标签:blog http ar 使用 sp 数据 2014 log bs
在谈论数据库性能优化的时候,通常都会提到“索引”,但很多人其实并没有真正理解索引,也没有搞清楚索引为什么就能加快检索速度,以至于在实践中并不能很好的应用索引。事实上,索引是一种廉价而且十分有效的优化手段,设计优良的索引对查询性能提升确实能起到立竿见影的效果。
相信很多读者,都了解和使用过索引,可能也看过或者听过”新华字典“、”图书馆“之类比较通俗描述,但是对索引的存储结构和本质任然还比较迷茫。
有数据结构和算法基础的读者,应该都学过或者写过“顺序查找,二分查找(折半)查找,二叉树查找”这几种很经典的查找算法。其中,顺序查找效率是最低的,其算法复杂度为O(n),而二分查找算法复杂度为O(logn)但要求数据是必须为有序的,通常在链表中使用广泛。而二叉树查找的复杂度仅为O(log2n),但要求数据结构为“树”。如图所示:
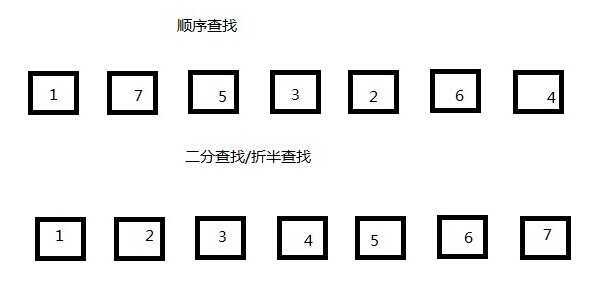
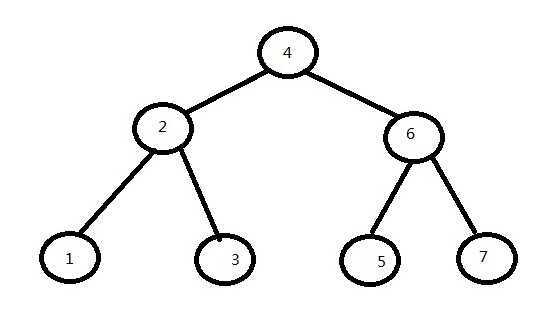
在主流的关系型数据库中,使用和支持最广泛的要属B-Tree索引。为了便于理解,且考虑到大部分读者数据结构知识有限,读者可以把B-Tree(或者其变种B+Tree)理解为特殊的二叉树。虽然这并不精确,但是相信读者看了之后,已经大致明白了为什么通过索引查找数据会比普通的表扫描会快很多。
sqlserver中的聚集索引
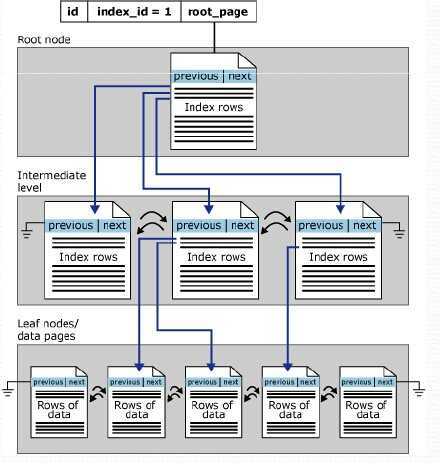
聚集索引的叶子节点(最底下的节点)直接包含了数据页。
sqlserver中的非聚集索引
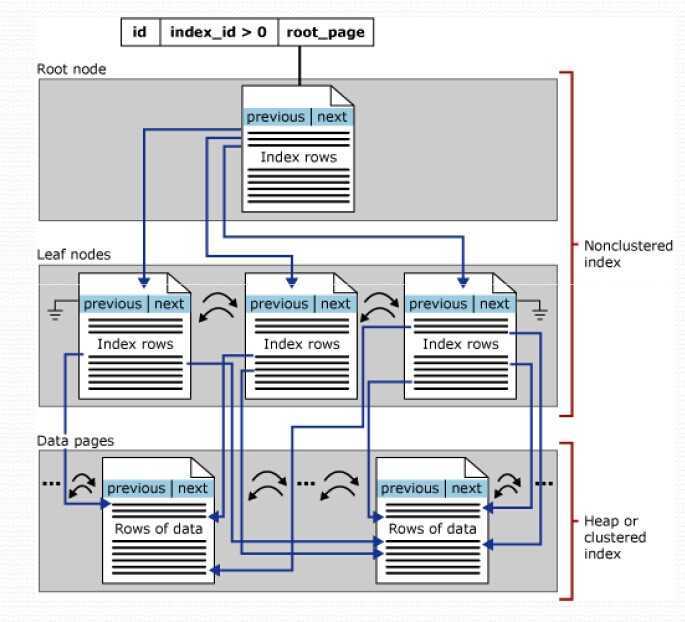
在有聚集索引的表中,非聚集索引的叶子节点,包含的是聚集索引的键值(可以理解为聚集索引的指针)。
在没有聚集索引的堆表中,非聚集索引包含的是RID(可以理解为数据行的指针)。
在mysql中,通常也有“聚集索引”(针对InnoDB引擎)和“非聚集索引”(针对MyIsam引擎),“主键索引"和”二级索引“。
mysql InnoDB引擎中的索引结构
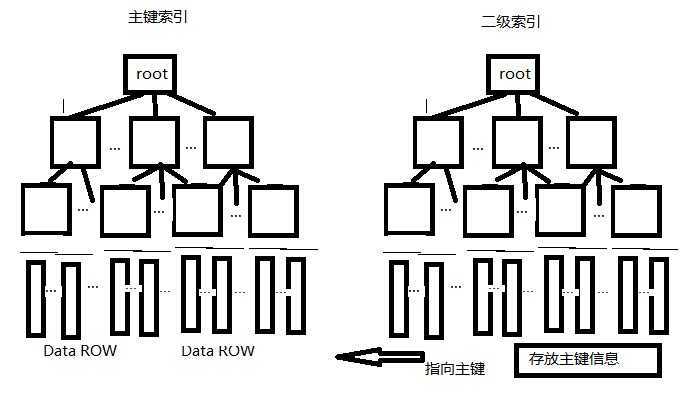
在主键索引中,叶子节点包含了数据行(数据页),二级索引的叶子界面,存放的是主键索引的键值(指向的主键索引)
mysql MyIsam引擎中的索引结构
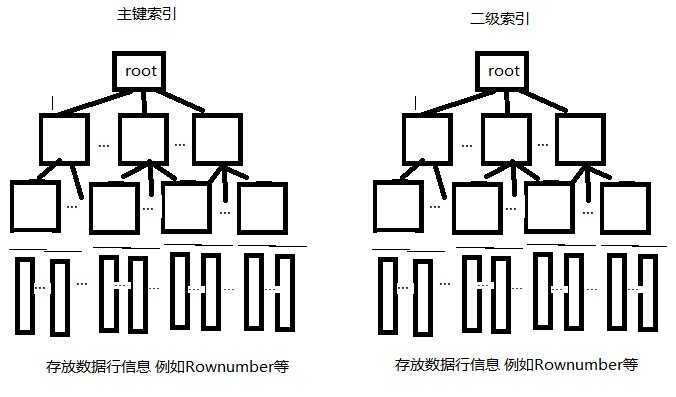
主键索引与二级索引结构上没有太大的区别,叶子节点都保存的数据行信息(例如row number等)可以直接指向并定位到数据行
相信读者不难看出,B-Tree索引在sqlserver和mysql中的结构、存储方式、原理都是大致相同的。当然,也有很多细节和内部实现上的差异。
限于笔者水平和理解有限,文中全部文字和描述等全凭笔者记忆写出,难免出现错误,敬请热心的读者及时批评和指正。
由于时间有限,大部分图片笔者画的比较粗糙,也请读者谅解。
本文出自http://blog.csdn.net/dinglang_2009,转载请注明出处。
标签:blog http ar 使用 sp 数据 2014 log bs
原文地址:http://www.cnblogs.com/dinglang/p/4127323.html