机分布,需要进行10^4次I/O,假设磁盘每次I/O时间为10ms(忽略数据传输时间),则总共需要100s。
解决方案:对之建立B-Tree索引,则只需要进行log100(10^6)=3次页面读取,最坏情况下耗时30ms。
索引是根据表中一列或若干列按照一定顺序建立的列值与记录行之间的对应关系表。类似于一本书的目录。
在数据库系统中建立索引主要有以下作用:
(1) 快速取数据;
(2) 保证数据记录的唯一性;
(3) 实现表与表之间的参照完整性;
(4) 在使用order by、group by子句进行数据检索时,利用索引可以减少排序和分组的时间。
(1) 大大加快数据的检索速度;
(3) 加速表和表之间的连接;
(4) 在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
(1) 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
(2) 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
(3) 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速
1.5.1. 普通索引、唯一索引、主键索引。 (按创建SQL代码分类)
(1) 普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHERE column = …)或排序条件(ORDER BY column)中的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
(2) 唯一索引
普通索引允许被索引的数据列包含重复的值。比如说,因为人有可能同名,所以同一个姓名在同一个”员工个人资料”数据表里可能出现两次或更多次。
如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字UNIQUE把它定义为一个唯一索引。这么做的好处:一是简 化了MySQL对这个索引的管理工作,这个索引也因此而变得更有效率;二是MySQL会在有新记录插入数据表时,自动检查新记录的这个字段的值是否已经在 某个记录的这个字段里出现过了;如果是,MySQL将拒绝插入那条新记录。也就是说,唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯 一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
(3) 主键索引
在前面已经反复多次强调过:必须为主键字段创建一个索引,这个索引就是所谓的”主索引”。主索引与唯一索引的唯一区别是:前者在定义时使用的关键字是 PRIMARY而不是UNIQUE。
1.5.2. 聚簇索引和非聚簇索引[5]
(1) 聚簇索引
聚簇索引的顺序就是数据的物理存储顺序。聚簇索引的叶节点就是数据节点。
(2) 非聚簇索引
索引顺序与数据物理排列顺序无关。非聚簇索引的页节点仍然是索引检点,并保留一个链接指向对应数据块。
1.5.3. BTree和Hash索引[6]
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
(1) Hash 索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2) Hash 索引无法被用来避免数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3) Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
(4) Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5) Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下
两者区别:[7]
(1) hash索引查找数据基本上能一次定位数据,当然有大量碰撞的话性能也会下降。而btree索引就得在节点上挨着查找了,很明显在数据精确查找方面hash索引的效率是要高于btree的。
(2) 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持。
(3) 对于btree支持的联合索引的最优前缀,hash也是无法支持的,联合索引中的字段要么全用要么全不用。提起最优前缀居然都泛起迷糊了,看来有时候放空得太厉害。
(4) hash不支持索引排序,索引值和计算出来的hash值大小并不一定一致。
(1) 选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。如果使用姓名的话,可能存在同名现象,从而降低查询速度。
(2) 为经常需要排序、分组和联合操作的字段建立索引
经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。
(3) 为常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,为这样的字段建立索引,可以提高整个表的查询速度。
(4) 限制索引的数目
索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
(5) 尽量使用数据量少的索引
如果索引的值很长,那么查询的速度会受到影响。例如,对一个CHAR(100)类型的字段进行全文检索需要的时间肯定要比对CHAR(10)类型的字段需要的时间要多。
(6) 尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。
(7) 删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
3.1.1. ALTER TABLE
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
3.1.2. CREATE INDEX
CREATE INDEX可对表增加普通索引或UNIQUE索引。
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引。
可利用ALTER TABLE或DROP INDEX语句来删除索引。类似于CREATE INDEX语句,DROP INDEX可以在ALTER TABLE内部作为一条语句处理,语法如下。
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
其中,前两条语句是等价的,删除掉table_name中的索引index_name。
第3条语句只在删除PRIMARY KEY索引时使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。
如果从表中删除了某列,则索引会受到影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。
(1) 创建表、插入数据
create database mysql_learning;
use Mysql_learning;
create table person (
id int(10) not null,
name varchar(255) not null,
birthday date
);
insert into person values (2010195, ‘xiao ming‘, ‘2001-01-01‘);
insert into person values (2010196, ‘xiao hong‘, ‘2002-01-01‘);
insert into person values (2010197, ‘xiao ming‘, ‘2003-01-01‘);

(2) 查看索引
show index from person;
返回结果为空
show keys from person;
返回结果为空
select * from person where id=2010195;

(3) 创建普通索引
create index index_id on person(id);

(4) 数据查询
select * from person where id=2010195;

就三行数据,结果不明显。
(5) 查看索引
show index from person;

show keys from person;

(6) 删除索引
drop index index_id on person;
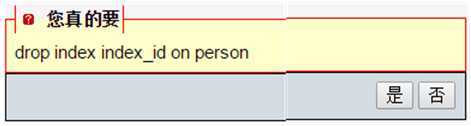
show index from person;
返回结果为空
show keys from person;
返回结果为空
(7) 创建唯一索引
create unique index index_id on person(id);

drop index index_id on person;

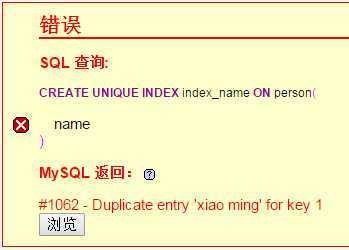
create unique index index_name on person(name);
参考:
[1] http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html
[2] http://baike.baidu.com/subview/262241/8045149.htm?fr=aladdin
[3] http://www.cnblogs.com/skylaugh/archive/2006/08/04/467516.html
[4] http://database.51cto.com/art/201103/252461.htm
[5] http://www.cnblogs.com/zhenyulu/articles/25794.html
[6] http://www.cnblogs.com/vicenteforever/articles/1789613.html
[7] http://blog.csdn.net/tonyxf121/article/details/7976824
[8] http://blog.chinaunix.net/uid-26602509-id-3138126.html
[9] http://www.cnblogs.com/tianhuilove/archive/2011/09/05/2167795.html
标签:style blog http io ar color 使用 sp for
原文地址:http://www.cnblogs.com/kereturn/p/4113001.html