标签:blog http ar os 使用 sp strong on 数据
原文:《BI那点儿事》Microsoft 聚类分析算法——三国人物身份划分什么是聚类分析? 
聚类分析属于探索性的数据分析方法。通常,我们利用聚类分析将看似无序的对象进行分组、归类,以达到更好地理解研究对象的目的。聚类结果要求组内对象相似性较高,组间对象相似性较低。在三国数据分析中,很多问题可以借助聚类分析来解决,比如三国人物身份划分。
聚类分析的基本过程是怎样的? 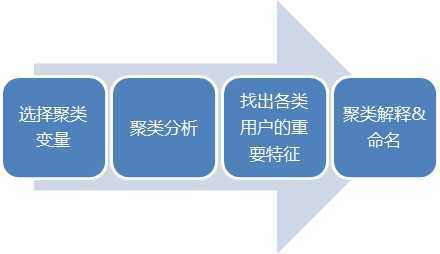
在分析三国人物身份的时候,我们会根据一定的假设,尽可能选取对角色身份有影响的变量,这些变量一般包含与身份密切相关的统率、武力、智力、政治、魅力、特技、枪兵、戟兵、弩兵、骑兵、兵器、水军等。但是,聚类分析过程对用于聚类的变量还有一定的要求:
这些变量在不同研究对象上的值具有明显差异;
这些变量之间不能存在高度相关。
因为,首先,用于聚类的变量数目不是越多越好,没有明显差异的变量对聚类没有起到实质意义,而且可能使结果产生偏差;其次,高度相关的变量相当于给这些变量进行了加权,等于放大了某方面因素对用户分类的作用。
识别合适的聚类变量的方法:
对变量做聚类分析,从聚得的各类中挑选出一个有代表性的变量;
做主成份分析或因子分析,产生新的变量作为聚类变量。
相对于聚类前的准备工作,真正的执行过程显得异常简单。数据准备好后,丢到分析软件(通常是分析服务)里面跑一下,结果就出来了。
这里面遇到的一个问题是,把人物分成多少类合适?通常,可以结合几个标准综合判断:
1. 看拐点
2. 凭经验或人物特性判断
3. 在逻辑上能够清楚地解释
确定一种分类方案之后,接下来,我们需要返回观察各类别三国人物在各个变量上的表现。根据差异检验的结果,我们以颜色区分出不同类用户在这项指标上的水平高低。
在理解和解释用户分类时,最好可以结合更多的数据,例如,三国志12数据等……最后,选取每一类别最明显的几个特征为其命名,就大功告成啦!
下面我们进入主题,同样我们继续利用上次的解决方案,依次步骤如下: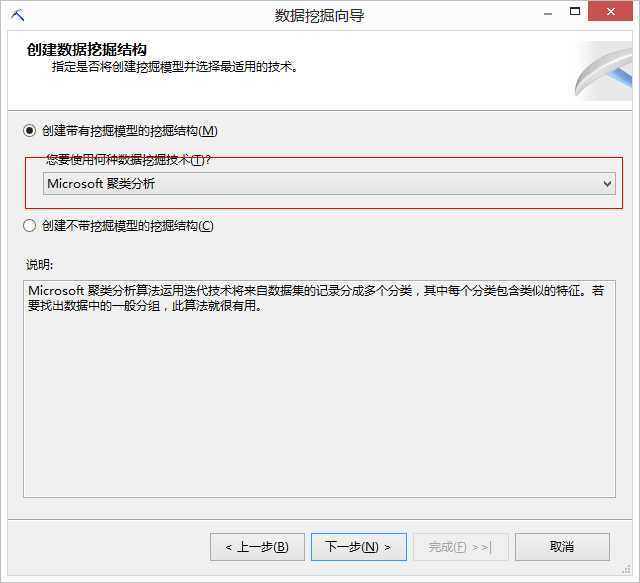
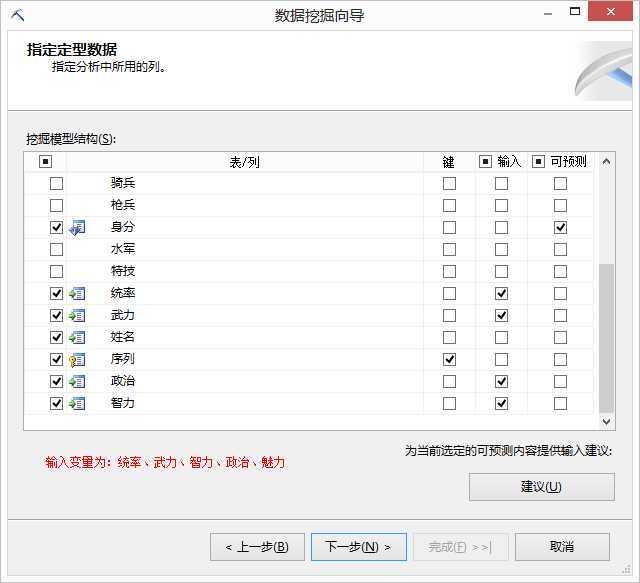
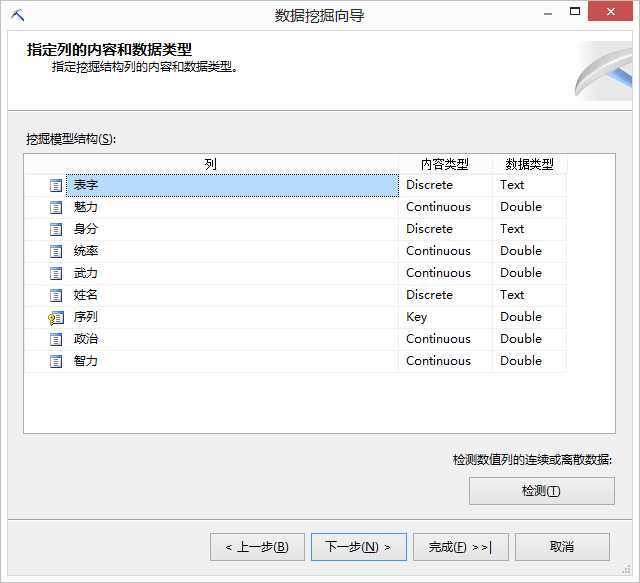
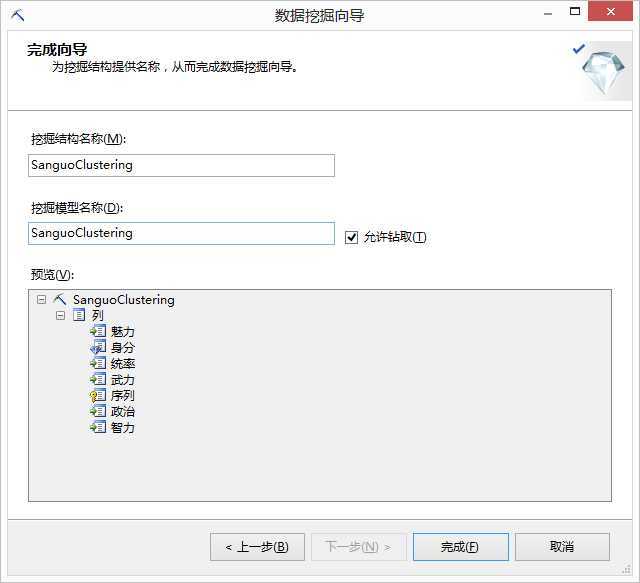
在挖掘模型中,主要是列出所建立的挖掘模型,也可以新增挖掘模型,并调整变量,变量使用情况包含Ignore(忽略)、Input(输入变量)、Predict(预测变量、输入变量)以及PredictOnly(预测变量),如图所示: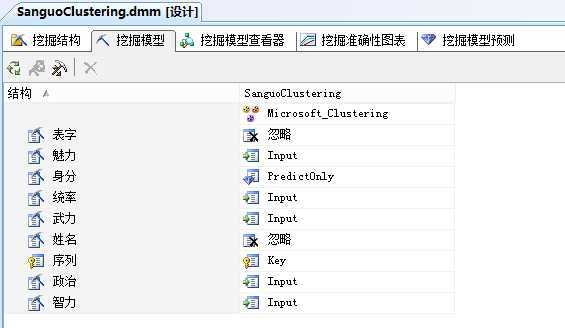
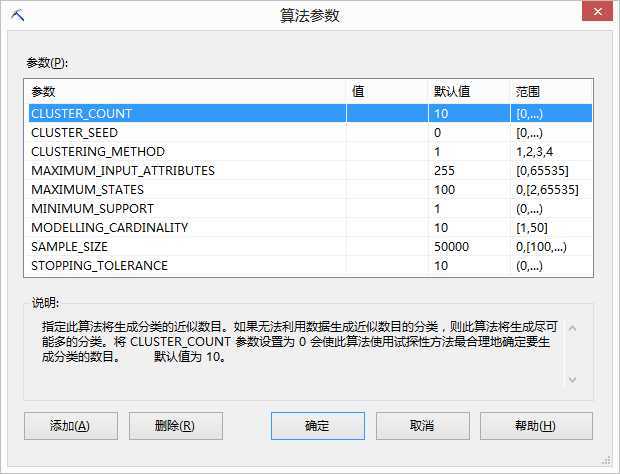
而在挖掘模型上点击鼠标右键,选择“设置算法参数”针对方法论的参数设置加以编辑,其中包含:
CLUSTER_COUNT:指定算法所要建立的聚类的近似数目。如果无法从数据中建立聚类的近似数目,算法便会尽可能建立聚类。若将CLUSTER_COUNT设置为0,则算法便会使用启发式决定所应建立的聚类数目,默认值为10。
CLUSTER_SEED:指定在模型建立的初始阶段,用于随机产生聚类的种子数。
CLUSTERING_METHOD:算法使用的聚类方法可以是可扩展的EM(1)、不可扩充的EM(2)、可扩充的K-means(3)或不可扩充的K-means(4)。
MAXIMUM_INPUT_ATTRIBUTE:指定在调用功能选项之前,算法可以处理输入属性的最大数目。将此值设置为0,会指定没有属性最大数目的限制。
MAXIMUM_STATES:指定算法所支持属性状态的最大数目。如果属性拥有的状态数目大于状态的最大数目,算法会使用属性最常用的状态并将其他的状态视为遗漏。
MINIMUM_SUPPORT:此参数指定每个聚类中的最小案例数目。
MODELLING_CARDINALITY:此参数指定聚类处理期间建构的范例模型数目。
SAMPLE_SIZE:指定如果CLUSTERING_METHOD参数设置为可扩充的聚类方法时,算法使用在每个行程上的案例数目。将SAMPLE_SIZE设置为0会导致整个数据集在单一进程中聚类,如此可能会造成内存和效率的问题。
STOPPING_TOLERANCE:指定用来决定何时到达聚合以及算法完成建立模型的值。当聚类概率的整体变更小于SHOPPING_TOLERANCE除以模型大小的比率时,就到达聚合。
挖掘模型查看器则是呈现此聚类分析结果,其中聚类图表则是表现各类关联性的强弱,对于数据的分布进一步加以了解。而在每一聚类结点上,点击右键,再出现的菜单上选择“钻取”,则可以浏览属于这一类的样本数据特征。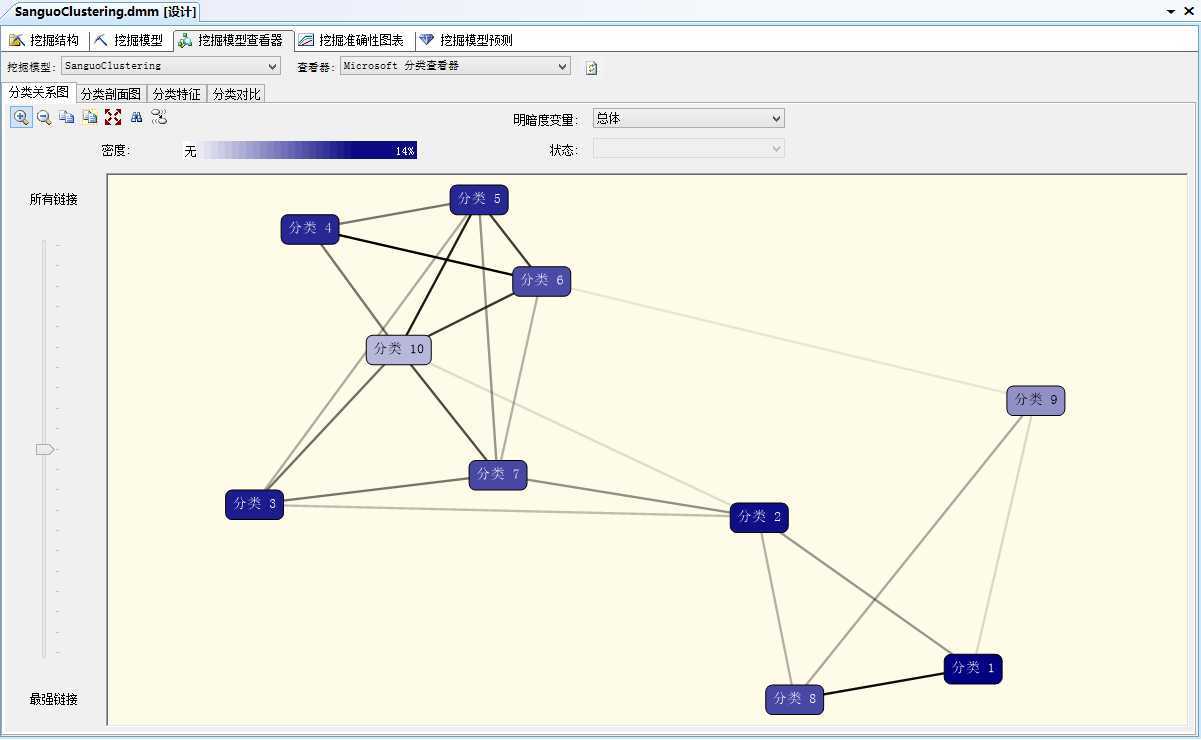
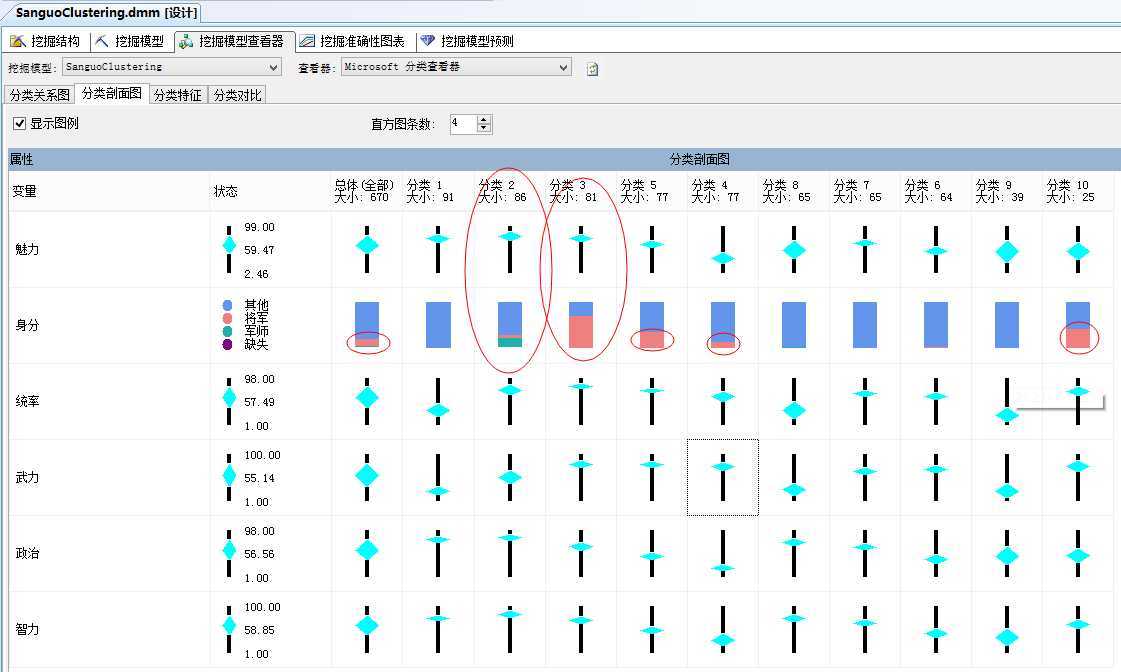
从“分类剖面图”了解因变量与自变量间的关联性强弱程度,如图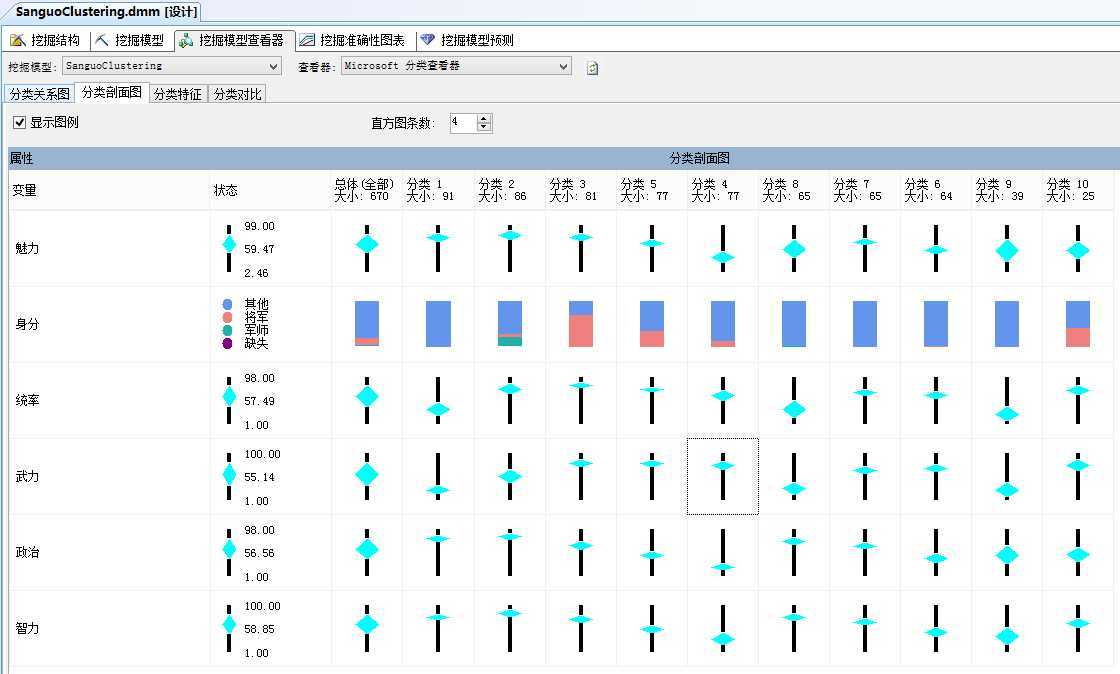
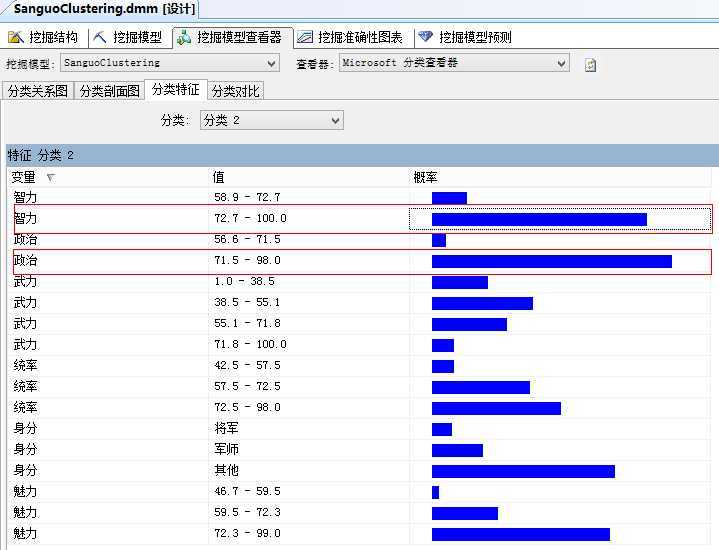
“分类特性”主要是呈现每一类的特性,见图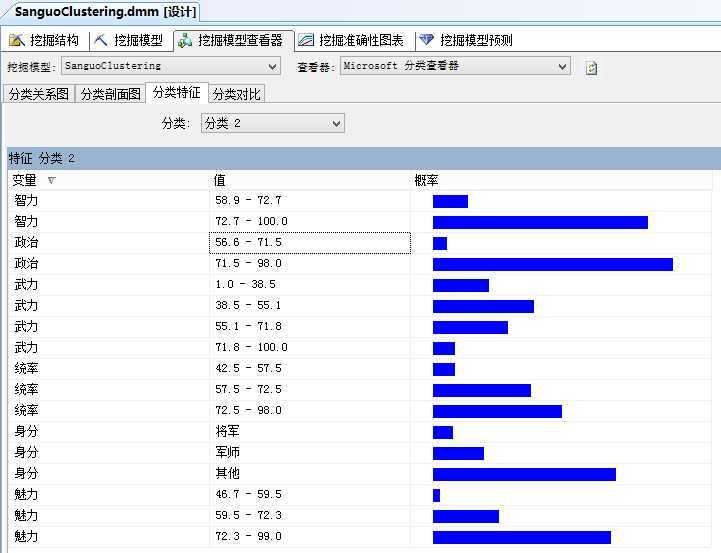
在“分类对比”上,主要就是呈现出两类间特性的比较,如图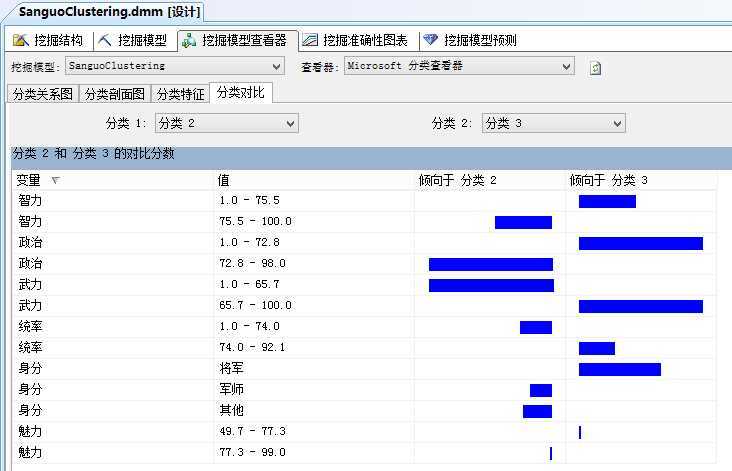
参考文献:
Microsoft 聚类分析算法
http://msdn.microsoft.com/zh-cn/library/ms174879.aspx
《BI那点儿事》Microsoft 聚类分析算法——三国人物身份划分
标签:blog http ar os 使用 sp strong on 数据
原文地址:http://www.cnblogs.com/lonelyxmas/p/4136622.html