标签:style blog http io ar color os 使用 sp
在大型系统开发调试中,跨系统之间联调开始变得不好使了。莫名其妙一个错误爆出来了,日志虽然有记录,但到底是哪里出问题了呢?
是ios端参数传的不对?还是A系统或B系统提供的接口导致?相信大家碰到不少,大多数问题不大,但排查起来比较费劲。
下面,我们来具体看下实现。
1:概述
2:web环境
3:多线程环境
4:异步环境
5:性能,大数据量,隐私安全
6:总结
一句话总结:通过一个TraceId把整个请求,形成一个调用链。
这样无论任何地方报错,只要拿TraceId去系统查下,根据上下文就知道是哪一步,哪个函数,哪个参数出错了,能以最快速度处理。
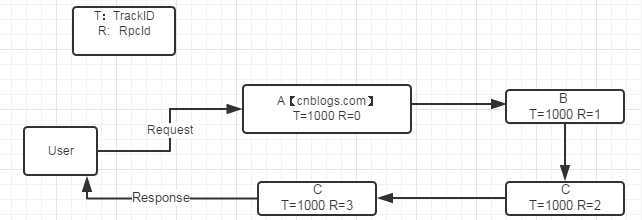
如图:以博客园为例。当博客园收到一个请求后,自动为生产个唯一ID 1000,之后所有处理工作都是用这个1000。
每个处理模块都维持一个上下文ID自增,rpcid++。
处理模块可以是函数级,逻辑层级,服务器级等都可以。
一旦发现有异常后,自动将TraceId发给博客园。这样程序员们,就能根据TraceId最快定位问题了。
我们来看下具体怎么实现。
我们定义跟踪日志需要的参数,进行上下文传递。
public class LogBody
{
/// <summary>
/// 跟踪ID
/// </summary>
public string TraceId { get; set; }
/// <summary>
/// 上下文ID
/// </summary>
public int RpcId { get; set; }
/// <summary>
/// 处理时间
/// </summary>
public DateTime LastTime { get; set; }
}
我们这global.asax,利用HttpContext.Current上下文。开始埋点(跟踪),rpc 0。
void Application_BeginRequest(object sender, EventArgs e)
{
var lb = new LogBody();
lb.TraceId = Guid.NewGuid().ToString("N");
lb.RpcId=0;
lb.LastTime = DateTime.Now;
HttpContext.Current.Response.AppendHeader("traceID", lb.TraceId);
HttpContext.Current.Items.Add(lb.TraceId, lb);
//记录日志,例:用户请求参数,userAgent等。
}
在default页开始业务逻辑,rpc 1。
protected void Page_Load(object sender, EventArgs e)
{
var traceID = HttpContext.Current.Response.Headers["traceID"];
LogBody logbody = HttpContext.Current.Items[traceID] as LogBody;
logbody.RpcId++;
logbody.LastTime = DateTime.Now;
//业务逻辑。
//记录日志。。。
}
如上我们就完成上下文的传递。
Application_BeginRequest 中在实际使用中,我们只需要对有用的页面(例:aspx,ashx)进行埋点。
日志记录的时候,可以把logbody都存储起来。
LastTime这个字段,我们可以与上一次的相减。这样就得出中间逻辑处理所需时间了。
在web程序中我们可以用http服务器的上下文传递。在单线程的程序中,我们按照线性顺序即可。
多线程中我们可以用threadlocal传递。
public static ThreadLocal<LogBody> Body = new ThreadLocal<LogBody>();
static void Main(string[] args)
{
var t1 = new Thread(() =>
{
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = 0,
TraceId = Guid.NewGuid().ToString("N")
};
//业务1
Console.WriteLine("Thread1 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
Thread.Sleep(5000);
Body.Value.RpcId++;
Body.Value.LastTime = DateTime.Now;
//业务2
Console.WriteLine("Thread1 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t1.Start();
var t2 = new Thread(() =>
{
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = 0,
TraceId = Guid.NewGuid().ToString("N")
};
//业务1
Console.WriteLine("Thread2 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
Thread.Sleep(5000);
Body.Value.RpcId++;
Body.Value.LastTime = DateTime.Now;
//业务2
Console.WriteLine("Thread2 log record:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t2.Start();
}
运行如下:

往往在生产环境中,会有大量的异步操作。如果有异步行为的话,打乱我们的上下文怎么办?这时候我们引入另外一个概念,父节点Id。
这样异步操作的行为,就父节点之下。 最终在日志后台展示,我们看到的是倒着的树形结构。
如图,我们看到业务2异步派生出来的子节点。
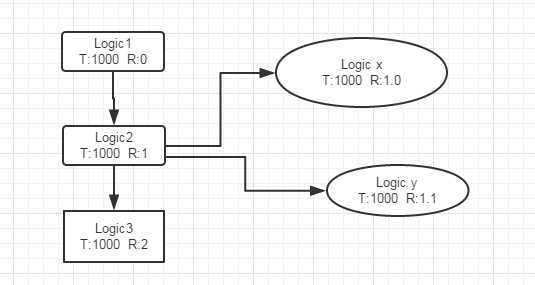
我们把上下文rpcid修改成double类型。
static void Main(string[] args)
{
var t2 = new Thread(() =>
{
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = 1,
TraceId = Guid.NewGuid().ToString("N")
};
var t1 = new Thread((lb) =>
{
var temp = lb as LogBody;
Body.Value = new LogBody()
{
LastTime = DateTime.Now,
RpcId = temp.RpcId,
TraceId = temp.TraceId
};
Body.Value.RpcId += 0.1;
//业务x
Console.WriteLine("async Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime );
Thread.Sleep(5000);
Body.Value.RpcId+=0.1;
Body.Value.LastTime = DateTime.Now;
//业务y
Console.WriteLine("async Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t1.Start(Body.Value);
//业务1
Console.WriteLine("sync Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
Thread.Sleep(2000);
Body.Value.RpcId+=1;
Body.Value.LastTime = DateTime.Now;
//业务2
Console.WriteLine("sync Thread:" + Body.Value.TraceId + "-" + Body.Value.RpcId + "-" + Body.Value.LastTime);
});
t2.Start();
}
代码中我们用参数传递给了异步线程中。运行如下:

关于性能
从代码中,我们发现。这种方式对程序性能影响可以忽略不计。
需要注意是:如果在生产环境跑的话,不论你是写文件,还是数据库,或写统一日志平台。都会导致大量IO读写,网络资源消耗。
如果服务器都消耗这上面,都得不偿失了。
我们可以用内存队列+队列+批量push或pull的方式。并且注意设置阀值。
关于大数据量
大量的请求,其实多数是无效的。这里引入采样率的概念。 例如按求余取,或者按地区,时间等。也可以自己写采样规则。
日志可以只记录error以上的级别,只有在排查生产环境的时候才开启debug,info级别信息。
存储这块,可以根据实际需要选择sql server,mongodb,hbase hdfs。
关于隐私安全
如果有敏感数据,建议根据进行加密。
本文是基于Google dapper论文的思路展开。大家基于此进行扩展。
示例中,都是手动记录。在实际使用中,是可以简化调用的。 当然也封装成自动构建的,大家可以看前2篇的自动注入。
1:Google dapper论文
2:淘宝EagleEye系统
作者:蘑菇先生
出处:http://www.cnblogs.com/mushroom/p/4156468.html
 本文品基于知识共享署名 2.5 中国大陆欢迎转载,演绎或用于商业目的,但是必须保留本文的署名蘑菇先生(包含链接)。
本文品基于知识共享署名 2.5 中国大陆欢迎转载,演绎或用于商业目的,但是必须保留本文的署名蘑菇先生(包含链接)。
标签:style blog http io ar color os 使用 sp
原文地址:http://www.cnblogs.com/mushroom/p/4156468.html