标签:style blog http io ar os 使用 sp for
参考文档:
http://www.tuicool.com/articles/yIZrQ3
http://woodpecker.org.cn/diveintopython3/files.html
http://www.cnblogs.com/txw1958/archive/2012/07/19/2598885.html
http://eli.thegreenplace.net/2012/01/30/the-bytesstr-dichotomy-in-python-3/
1、Pyhthon编码由来
最近在用python写多语言的一个插件时,涉及到python3.x中的unicode和编码操作,本文就是针对编码问题研究的汇总,目前已开源至 github 。以下内容来自项目中的README。
1 ASCII、UNICODE、GBK、CP936、MSCS
1.1 ASCII
美国信息交换标准码。 在计算机的存储单元中,一个ASCII码值占一个字节(8个二进制位),但其最高位(b7)用作奇偶校验位。ASCII(American Standard Code for Information Interchange),是一种单字节的编码。计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制符号。不过ASCII只用到了其中的一半(\x80以下),这也是MBCS得以实现的基础。
1.2 ISO8859-1、EASCII
EASCII是ASCII的扩充,把第八位也用来存储信息;在Windows中用Alt+小键盘数字输入的就是EASCII码对应字符。ISO8859-1就是EASCII最典型的实现,基本能够覆盖西欧的拉丁字母,所以又叫Latin-1。有些国外程序就要求使用ISO8859-1编码以保证Binary Safe,比如著名的XMB。
1.3 Unicode、UTF-8
Unicode是业界的一种标准,它可以使电脑得以呈现世界上数十种文字的系统。 后来,有人开始觉得太多编码导致世界变得过于复杂了,让人脑袋疼,于是大家坐在一起拍脑袋想出来一个方法:所有语言的字符都用同一种字符集来表示,这就是Unicode。
最初的Unicode标准UCS-2使用两个字节表示一个字符,所以你常常可以听到Unicode使用两个字节表示一个字符的说法。但过了不久有人觉得256*256太少了,还是不够用,于是出现了UCS-4标准,它使用4个字节表示一个字符,不过我们用的最多的仍然是UCS-2。
UCS(Unicode Character Set)还仅仅是字符对应码位的一张表而已,比如"汉"这个字的码位是6C49。字符具体如何传输和储存则是由UTF(UCS Transformation Format)来负责。
一开始这事很简单,直接使用UCS的码位来保存,这就是UTF-16,比如,"汉"直接使用\x6C\x49保存(UTF-16-BE),或是倒过来使用\x49\x6C保存(UTF-16-LE)。但用着用着美国人觉得自己吃了大亏,以前英文字母只需要一个字节就能保存了,现在大锅饭一吃变成了两个字节,空间消耗大了一倍……于是UTF-8横空出世。
UTF-8是一种很别扭的编码,具体表现在他是变长的,并且兼容ASCII,ASCII字符使用1字节表示。然而这里省了的必定是从别的地方抠出来的,你肯定也听说过UTF-8里中文字符使用3个字节来保存吧?4个字节保存的字符更是在泪奔……(具体UCS-2是怎么变成UTF-8的请自行搜索) Unicode的实现方式不同于编码方式,一个字符的Unicode编码是确定的,但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。于是就有了UTF-8、UTF-16、UTF-32。
UTF-8使用一至四个字节为每个字符编码:
ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母(即以ISO 8859为主的)则需要二个字节编码(Unicode范围由U+0080至U+07FF)。其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,包括汉字)使用三个字节编码。其他极少使用的Unicode 辅助平面的字符使用四字节编码。它唯一的好处在于兼容ASCII。 UTF-16则是以U+10000为分界线,使用两个字节或者四个字节存储。 UTF-32则是全部使用4字节编码,很浪费空间。
1.4 GB2312、GBK、GB18030
GB是中国荒谬的国家标准。GB2312、GBK、GB18030各为前一个的扩展。
我从来讨厌GB编码,因为它毫无国际兼容性。更荒谬的是,GBK和GB18030几乎是照着Unicode字符集选取的字库。这样多此一举地弄出一套编码,还强制所有在中国销售的操作系统必须使用它,真是天朝特色。
另外,对于GB编码PHP是不认账的,mb_detect_encoding函数会把GB编码识别成CP936。
1.5 MSCS
然而计算机世界里很快就有了其他语言,单字节的ASCII已无法满足需求。后来每个语言就制定了一套自己的编码,由于单字节能表示的字符太少,而且同时也需要与ASCII编码保持兼容,所以这些编码纷纷使用了多字节来表示字符,如GBxxx、BIGxxx等等,他们的规则是,如果第一个字节是\x80以下,则仍然表示ASCII字符;而如果是\x80以上,则跟下一个字节一起(共两个字节)表示一个字符,然后跳过下一个字节,继续往下判断。
这里,IBM发明了一个叫Code Page的概念,将这些编码都收入囊中并分配页码,GBK是第936页,也就是CP936。所以,也可以使用CP936表示GBK。
MBCS(Multi-Byte Character Set)是这些编码的统称。目前为止大家都是用了双字节,所以有时候也叫做DBCS(Double-Byte Character Set)。必须明确的是,MBCS并不是某一种特定的编码,Windows里根据你设定的区域不同,MBCS指代不同的编码,而Linux里无法使用MBCS作为编码。在Windows中你看不到MBCS这几个字符,因为微软为了更加洋气,使用了ANSI来吓唬人,记事本的另存为对话框里编码ANSI就是MBCS。同时,在简体中文Windows默认的区域设定里,指代GBK。
open状态rb对应的是_io.BufferedReader,r对应的是_io.TextIOWrapper
class io.TextIOWrapper(buffer, encoding=None, errors=None, newline=None, line_buffering=False)
A buffered text stream over a BufferedIOBase binary stream. It inherits TextIOBase. encoding gives the name of the encoding that the stream will be decoded or encoded with. It defaults to locale.getpreferredencoding().
2 encode和decode方法
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312‘),表示将gb2312编码的字符串str1转换成unicode编码。 encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312‘),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码。代码中字符串的默认编码与代码文件本身的编码一致。
如:s=‘中文‘ 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这 种情况下,要进行编码转换,都需要先用decode方法将其转换成unicode编码,再使用encode方法将 其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件
2、文件是由字符串组成的,当文件存入计算机中时,是需要把字符串转变成字节序列,这个过程叫字符编码的过程。当文件内容从计算机中打印到屏幕上时,又需要把字节序列转化成字符串的形式,这个过程叫字符解码。
Instance1:
以下是淘宝网页html的部分源码,从html头部得知,charset="gbk",则说明要求计算机将字符串以gbk方式编码成字节序列存在在计算机中,因次:
实验一:(对字节编码进行解码:utf-8方式解码)
import os
import urllib.request
resp = urllib.request.urlopen(‘http://nanren.taobao.com/?spm=1.7274553.1997517385.d1.iDaj5y‘)
s = resp.read()
s1 = s.decode(‘utf-8‘)
print(s1)
错误:UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xcc in position 179: invalid continuation byte
实验二:(对字节编码进行解码:gbk方式解码)
import os
import urllib.request
resp = urllib.request.urlopen(‘http://nanren.taobao.com/?spm=1.7274553.1997517385.d1.iDaj5y‘)
s = resp.read()
s1 = s.decode(‘gbk‘)
print(s1)
html源码:
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="spm-id" content="a2193.7381025">
<title>淘宝男人</title>
<!-- 公共资源引用 -->
<!--761868-->
<!-- S GLOBAL CSS -->
<link rel="stylesheet" href="http://g.tbcdn.cn/tb/global/3.3.14/global-min.css">
<!-- E GLOBAL CSS --><!-- S GLOBAL JS -->
<script src="http://g.tbcdn.cn/??kissy/k/1.4.2/seed-min.js,tb/global/3.3.14/global-min.js"></script>
<!-- E GLOBAL JS --> <link rel="stylesheet" href="http://g.tbcdn.cn/??tbc/market/0.3.0/index-min.css?t=20140418.css">
<script src="http://g.tbcdn.cn/tbc/market/1.2.6/index-min.js"></script> <style>
.site-nav .site-nav-bd {
width: 1190px;
}
.w990 .site-nav .site-nav-bd {
width: 990px;
}
</style>
<link rel="stylesheet" href="http://g.tbcdn.cn/tb/press/2.2.2/layouts/1190-119-10-0.css" />
Instance2:
字节即字节;字符是一种抽象。字符串由使用Unicode编码的字符序列构成。但是磁盘上的文件不是Unicode编码的字符序列。文件是字节序列。所以你可能会想,如果从磁盘上读取一个“文本文件”,Python是怎样把那个字节序列转化为字符序列的呢?实际上,它是根据特定的字符解码算法来解释这些字节序列,然后返回一串使用Unicode编码的字符(或者也称为字符串)。
# This example was created on Windows. Other platforms may
# behave differently, for reasons outlined below.
# 这个样例在Windows平台上创建。其他平台可能会有不同的表现,理由描述在下边
>>> file = open(‘examples/chinese.txt‘)
>>> a_string = file.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python31\lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: ‘charmap‘ codec can‘t decode byte 0x8f in position 28: character maps to <undefined>>>>
默认的编码方式是平台相关的。
刚才发生了什么?由于你没有指定字符编码的方式,所以Python被迫使用默认的编码。那么默认的编码方式是什么呢?如果你仔细看了跟踪信息(traceback),错误出现在cp1252.py,这意味着Python此时正在使用CP-1252作为默认的编码方式。(在运行微软视窗操作系统的机器上,CP-1252是一种常用的编码方式。)CP-1252的字符集不支持这个文件上的字符编码,所以它以这个可恶的UnicodeDecodeError错误读取失败。
即:fd = open(“c:\test.text”,’r’,encoding= ‘utf-8’) 告诉系统,test.txt文本是以utf-8方式编码的,故系统就会知道以utf-8方式解码
3.总结
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。这是件好事。
不管怎样,字符串和字节包之间的界线是必然的,下面的图解非常重要,务请牢记于心:
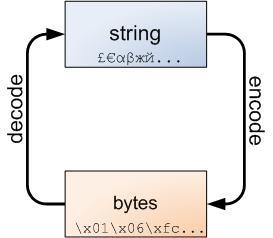
字符串可以编码成字节包,而字节包可以解码成字符串。
标签:style blog http io ar os 使用 sp for
原文地址:http://my.oschina.net/lcxidian/blog/355831