标签:winform style blog http io ar color os 使用
一 本系列随笔概览及产生的背景
自己开发的豆约翰博客备份专家软件工具问世3年多以来,深受广大博客写作和阅读爱好者的喜爱。同时也不乏一些技术爱好者咨询我,这个软件里面各种实用的功能是如何实现的。
该软件使用.NET技术开发,为回馈社区,现将该软件中用到的核心技术,开辟一个专栏,写一个系列文章,以飨广大技术爱好者。
本系列文章除了讲解网络采编发用到的各种重要技术之外,也提供了不少问题的解决思路和界面开发的编程经验,非常适合.NET开发的初级,中级读者,希望大家多多支持。
很多初学者常有此类困惑,“为什么我书也看了,C#相关的各个方面的知识都有所了解,但就是没法写出一个像样的应用呢?”,
这其实还是没有学会综合运用所学知识,锻炼出编程思维,建立起学习兴趣,我想该系列文章也许会帮到您,但愿如此。
开发环境:VS2008
本节源码位置:https://github.com/songboriceboy/GatherAll
源码下载办法:安装SVN客户端(本文最后提供下载地址),然后checkout以下的地址:https://github.com/songboriceboy/GatherAll
系列文章提纲拟定如下:
二 第五节主要内容简介(将任意博主的全部博文下载到内存中并通过Webbrower显示)
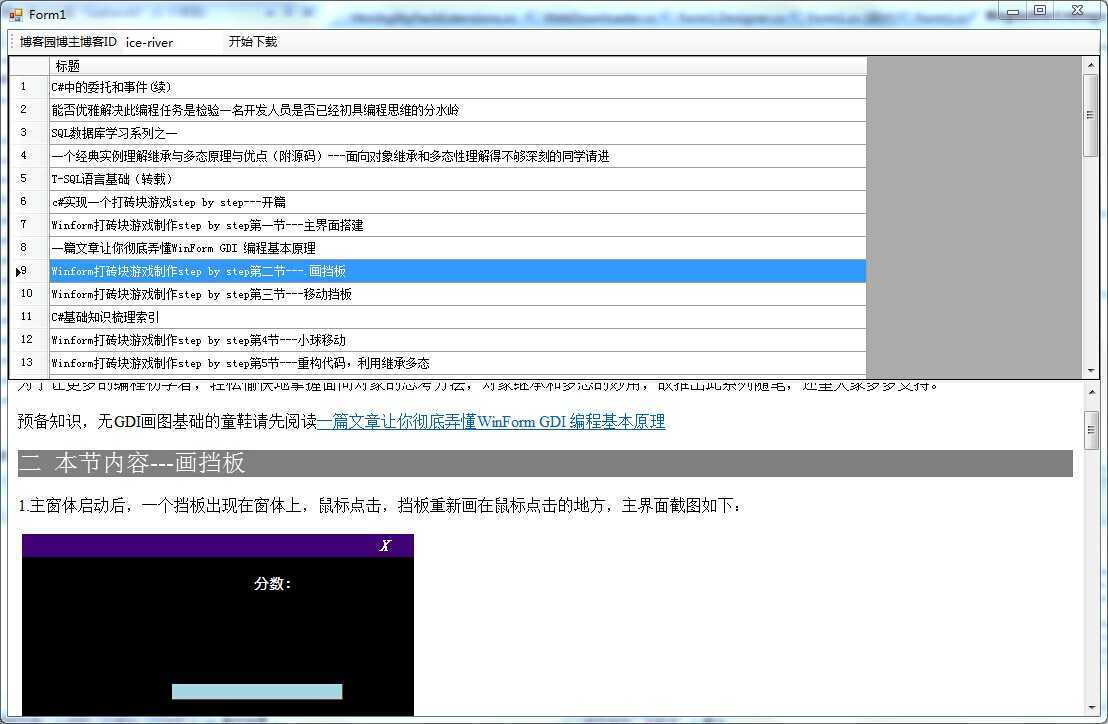
将任意博主的全部博文下载到内存中并通过Webbrower显示的解决方案,演示demo如下图所示:可执行文件下载
三 基本原理
本节我们提供了一个示例将本系列中的第一节和第二节的内容综合到一起,实现下载博客园任意博主的全部博文功能。用户只要在编辑框中输入博客园任意博主的ID,该博主的全部文章就会被下载到内存中,我们本节就来剖析一下实现原理。
采集博文的结构图如下所示:
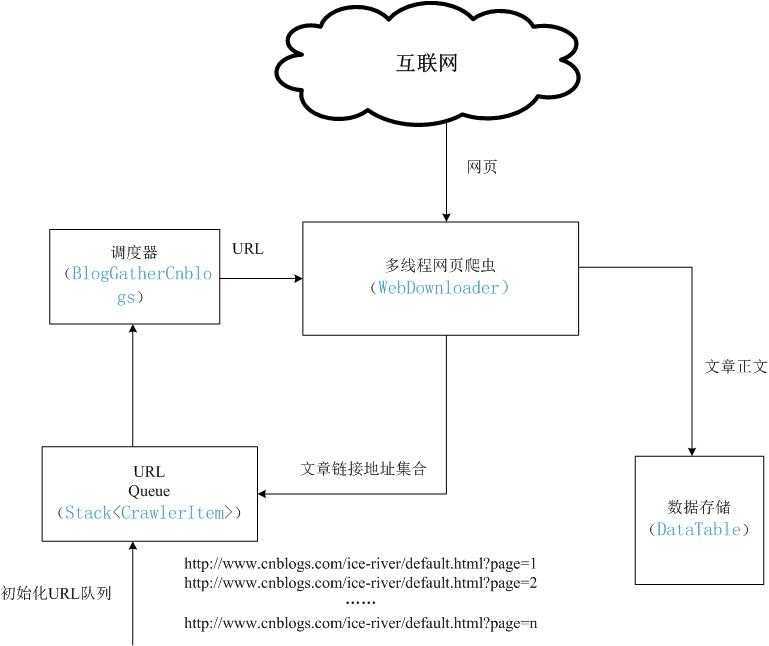
总体步骤如下:
1.用分页地址初始化Url队列(其实是一个堆栈数据结构),具体请参考本系列第一节内容;
2.调度器不断从Url队列中取得url,从网上获取该url对应的网页正文;
3.多线程的网页爬虫分析下载到的网页正文是链接提取页还是文章正文页;
(1)若为链接提取页面,则提取全部符合规则的文章链接,然后压入到前面的Url队列中(其实是堆栈操作,这里可以理解为,一个分页页面地址换取了几十个文章链接地址,接下来调度器将取得的链接是这几十个文章链接地址,全部下载完,存储到数据存储后,接下来才会轮到取第二个分页页面,这点大家可以对照提供的代码自行理解,此处是网络爬虫的精髓)。
(2)若为文章正文页,则按照正文css路径,提取出正文,存储到数据存储中(本节为datatable中),具体可参考本系列第二节内容。
4.递归的执行第2步和第3步,直至Url队列为空或已经判断出全部文章下载完毕(参见第一节)时,程序结束。
核心代码如下:
private void ParseWebPage(string strVisitUrl, string strPageContent, DoWorkEventArgs e) { string strUrlFilterRule = GetUrlFilterRule(); if (!IsFinalPage(strVisitUrl, strUrlFilterRule)) { bool bNoArticle = SaveUrlToDB(strVisitUrl, strPageContent, e); if (!bNoArticle) { BlogGatherNext(e); } } else { if (strPageContent != "") { string strTitle = SaveFinalPageContent("" , GetMainContentCss(), strVisitUrl, strPageContent); } BlogGatherNext(e); } }
IsFinalPage(strVisitUrl, strUrlFilterRule),该行代码根据本次请求的url和文章链接的url规则来判断当前获取的页面是最终文章页还是文章链接提取页,其实现代码如下:
protected bool IsFinalPage(string strVisitUrl, string strUrlFilterRule) { bool bRet = false; MatchCollection matchsTemp = Regex.Matches(strVisitUrl.ToString(), strUrlFilterRule, RegexOptions.Singleline); if (matchsTemp.Count > 0) { bRet = true; } return bRet; }
补充说明,何谓链接提取页?如下图所示即是:

更详细的代码请自行下载研究。
网络采集软件核心技术剖析系列(5)---将任意博主的全部博文下载到内存中并通过Webbrower显示(将之前的内容综合到一起)
标签:winform style blog http io ar color os 使用
原文地址:http://www.cnblogs.com/ice-river/p/4130514.html