标签:style blog http io ar os sp java on
1.http编程知识
client和server建立可靠的tcp链接(在HTTP1.1中这个链接是长时间的,超时断开策略)
client通过socket与server通信,发送request并接受response
http协议是无状态的,是指每一条的请求是相互独立的,client和server都不会记录客户的行为。
client通过在HTTP请求中添加headers告诉server 他请求的内容,可以接受的格式
Get:client请求一个文件
Post:client发送数据让server处理
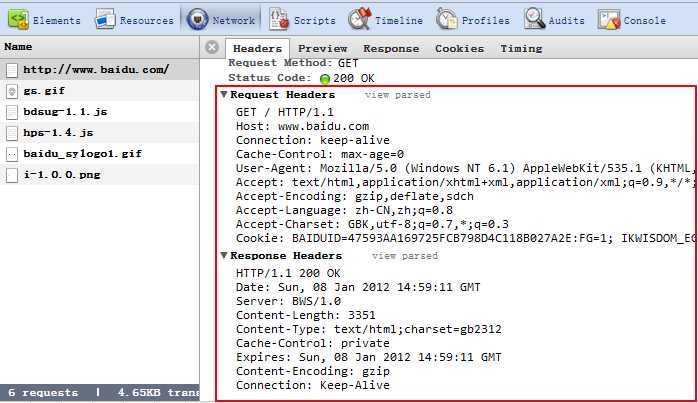
如上图,输入http://www.baidu.com/
得到的request headers是:
Get :请求方式 / 表示根目录 HTTP/1.1表示采用的协议版本
HOST:请求的主机
Connection:保持长连接,
Cache-control:缓存相关
User-agent:告诉server我client的身份,包括浏览器版本等
Accept:支持的内容类型,先后次序表示浏览器依次加载的先后顺序
Accept-encoding:允许服务器以一下几种的压缩的格式对传输内容进行压缩
Accept-language:展示返回信息所采用的语言
Accept-charset:浏览器支持的字符编码集
Cookie:缓存相关
参考博客:
http://technique-digest.iteye.com/blog/1174581
http://www.cnblogs.com/ShaYeBlog/archive/2012/09/11/2680485.html
http://blog.csdn.net/bingjing12345/article/details/9819731
2. urllib2 相关内容
class urllib2.Request(url[, data][, headers][, origin_req_host][, unverifiable])
URL:应该是一个字符串
Data:是一个经过urllib.urlencode()编码的编码后字符串
Headers:用来哄骗user_agent,把来自script访问伪装成浏览器的访问。
示例代码:
|
import urllib import urllib2 url = ‘http://www.someserver.com/cgi-bin/register.cgi‘ user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ values = {‘name‘ : ‘WHY‘, ‘location‘ : ‘SDU‘, ‘language‘ : ‘Python‘ } headers = { ‘User-Agent‘ : user_agent } data = urllib.urlencode(values) req = urllib2.Request(url, data, headers) response = urllib2.urlopen(req) the_page = response.read() |
参考博客:http://blog.csdn.net/pleasecallmewhy/article/details/8923067
3. 把如下代码保存成html格式,用相应的浏览器打开,得到浏览器的版本信息
|
<html><head></head><body><script language="javascript">javascript:alert(navigator.userAgent); </script></body></html> |
搜狗浏览器的user_agent
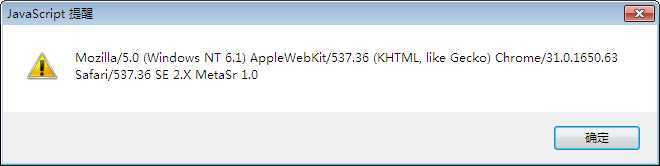
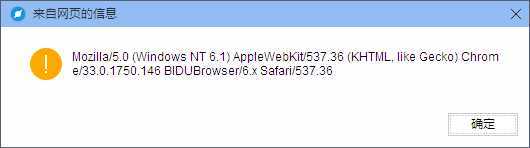
百度浏览器的user_agent
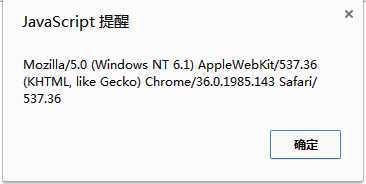
Google chorme的user_agent
标签:style blog http io ar os sp java on
原文地址:http://www.cnblogs.com/superbingbing/p/4157231.html