标签:des style blog http io ar color os 使用
?
由于官方版本的Hadoop是32位,若在64位Linux上安装,则必须先重新在64位环境下编译Hadoop源代码。本环境采用编译后的hadoop2.5.1 。
安装参考博客:
1 http://www.micmiu.com/bigdata/hadoop/hadoop2x-cluster-setup/
2 http://f.dataguru.cn/thread-18125-1-1.html
3 http://blog.sina.com.cn/s/blog_611317b40100t5od.html
?
环境搭建:
物理机win7
虚拟机vmware10+3台ubuntu12.04 64位(可以配置好一台然后完全复制另外两台)
虚拟机采用NAT模式上网,
{ 在Virtual Network Editor中将Subnet IP设为192.168.23.0
为虚拟机配置静态Ip
autho eht0
iface eth0 inet static
address 192.168.23.5
gateway 192.168.23.2
netmask 255.255.255.0
network 192.168.23.0
broadcast 192.168.23.255
配置虚拟机DNS
在/etc/resolvconf/resolv.conf.d/base以及/etc/resolv.conf中加入
nameserver 8.8.8.8
虚拟机端口映射
将虚拟机的22(ssh)端口应射成主机的8841端口,以后ssh远程访问虚拟机都用主机的端口访问
Sudo vi /etc/vmware/vmnet8/nat/nat.conf
在[incomingtcp]下加入
8421=192.168.23.5:22
需要注意的是再加入端口之前要查看端口是否占用
Netstat –ap|grep 8421
} 这部分我安装时没有关心。
安装好虚拟机,为方便设置: 用户名:hadoop 主机名分别为:master 、slave1、slave2
配置各台虚拟机的ip:
Ipconfig :查看各个虚拟机的ip,没台机器就可以取这个ip。
hostname | IP | 用途 |
master | 192.168.164.133 | NameNode/ResouceManager |
Slave1 | 192.168.164.134 | DataNode/NodeManager |
slave2 | 192.168.164.135 | DataNode/NodeManager |
?
?
?
?
?
?
ps:如果是虚拟机可以把环境配置好后,copy多个实例即可,需要注意修改hostname
?
1 vi /etc/hosts??添加如下内容:
192.168.164.133 master
192.168.164.134 slave1
192.168.164.135 slave2
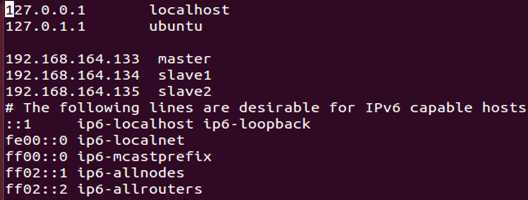
?
这里可能hosts和hostname是只读权限
给只读文件添加权限:
sudo chmod a+rwx /etc/hosts
sudo chmod a+rwx /etc/hostname
?
2 修改各台主机的主机名:
Vi /etc/hostname
3 3台主机分别更新: sudo apt-get update
3台主机分别关闭防火墙:sudo ufw disable
(将hadoop用户添加root权限: sudo gpasswd -a hadoop root )
给hadoop用户设置无密码sudo权限:
Chmod u+w /etc/sudoers
编辑增加:
Hadoop ALL=(root)NOPASSWD:ALL
Chmod u-w /etc/sudoers
测试是否成功:sudo ifconfig
?
4 配置jdk
在3台:在/usr目录下新建setup目录,用于安装jdk和hadoop
解压jdk到setup目录
加压到指定目录: tar zxvf 源文件 –C 指定目录
tar zxvf jdk1.x---
重命名为jdk1.7 : mv jdk-1.7.x/ jdk1.7/
?
配置jdk的环境变量:
gedit /etc/profile
?
添加:红色部分为自己的jdk目录
#set Java environment
JAVA_HOME=/usr/setup/jdk1.7
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH JAVA_HOME CLASSPATH
?
验证:Java -version
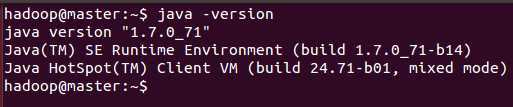
Jdk配置完毕。(这一步完成后可以复制虚拟机)复制后注意配置主机名。
"公私钥"认证方式简单的解释:首先在客户端上创建一对公私钥 (公钥文件:~/.ssh/id_rsa.pub; 私钥文件:~/.ssh/id_rsa)。然后把公钥放到服务器上(~/.ssh/authorized_keys), 自己保留好私钥.在使用ssh登录时,ssh程序会发送私钥去和服务器上的公钥做匹配.如果匹配成功就可以登录了。
1 安装ssh:
3台主机分别:sudo apt-get install ssh
然后 :ssh-keygen -t rsa
一直回车 选择是选 y
?
回到master主机上,使用跨主机的管道和重定向将slave1,slave2主机上的公钥id_rsa.pub添加到????master上的authorized_keys文件中。
?
三台主机上分别:
cd ~/.ssh/
cat id_rsa.pub >authorized_keys
?

?
在master上:ssh slave1 cat ~/.ssh/id_rsa.pub && ssh slave2 cat ~/.ssh/id_rsa.pub
添加到
authorized_keys,
然后复制authorized_keys到slave1 和slave2中:
????scp authorized_keys hadoop@slave1:~/.ssh/
????scp authorized_keys hadoop@slave2:~/.ssh/
?
(或者 :在master上执行:
$cat?~/.ssh/id_rsa.pub |?ssh?远程用户名@远程服务器ip?‘cat >> ????????~/.ssh/authorized_keys‘
)
测试:ssh slave1
Ssh slave2
第一次需要密码,后续ssh时可以实现无密码登陆。
1 下载hadoop,http://apache.fayea.com/apache-mirror/hadoop/common/
选择hadoop-2.2.0.tar.gz
32位环境下不用编译。复制到setup目录(这部分看个人习惯)解压
????tar zxvf hadoop-2.2.0.tar.gz
????mv hadoop-2.2.0 hadoop
2 配置hadoop的环境变量
????vi /etc/profile
????添加如下内容:
# set java environment
export JAVA_HOME=/usr/setup/jdk1.7
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
?
?
?
# set Hadoop environment
export HADOOP_PREFIX="/usr/setup/hadoop"
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
?
使环境变量生效
$source /etc/profile
?
3 编辑?<HADOOP_HOME>/etc/hadoop/hadoop-env.sh 指定java路径
????修改JAVA_HOME的配置:
????export?JAVA_HOME=/usr/setup/jdk1.7
?
4 编辑?<HADOOP_HOME>/etc/hadoop/yarn-env.sh
????修改JAVA_HOME的配置:
????export?JAVA_HOME=/usr/setup/jdk1.7
?
5编辑??<HADOOP_HOME>/etc/hadoop/core-site.xml
<property> ????????<name>fs.defaultFS</name> ????????<value>hdfs://master:9000</value> //指定主机和端口号,master可以改成主机ip当然 ????<description>The name of the default file system.</description> </property> <property> ????????<name>hadoop.tmp.dir</name> ????????<!-- 注意创建相关的目录结构 --> ????????????<value>/usr/setup/hadoop/temp</value> ????????<description>A base for other temporary ????????directories.</description> </property> //创建临时文件目录,在hadoop目录下新建temp目录 |
?
6 编辑<HADOOP_HOME>/etc/hadoop/hdfs-site.xml
<configuration> <property> ????<name>dfs.replication</name> ???????? <!-- 值需要与实际的DataNode节点数要一致,本文为2 --> ????<value>2</value> </property> <property> ????<name>dfs.namenode.name.dir</name> ????<!-- 注意创建相关的目录结构 --> ????<value>file:/usr/setup/hadoop/dfs/name</value> ????<final>true</final> </property> <property> ???????? <name>dfs.datanode.data.dir</name> ???? ????<!-- 注意创建相关的目录结构 --> ???????? <value>file:/usr/setup/hadoop/dfs/data</value> </property> </configuration> ? //hadoop根目录下新建dfs目录,在dfs下新建data和name目录 |
?
7编辑<HADOOP_HOME>/etc/hadoop/yarn-site.xml
<configuration> ? <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> ????<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!-- resourcemanager hostname或ip地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> </configuration> //三台机器上配置是一样的 |
?
8编辑?<HADOOP_HOME/etc/hadoop/mapred-site.xml
默认没有mapred-site.xml文件,copy ?mapred-site.xml.template 一份为?mapred-site.xml即可 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <final>true</final> </property> ? </configuration> |
?
9编辑?<HADOOP_HOME>/etc/hadoop/slaves
添加:
slave1 slave2 |
?
配置好hadoop后 可以通过scp –r hadoop hadoop@IP 复制hadoop这个目录到指定节点上
1????启动Hadoop
1.1、第一次启动需要在master执行format?:hdfs namenode -format?
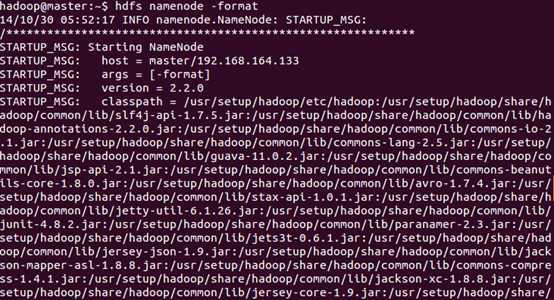
?
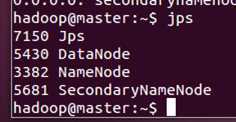
在master验证启动进程:
????????[hadoop@master ~]$ jps
????????
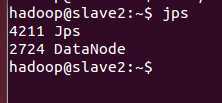
在slavex验证 启动进程:
????????hadoop@slave1 ~$ jps????
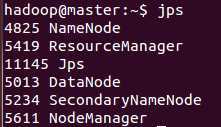
1.3、在Master.Hadoop?执行?start-yarn.sh?
在master验证启动进程:
????????
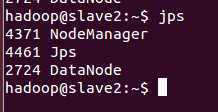
在slavex验证 启动进程:
????hadoop@slave1 ~$ jps
?
????
2 演示
(这部分参考http://www.micmiu.com/bigdata/hadoop/hadoop2x-cluster-setup/)
?
2.1 演示hdfs 一些常用命令,为wordcount演示做准备
????hdfs dfs -ls?/
????hdfs dfs -mkdir?/user
????hdfs dfs -mkdir?-p /user/test/wordcount/in
????hdfs dfs -ls?/user/test/wordcount
?
2.2、本地(即home/下面)创建三个文件 test1.txt、test2.txt、test3.txt, 分别写入如下内容:
test1:
hi baixl welcome to hadoop
more see hadoop
test2:
hi baixl welcome to bigdata
more see hadoop
?
test3:
hi baixl welcome to spark
more see hadoop
?
把 test打头的三个文件上传到hdfs:
[hadoop@Master ~]$ hdfs dfs -put test*.txt /user/test/wordcount/in
[hadoop@Master ~]$ hdfs dfs -ls /user/test/wordcount/in
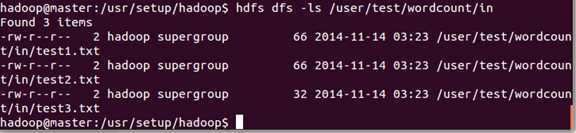
2.3、然后cd 切换到Hadoop的根目录下执行:
????hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.1.jar wordcount ?/user/test/wordcount/in? /user/test/wordcount/out
?
到此 wordcount的job已经执行完成,执行如下命令可以查看刚才job的执行结果:类似如下:
[hadoop@Master hadoop]$ hdfs dfs -ls /user/test/wordcount/out

[hadoop@Master hadoop]$ hdfs dfs -cat /user/test/wordcount/out/part-r-00000
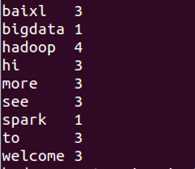
?
?
注意:当重启hdfs后需要删除hdfs上缓存的文件
?
安装过程中由于已经在hdfs上上传了文件,当重启在 hdfs namenode –format时,后,会提示无法上传文件,此时需要删除hdfs已经存在的副本:
在master上删除dfs上name目录下的current目录: rm –rf current/
在slave上删除dfs上的整个data目录 :rm –rf data/
vmware10上三台虚拟机的Hadoop2.5.1集群搭建
标签:des style blog http io ar color os 使用
原文地址:http://www.cnblogs.com/baixl/p/4158499.html