标签:blog http ar os sp for 文件 on div
写机器学习相关博文,经常会碰到很多公式,而Latex正式编辑公式的利器。目前国内常用的博客系统,好像只有博客园支持,所以当初选择落户博客园。我现在基本都是用Latex写博文,然后要发表到博客园上与大家共享,就又得经历一番功夫:首先,将Latex源码拷贝到博文的HTML源码编辑器中;然后,修改部分HTML不支持的Latex源码,使得最后的博文跟我生成的PDF文档几乎一摸一样。这里面设计到图标的引用,论文的引用,文字颜色的调整,部分段落的标号等一些列问题。一旦文档有些长了,做这些工作就挺让人郁闷的。最讨厌的是,发现最后修改完工的HTML显示出来的文章也很部美观,而且文字大小和标题什么的也会随着博客主题的变化而变化,就美观性而言完全比不上Latex生成的PDF。对于我这种比较挑剔的人,我还希望看到的东西都是很美的,即便是博文!人嘛,都是有惰性的,我愿意跟大家分享学习的心得,但是不想把太多时间浪费在这些琐碎的事情上面。
人都是有惰性的,请原谅我总是有那么些偷懒的点子。那么如何非常便捷的将PDF文档的内容与大家共享呢?貌似没有博客支持直接浏览PDF文档的,但是几乎所有博客都支持图片。所以,我们可以用Adobe之类的软件将PDF转成JPG或PNG等格式的图片,但是转换得到的是每一页PDF对应一张图片。我甚至懒得将那十几页的图片一个个上传到博文中,然后如图图片大小不合适的话还得挨个调整,着实没有这个耐心啦!我希望可以直接有个工具帮我合并这些所有的图片。想了想,貌似没有现成的工具可用用。不过好像不难,自己完全可以搞定的。上述这些原因,也就促成了这篇短小的博文。
我计划以后的博文都如下操作:
好了,如果将PDF文档转换成其他的图片格式呢?我建议windowns下可用Adobe Acrobat X Pro软件完成这个工作,操作步骤如下面两图所示。注意在图二中一定要自己指定一个分辨率,不用用自动的,否则生成的图片大小会有差异的。就我的多次尝试来看,分辨率设置得太大了,虽然图片放大后仍然很清晰,但是贴到博文中仍然需要不断地调整大小,选择“59.06像素/厘米”就非常合适了。需要注意的是,博客的主题要选那种供博文显示的页面比较宽的,否则贴图片上去也不怎么好看的。
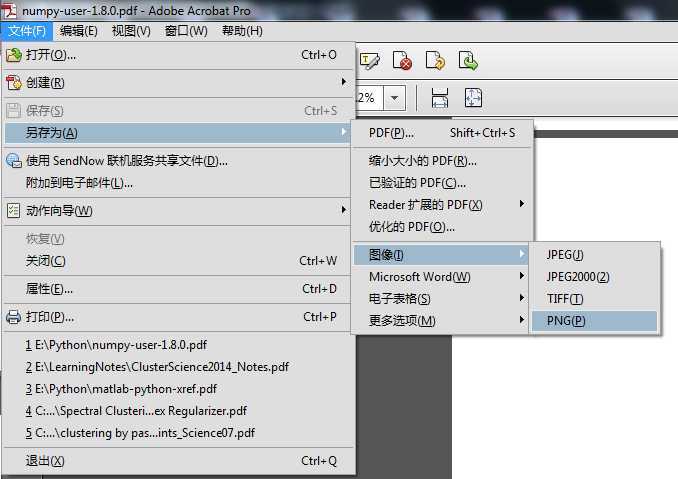
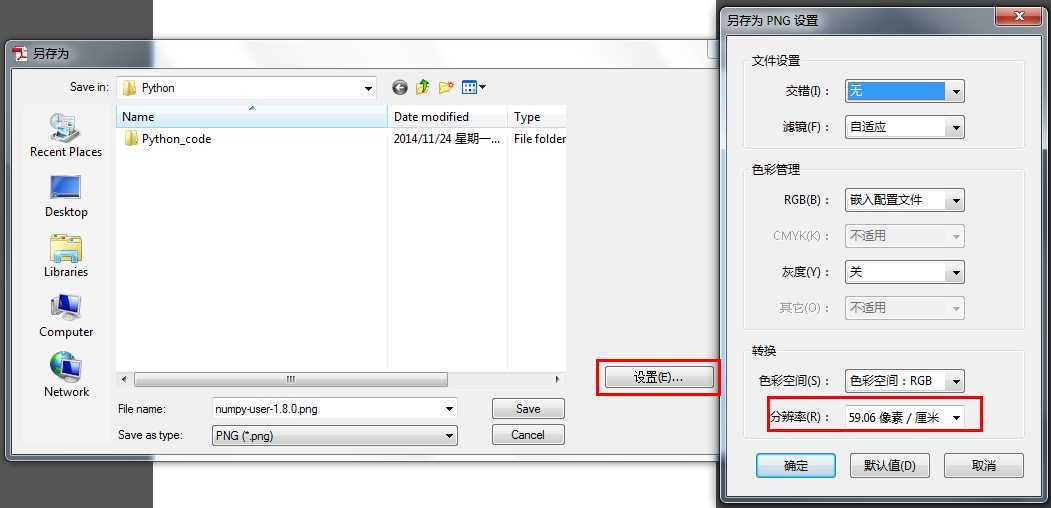
将PDF文档用Adobe Acrobat X Pro另存为图片后,就会在PDF文档所在的目录下生成一系列的名为“PDFfilename_页面_XX.png"的一系列图片。我们接下来的任务就是要将这些图片合并成一张图片。我选用了强大便捷的Python来完成这项任务。刚开始用matplotlib库来操作,可是最终发现matplotlib中的保存图片的函数(无论是Image.imsave()还是pyplot.imsave())都有一定的限制,那就是图片的长或宽都不能超过32768。这个限制让我很不满意,继续尝试其他的图像操作的库,最终发现PIL库不存在这个限制,问题也得到了解决。下面这段Python代码默认所有图片对应的顺序是文件名末尾序号的升序,序号可以不连续,能处理的图片名字必须是形如xx_1.png ... xx_100.png或者xx_001.png ... xx_100.png。最后短小精悍的Python代码如下:
#!/usr/bin/python3
#encoding=utf-8
import numpy as np
from PIL import Image
import glob,os
if __name__==‘__main__‘:
prefix=input(‘Input the prefix of images:‘)
files=glob.glob(prefix+‘_*‘)
num=len(files)
filename_lens=[len(x) for x in files] #length of the files
min_len=min(filename_lens) #minimal length of filenames
max_len=max(filename_lens) #maximal length of filenames
if min_len==max_len:#the last number of each filename has the same length
files=sorted(files) #sort the files in ascending order
else:#maybe the filenames are:x_0.png ... x_10.png ... x_100.png
index=[0 for x in range(num)]
for i in range(num):
filename=files[i]
start=filename.rfind(‘_‘)+1
end=filename.rfind(‘.‘)
file_no=int(filename[start:end])
index[i]=file_no
index=sorted(index)
files=[prefix+‘_‘+str(x)+‘.png‘ for x in index]
print(files[0])
baseimg=Image.open(files[0])
sz=baseimg.size
basemat=np.atleast_2d(baseimg)
for i in range(1,num):
file=files[i]
im=Image.open(file)
im=im.resize(sz,Image.ANTIALIAS)
mat=np.atleast_2d(im)
print(file)
basemat=np.append(basemat,mat,axis=0)
final_img=Image.fromarray(basemat)
final_img.save(‘merged.png‘)
标签:blog http ar os sp for 文件 on div
原文地址:http://www.cnblogs.com/jeromeblog/p/4119164.html