标签:blog http io ar os 使用 sp java strong
每天,都有数以亿万计的JPEG图片、HTML页面、文本文件、MPEG电影、WAV音频文件、Java小程序和其他资源在因特网上游弋。HTTP可以从遍布全世界的Web服务器上将这些信息快速、便捷、可靠的搬移到人们桌面上的Web浏览器上去。
HTTP,全称Hyper Text Transport Protocal,即超文本传输协议,定义了浏览器如何向服务器请求文档以及服务器怎样把文档传送给浏览器,它是万维网能够可靠的交换文件(包括文本,声音,图像等多种多媒体文件)的基础。
超文本传输协议的前身是Xanadu项目,超文本的概念是Ted Nelson在1960年代提出的。1989年,Tim Berners Lee在CERN担任软件咨询师的时候,开发了一套程序,奠定了万维网的基础。1990年12月,超文本在CERN首次上线。1991年夏天,继Telnet等协议之后,超文本转移协议成为了互联网诸多协议的一份子。
1、支持客户/服务器模式。支持基本认证 和安全认证。
客户端/服务器(client/server)这个术语可追溯到上个千年(20世纪80年代),表示通过网络连接起来的个人计算机。客户端/服务器也可用于描述两个计算机程序的关系--客户程序和服务器程序。客户向服务器请求某种服务(比如请求一个文件或数据库访问),服务器满足请求并通过网络将结果传送给客户端。虽然客户端和服务器程序可存在于同一台计算机中,但它们通常都运行在不同计算机上。一台服务器处理多个客户端请求也是很常见的。
最常见的Web客户端就是浏览器了,一次请求/响应的模型如下图所示:
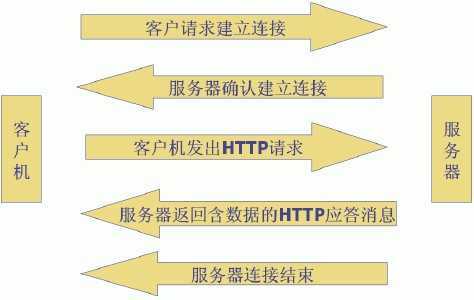
这里需要说明的一点是,每次访问一个静态资源,比如一个html文件,一个png图片或者一个文本文档都会向服务器发出一个HTTP请求,每个HTTP请求都会经历上图的请求/响应模型。比如我们点开http://www.taobao.com/(淘宝网),我们会往服务器发送成百上千个HTTP请求,收到来自客户端的请求后,服务器会去寻找相应的资源,如果成功,就将对象,对象类型,对象长度以及其他信息放在HTTP响应中发回客户端。那么问题来了,服务器怎么去寻找相应的资源,凭据是什么?
URL是浏览器寻找信息时所需要的资源位置。通过URL,人类和应用程序才能找到使用并共享因特网上大量的数据资源。URL是人们对HTTP和其他协议的常用访问点:在浏览器中输入一串URL,浏览器就会在幕后发送适当的协议报文来获取人们所期望的资源。
大多数的URL方案的URL语法都建立在这个由9部分的通用格式上:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
几乎没有哪个URL中包含了所有这些组件。URL最重要的3个部分是方案(scheme)、主机(host)和路径(path)。

目前常见的协议类型有很多种,常用的有http,https(更安全的http),mailto(邮件),ftp(文件传输),rtsp(音频视频),file,news,telnet等等
HTTP报文是在HTTP应用程序之间发送的数据块。这些数据块以一些文本形式的元信息开头,这些信息描述了报文的内容和含义,后面跟着可选的数据部分。
HTTP报文是简单的格式化数据块。每一条报文都包含一条来自客户端的请求,或者来自服务器的响应。它们有三个部分组成:对报文进行描述的起始行(start line)、包含属性的首部块(header),以及可选的、包含数据的主体部分(body)。
HTTP/1.0 200 OK //起始行 Content-type:text/plain //首部 Content-length:19 //首部 Hi I‘m a message! //主体
所有的HTTP报文可以分为两类:请求报文(request message)和响应报文(response message)。请求报文会向服务器发送一个请求,响应报文会将结果返回个客户端。
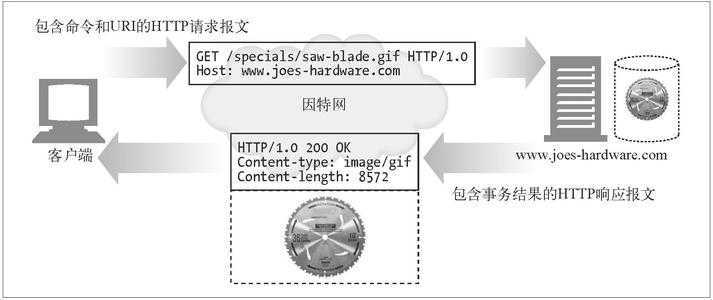
请求报文的格式:
<method> <request-UTL> <version> <headers> <entity-body>
响应报文格式:
<version> <status><reason-phrase> <header> <entity-body>
下面是对格式中各部分的简要描述
1、方法(method) GET
客户端希望服务器对资源执行的动作。是一个单独的词,比如GET、HEAD或POST。
2、请求的URL(request-URL)
命名了所有请求资源,或者URL路径组件的完整URL。如果直接与服务器进行对话,只要URL的路径组件是资源的绝对路径,通常就不会有什么问题--服务器可以假定 义自己是URL的主机/端口。
3、版本(version) HTTP/1.1
报文所使用的HTTP版本,其格式如下:
HTTP/<major>.<minor>
其中主要版本号(major)和次要版本号(minor)都是整数。
4、状态码(status)
这三个数字描述了请求过程中所发生的情况。每个状态码的第一位数字都用于描述状态的一般类别("成功"、"出错"等)。
5、原因短语(reason-phrase)
数字状态码的可读版本,包含行终止序列之前的所有文本。原因短语只是给人类看的,它不能说明什么。客户端依然采用状态码来判断请求/响应是否成功!
例如:HTTP/1.0 200 NOT OK 客户端依然会当请求已成功处理。因为状态码是200。而原因短语只是说明而已,这对于自定义扩展状态码还是比较有用的。
6、首部(header)
可以有0个或多个首部,每个首部都包含一个名字,后面跟着一个冒号(:),然后是一个可选的空格,接着是一个值,最后是一个CRLF。首部是由一个空行(CRLF)结束 的,表示了首部列表的结束和实体主体的开始。
7、实体的主体部分(entity-body)
实体的主体部分包含一个由任意数据组成的数据块。并不是所有的报文都包含实体的主体部分。如GET请求就不包含实体。
标签:blog http io ar os 使用 sp java strong
原文地址:http://www.cnblogs.com/jones-c/p/4149718.html