标签:style blog http io ar color os 使用 sp
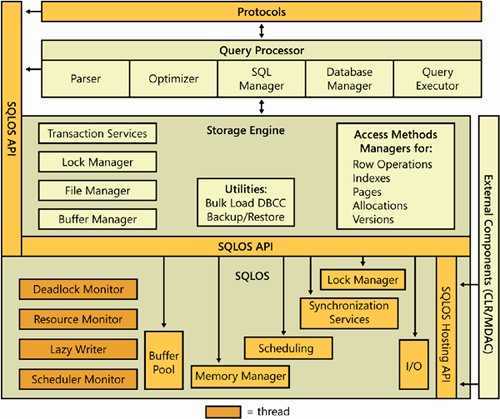
原文:人人都是 DBA(I)SQL Server 体系结构在了解 SQL Server 数据库时,可以先从数据库的体系结构来观察。SQL Server 的体系结构中包含 4 个主要组成部分:
当应用程序与 SQL Server 数据库通信时,首先需要通过 SNI(SQL Server Network Interface)网络接口选择建立通信连接的协议。可以使用以下协议:
可以对 SQL Server 进行配置,使其可以同时支持多种协议。各种协议在不同的环境中有着不同的性能表现,需要根据性能需求选择合适的协议。如果客户端并未指定使用哪种协议,则可配置逐个地尝试各种协议。
连接建立后,应用程序即可与数据库进行直接的通信。当应用程序准备使用 T-SQL 语句 "select * from TableA" 向数据库查询数据时,查询请求在应用程序侧首先被翻译成 TDS 协议包(TDS:Tabular Data Stream 即表格格式数据流协议),然后通过连接的通信协议信道发送至数据库一端。
SQL Server 协议层接收到请求,并将请求转换成关系引擎(Relational Engine)可以处理的形式。
关系引擎(Relational Engine)也称为查询处理器(Query Processor),主要包含 3 个部分:
协议层将接收到的 TDS 消息解析回 T-SQL 语句,首先传递给命令解析器(Command Parser)。
命令解析器(Command Parser)检查 T-SQL 语法的正确性,并将 T-SQL 语句转换成可以进行操作的内部格式,即查询树(Query Tree)。
查询优化器(Query Optimizer)从命令解析器处得到查询树(Query Tree),判断查询树是否可被优化,然后将从许多可能的方式中确定一种最佳方式,对查询树进行优化。
优化步骤首先进行规范查询(Normalize Query),可以将单个查询分解成多个细粒度的查询,并对细粒度的查询进行优化,这意味着它将为执行查询确定计划,所以查询优化器的结果是产生一个执行计划(Execution Plan)。
查询优化是基于成本的(Cost-based)考量的,也就是说,选择成本效益最高的计划。查询优化器需要根据内部记录的性能指标选择消耗最少的计划。这些内部性能指标包括:Memory 需求、CPU 利用率和 I/O 操作数量等。同时,查询优化还使用启发式算法(Pruning Heuristics),以确保评估优化及查询的时间消耗不会比直接执行未优化查询的时间更长。
在完成查询的规范化和最优化之后,这些过程产生的结果将被编译成执行计划(Execution Plan)数据结构。执行计划中包括查询哪张表、使用哪个索引、检查何种安全性以及哪些条件为何值等信息。
查询执行器(Query Executor)运行查询优化器(Query Optimizer)产生的执行计划,在执行计划中充当所有命令的调度程序,并跟踪每个命令执行的过程。大多数命令需要与存储引擎(Storage Engine)进行交互,以检索或修改数据等。
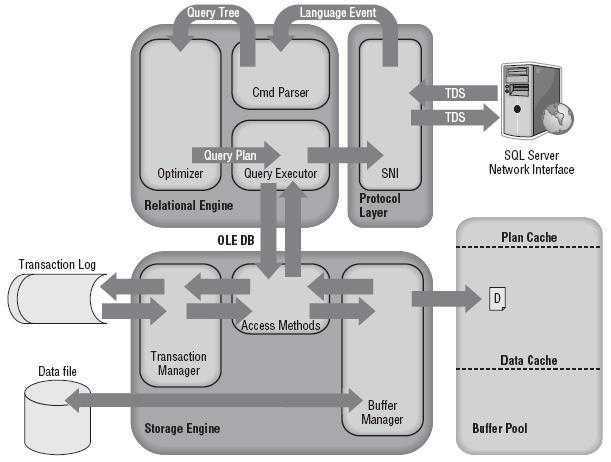
SQL Server 存储引擎中包含负责访问和管理数据的组件,主要包括:
访问方法(Access Methods)包含创建、更新和查询数据的具体操作,下面列出了一些访问方法类型:
访问方法并不直接检索页面,它向缓冲区管理器(Buffer Manager)发送请求,缓冲区管理器在其管理的缓存中扫描页面,或者将页面从磁盘读取到缓存中。在扫描启动时,会使用预测先行(Look-ahead Mechanism)机制对页面中的行或索引进行验证。
锁管理器(Lock Manager)用于控制表、页面、行和系统数据的锁定,负责在多用户环境下解决冲突问题,管理不同类型锁的兼容性,解决死锁问题,以及根据需要提升锁(Escalate Locks)的功能。
事务服务(Transaction Services)用于提供事务的 ACID 属性支持。ACID 属性包括:
预写日志(Write-ahead Logging)功能确保在真正发生变化的数据页写入磁盘前,始终先在磁盘中写入日志记录,使得任务回滚成为可能。写入事务日志是同步的,即 SQL Server 必须等它完成。但写入数据页可以是异步的,所以可以在缓存中组织需要写入的数据页进行批量写入,以提高写入性能。
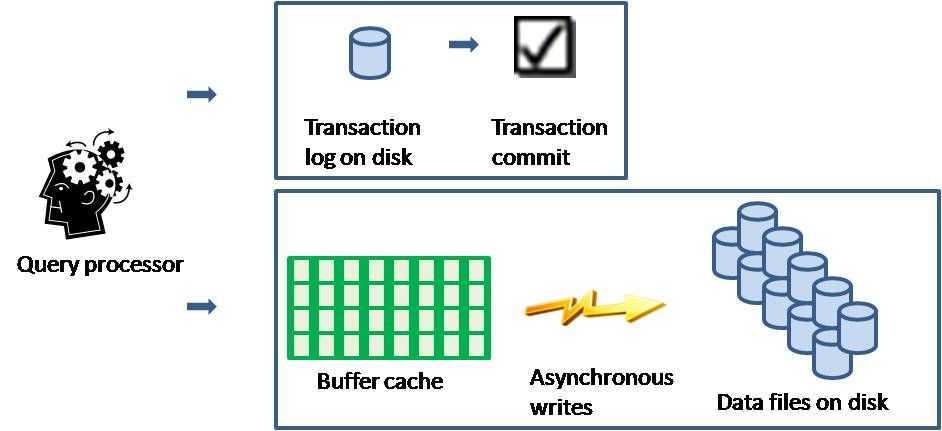
SQL Server 支持两种并发模型来保证事务的 ACID 属性:
在乐观并发模型中,用户读数据时不锁定数据。在执行更新时,系统进行检查,查看另一个用户读过数据后是否更改了数据。如果另一个用户更改了数据,则产生一个错误,接收错误信息的用户将回滚事务。该模型主要用在数据争夺少的环境中,以及锁定数据的成本超过回滚事务的成本时。
SQL Server 提供了 5 中隔离级别(Isolation Level),在处理多用户并发时可以支持不同的并发模型。
实用工具(Controlling Utilities)中包含用于控制存储引擎的工具,如批量加载(Bulk-load)、DBCC 命令、全文本索引管理(Full-text Index Management)、备份和还原命令等。
SQLOS 是一个单独的应用层,位于 SQL Server 引擎的最低层。SQLOS 的主要功能包括:
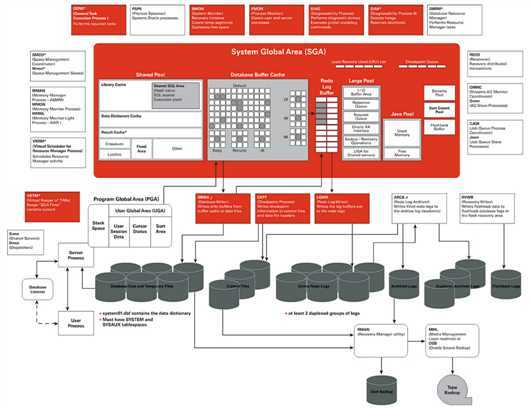
实际上,如果从体系结构的整体上来比较,各种常见的关系型数据库的体系结构都是差不多的。这也使得我们在了解一种数据库后,可以大体的猜测和快速理解另一种数据库。
下面是 Oracle 数据库的架构图:
下面是 MySQL 数据库的结构图:
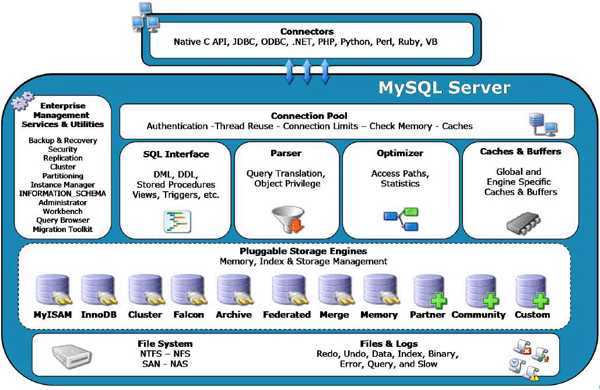
MySQL 数据库在存储引擎部分实现了可插拔式设计(Pluggable Storage Engines),可以根据需求不同选择不同类型的存储引擎实现。
甚至在同一个数据库实例中,每张数据表都可以指定使用哪种存储引擎。
CREATE TABLE customers (a INT, b CHAR (20), INDEX (a)) ENGINE=InnoDB;
《人人都是 DBA》系列文章索引:
本系列文章《人人都是 DBA》由 Dennis Gao 发表自博客园个人技术博客,未经作者本人同意禁止任何形式的转载,任何自动或人为的爬虫转载或抄袭行为均为耍流氓。
标签:style blog http io ar color os 使用 sp
原文地址:http://www.cnblogs.com/lonelyxmas/p/4155533.html